
2026年1月11日に python3エンジニア認定基礎試験を受験し合格することができました。AIのGeminiを活用し、自分なりの学習手順で合格をすることができました。世間では簡単な試験だと言われていますが、しっかりとした対策をしないと確実に合格をすることは難しいと思いました。本記事では合格への軌跡を記したいと思います。
この試験は明確な出題範囲が定められているため、戦略的な対策をとることによって合格を確実に狙うことができます。しかし結局は下記のチュートリアルの大事な箇所を理解していないと点数が取れない試験になっています。
公式サイトによると出題は下記の公式参考書『Pythonチュートリアル 第4版』の全14章からの基礎文法部分から出題されると明言されております。

試験は40問出題されて28点以上で合格です。公式サイトにはどの章が何問出題されるかの記述があり、出題数が多い章をしっかりと理解しておくことはかなり大事です。下記に内容をまとめておきます。
| 4章 制御構造ツール | 9 |
| 5章 データ構造 | 7 |
| 3章 気楽な入門編 | 6 |
| 8章 エラーと例外 | 4 |
| 10章 標準ライブラリめぐり | 4 |
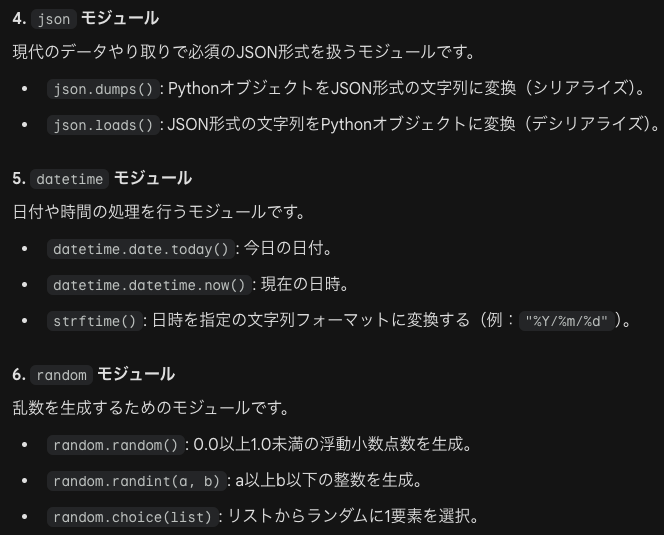
| 6章 モジュール | 2 |
| 9章 クラス | 2 |
| 1章 食欲をそそってみようか | 1 |
| 2章 Pythonインタープリタの使い方 | 1 |
| 7章 入出力 | 1 |
| 11章 標準ライブラリめぐり─PartII | 1 |
| 12章 仮想環境とパッケージ | 1 |
| 14章 対話環境での入力行編集とヒストリ置換 | 1 |
| 13章 次はなに? | 0 |
太字の部分だけで30点/40点が取れることがわかります。しかし難易度の高い問題が混じっている可能性が高く、出題数が1問の章もしっかりと抑えておくと安心です。
合格者の体験記などを読むと、このチュートリアルはPython初心者の自分のような人には敷居が高いそうです。そのためまずは下記の黒本『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』でザッと雰囲気を掴んだ後で『Pythonチュートリアル 第4版』を読んで、最後に模擬試験でしっかりと穴を無くして本番に立ち向かおうと思います。
試験前日で黒本の復習を終えたところですが、クラスの章など、難しい章も黒本に出ている内容はしっかり把握しておくことが大事だと思いました。なぜならそれらの内容が基となっている問題が模試で何問か見受けられたためです。
Python3の黒本の学習

まずは黒本から学習します。後述する公式教材との章は必ずしも合ってはいません。そのため黒本は上の表にある出題数が1や2の範囲を1周目では除いて順に学習していきましょう。
pythonの特徴
Pythonはコンパイルを不要としインタープリタを行います。ブロック構造はインデントを用います。また他のプログラミング言語で書かれたプログラムを用いた拡張機能があります。
対話モードではバージョン番号、ヘルプなどのコマンド、一次プロンプト(>>>)、二次プロンプト(…)の順で表示されます。
文字コードはUTF-8です。それ以外だと文字コードを指定する必要があります。# _*_ coding: 文字コード _*_で文字コードを指定します。
推奨されるコーディングスタイルはコメントは独立した行で書く、ソースコード幅が79文字を超えないよう折り返す、インデントはタブを使わず空白4つを使用します。このようなスタイルガイドはPEP 8と言われます。これはPython Enhancement Proposalsの8番目という意味です。
文字列の記述ではシングルクォート〜トリプルクォートまで使用可能ですが、左右のクォートが異なることは禁止です。
Pythonが自動的に作成するファイルである対話モードでの入力履歴は.python_historyという名称です。入力履歴は対話モードでカーソルの上または下を押すと表示されます。またTabキーを押すと補完機能を呼び出せます。
テキストと数の操作
除算の結果は浮動小数点数になることに注意しましょう。
文字列リテラルはシングルクォート、ダブルクォートで囲まれた値です。
Pythonの文字列では改行は次の改行文字(\n)で表され1文字として扱われます。
トリプルクォートを使うとリテラル(直接書き込まれた固定された値)中の改行が改行文字として反映されます。
文字列スライスにおいて負数で指定する文字列スライスの場合は右端の文字の右側が0で左に向かって順に-1,-2,…と文字が小さくなります。b,d,x,f,%はそれぞれ値を2,10,16進数で表す、値を与えられた精度までの小数で出力する、値を100倍士パーセント記号がついた形式で出力します。例えば7dは右寄せ7桁幅で「 15000」などと表示されます。
format( )メソッドは文字列の詳細なフォーマットを行うメソッドです。処理の対象は{}で囲まれたフォーマットフィールドを含む文字列です。”文字列{Field1}{Field2}{Field3}…".format(値1,値2,値3…)がformat()メソッドの記述法です。
フォーマットフィールドには0,1,2などを入れてもOKです。また空欄でもOKです。
フォーマットフィールドにはformat()メソッドに与えた引数の変数名は直接記述できません。KeyErrorが発生します。
リストの操作
リストの先頭の要素は0です。また最後の要素を-1とする数え方もあります。.append(値)=リスト名+=[値]です。
リストにない要素をデータに追加しようとするとTypeErrorとなります。
入れ子(ネスト)構造は、[リスト1,リスト2,リスト3]などです。例えばdata[i][j]とはi番目のブロックの中のリストのj番目の数という意味です。
スタックは末尾に要素を追加して末尾からとるLIFO型のデータ構造です。追加と削除はそれぞれappend()とpop()で対応します。例えば空データにdata.pop( )などとするとIndexErrorとなります。pop(0)は先頭の要素を削除するという意味で一般化可能です。
キューは末尾に要素を追加して先頭の要素を削除する構造です。
リストの角括弧[]内でforを使って記述したものをリスト内包といいます。リスト内包を使うとfor文による複合的な処理を1つの簡潔な式で表現できます。

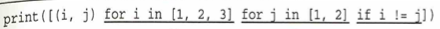
判定と繰り返し
短絡演算子とは、不要な評価を省略して短絡する演算子です。A and Bについては、Aの判定が偽のときBの結果を待たずにAの判定評価を返します。Aの判定が真であればBを評価しその評価結果を返します。A or Bについても同様の考えです。num(整数)を評価すると引数の整数を返します。その整数の真偽の判定は0が偽、それ以外が真です。if value is Noneが正しいです。
range()関数は、range(start,stop,step)で考えます。range(4)=[0,1,2,3]で、range(0,4)=[0,1,2,3]で、range(1,4)=[1,2,3]で、range(1,8,2)=[1,3,5,7]と同じ意味です。とにかく最後の文字は未満という意味なので含みません。
SyntaxErrorは構文に問題がある場合に発生するエラーです。
ディクショナリのitem()メソッドについて、data.items()という表記でキーと値を同時に取得できます。
enumerate()関数は、for文と組み合わせて、リストや文字列などの反復可能体(for文による繰り返しが可能なもの)からインデックスと要素を同時に取得できます。

sorted()関数を用いて反復可能体から昇順にソートしたリストを取得できます。reversed()関数は逆順にしたオブジェクトを取得できます。
zip()関数は複数の反復可能体から並列で要素を取得できます。

文字列のn倍は文字列をn個並べたものになります。
関数
山場です。基本情報技術者試験の時のような疑似言語とは異なり、Python特有の関数の定義を覚えていないと解けない問題です。特にconcatの問題(リストやタプルとして与えられた引数に関する問題)がとても理解しづらいです。
難しいですが、ここはしっかりと理解して得点できるようにしたいですね!

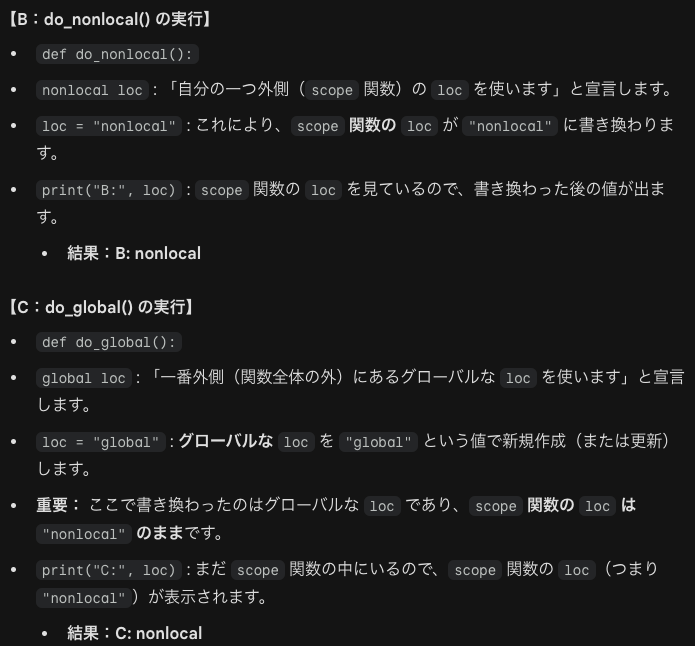
関数の外側で定義されたグローバル変数に値を代入するときはglobal文を用います。関数内で定義される変数(ローカル変数)は関数の外側では参照できません。このときNameErrorが発生します。つまり関数の内側と外側では変数のスコープが異なります。
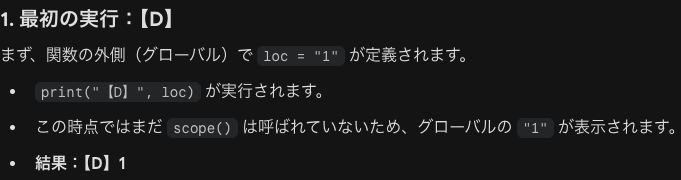
例えばグローバル変数でx=100と定義してその後にローカル変数でx=200と定義してxを出力してもグローバル変数の100が出力されます。一方でローカル変数でglobal()でxを再定義した場合は出力は上書きされた200が出されます。またローカル変数でデフォルト値を設定した後でその変数を再定義しても関数内のローカル変数は変わりません。
キーワード引数とは、キーワード=値の形式で与える引数です。
キーワード引数は位置引数の後にないといけません。つまり位置引数、キーワード引数です。
存在しないキーワード引数が与えられたらTypeErrorが発生します。
引数のデフォルト値は関数が定義された時点で評価され、関数の実行時に再評価は行われません。

第2引数のデフォルト値がリストです。第2引数が指定されている場合は、第2引数のリストに第1引数(number)の値を加えます。第2引数が指定されていない場合は、default_arg_listのデフォルト値に第1引数(number)の値を加えます。

しかし実務では引数のデフォルト値をリストにすることは避けるべきです。
引数をタプルやディクショナリとして参照する方法(アンパック)について、*が先頭についた仮引数(関数に定義する引数)は指定済みの実引数(関数を呼び出す際に指定する引数)を除く位置引数のタプルが入ります。**が先頭についた仮引数には、指定済みの実引数を除くキーワード引数のディクショナリが入ります。

docstringはクラスや関数を説明するためのコメントです。

doctstingは__doc__という属性で参照できます。
その他のコレクションの操作
collections.dequeはキューのように使えるデータ構造です。append(要素)とpopleft()で行います。取り出すときは必ず左側から取り出します。また両端キューという種類のキューでもあります。先頭に要素を追加する場合はappendleft()メソッドを用います。末尾から要素を取り出す場合はpop()メソッドを用います。
tuple()関数は、その引数はリストなどの反復可能体である必要があるため、カンマ区切りの要素はそのままでは引数として使えません。要素が1つの場合でも最後に,をつけます。()を入れても省略してもOKです。
リストとタプルは異なるデータ型の要素を格納できます。リストは既に存在する要素の値を変更できますが、タプルはこうした変更ができません。タプルは定義後は後から要素の追加はできません。
ディクショナリはタプルや数値もキーとして使用できますが、リストはディクショナリのキーに指定できません。キーにできるのは不変体の値のみです。
値 in ディクショナリ のようにin演算子でキーの存在を確認できます。key()メソッドの返り値にin演算子を用いても良いです。ディクショナリのメソッドにincludes()はありません。
ディクショナリを1行だけで作成する方法を内包表記といいます。

モジュール
覚えることが多い割に2問しか出題されないため学習面では後回しが吉です。
ファイル入出力
出題数が1問でありページ数が多いため後回しにすべきです。
例外処理
SyntaxErrorは構文エラーです。たとえば文字列定義の先端と末尾のクォートが一致していないときに起きます。
コードが文法として正しい場合でも実行時に起きるエラーを例外(exception)といいます。引数のデータ型が誤っていたり、存在しない名前の変数を参照したりしたときに起きます。このときPythonはエラーメッセージを表示して動作を停止します。例外を検知して発生時の動作を実装するにはtyr-exception文を使います。例えばint()関数にint型に変換できない値があるとValueError(データ型が合っていても値が不適切)という例外が発生します。またディクショナリに存在しないデータを参照しようとするとKeyErrorという例外が発生します。NameErrorは未定義の変数(または関数)を使用すると発生するエラーです。except節で複数の例外を処理するには()内に処理したい例外をすべて列挙します。


例外を送出するときにraise文を使うと任意の例外を発生させることができます。

try文にfinally節を追加することによってクリーンアップ動作(例外発生の有無によらず実行する処理)を定義できます。


上の例のように”0”で割るのはデータ型が対応していないのでTypeErrorです。意図しないデータ型が与えられたりしたときにも発生します。対してValueErrorは意図しない値が与えられた場合に発生します。int("ABCD")ならValueErrorが発生します。
この2つは似ていて紛らわしいので数多くの問題にあたってどちらのエラーかの判別ができるようにしておきたいところです。
クラスとオブジェクトの操作
最も暗記すべき量が多い章ですが、2問しか出題されません。後回しです。
標準ライブラリ
単体テストが難所です。
osモジュールにはファイルやディレクトリを操作する関数が定義されています。os.getcwd()でカレントディレクトリを取得し、os.chdir(移動先)でカレントディレクトリを移動します。
glob.glob(パターン)を使うと、ファイル名がパターンにマッチするファイルの一覧を取得できます。ワイルドカードは任意の文字の並びにマッチします。*はワイルドカードを意味します。ただし*は.で始まるファイルには対応しません。
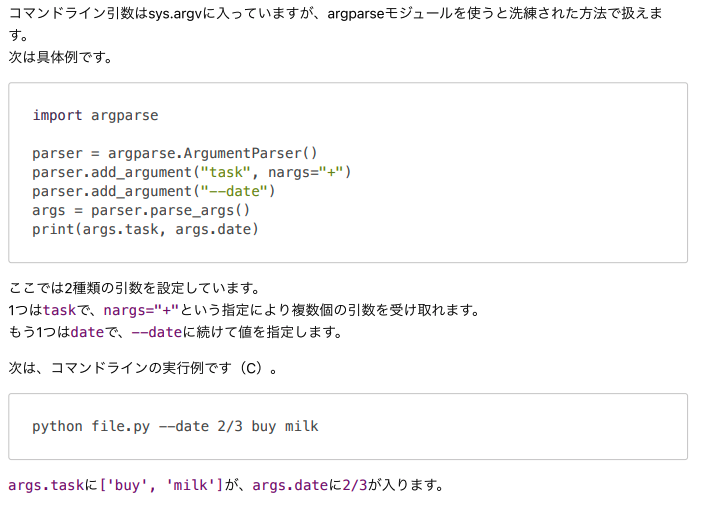
コマンドライン引数は、プログラムの実行時に指定できる特殊な引数です。コマンドライン上でプログラム名の後に続けて入力すると、指定した引数の情報をプログラムに直接渡せます。
コマンドライン引数は、sysモジュールのargv属性を使ってリストで取得できます。
次の問題は難易度が高いです。しかし行っている内容は引数を分けているだけです。その点に注目しながら解説を読んでいきましょう。
argparseモジュールのArgumentParser()を用いた場合でもコマンドライン引数を取得できます。sysモジュールのargv属性よりも扱いやすいコマンドラインのインターフェースを作成できます。


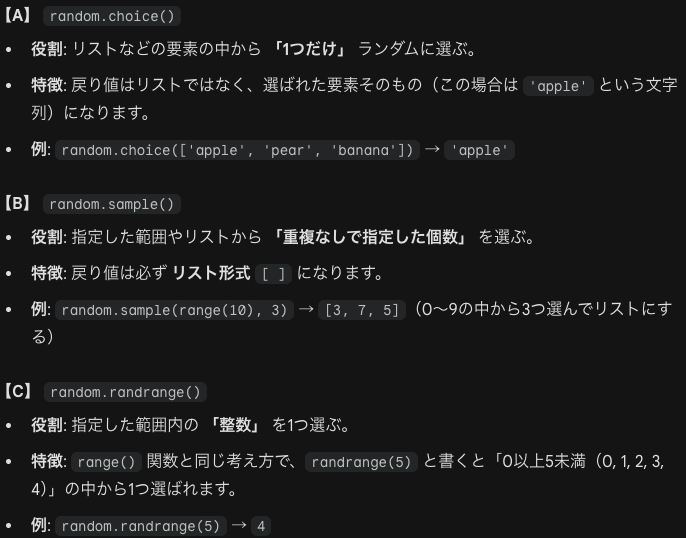
random.choice(range(10))は0~9のうち1個がランダムに選ばれます。対してrandom.choice()は0以上1未満のランダムな値(小数)を返します。分散は不偏分散の意味です。
urllib.requestモジュールのurlopen()関数を使うと、引数で指定したURLのWebサイトからさまざまな情報を取得できます。

urlopen()は組み込み関数のopen()と同じように扱えますが、対象のデータをバイナリモードで取得します。バイナリデータを文字列に変換するためにdecode()関数を用います。
datetimeモジュールは日付と時刻を扱うさまざまな関数が定義されています。

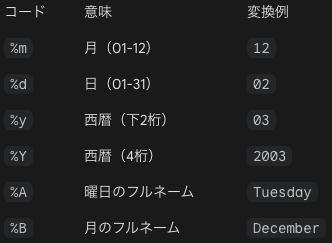
この変数dtを決められた形式の文字列で表示するためにdt.strftime(フォーマット)のように記述します。第1引数のフォーマットには文字列の表示形式を指定します。
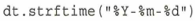
形式を指定する部分は%とアルファベッド1文字で構成されます。%%とした場合は%のみを表示します。
単体テストとは、プログラムに含まれる個々の関数やメソッドに対して動作検証を行うことです。Pythonで単体テストを実行する際は、unittestモジュールを使用します。その際はテスト対象のモジュールとは別に、テスト実行側の.pyファイルを用意する必要があります。下記の例の.tests.pyではcalc()関数に対して単体テストを行っています。

テストの実行結果が期待する結果となっているかの確認は、self.assertEqualを用います。assertEqualは継承元のunittest.TestCaseで定義されます。結果が異なる場合は、どのように異なるかを確認できます。

self.assertEqualの代わりにassertも使えますが、その場合どのように違うかを確認できません。self.assertとすると構文エラーになります。
print関数はリスト型のデータを出力できますが、要素ごとの改行は行いません。pprint()関数は、1行が80文字を超えると要素ごとに改行します。


また次のように出力しても結果は出ますが、角括弧[]はつきません。さらに次の表現でも同様の結果となります。


Python仮想環境とサードパーティパッケージの利用
仮想環境を導入すると複数のPythonの実行環境を目的に応じて使い分けられます。仮想環境に使うバージョンのPythonはあらかじめインストールしておく必要があります。
仮想環境の作成にはvenvモジュールを使います。

複数のPythonがインストール済みの場合にバージョンを指定するときは上記のコマンドのPython3の部分をPython3.14などに変更します。仮想環境に切り替える方法は下記になります。
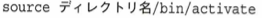
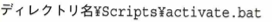
有効化後はいずれのOSでもPythonコマンドでPythonを起動できます。
標準ライブラリに含まれない外部パッケージはpipモジュールを使ってインストールします。

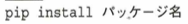
既にインストール済みの場合はバージョンを指定せずにインストールしても最新バージョンがインストールされるわけではありません。
pip showコマンドでパッケージの詳細情報を確認できますが、パッケージ名の指定が必要です。インストール済みのパッケージ一覧を表示するには、pip listを実行します。pip freezeでも同様の結果となります。一般にはこの出力をrequirements.txtというファイルに保存し、pip installの入力に使います。
Pythonチュートリアル第4版
公式本の内容を学習します。学習の効率を上げるため記事の目次前に記述した出題頻度の割合の高い章から集中して学習します。
制御構造ツール→9問
各文
range()はリストではありません。list(range(4))とすると[0,1,2,3]というリストができます。sum(range(4))=0+1+2+3=6です。反復可能体を期待する関数や構造を反復子(iterator)といいます。


continue文はループの残りを飛ばして次の反復に移るためのものです。
pass文は構文的に文が必要ではあるが、プログラム的には何もする必要のない時に用います。
関数の定義
次はいよいよ関数です。次のフィボナッチ数列の例はdocstringを使う例です。

空白が意味するところは、そもそもprint()関数は出力の最後に自動的に改行(\n)を加えるため何も指定しないと数字が1つずつ縦に並んで表示されてしまいます。それを防ぐためにendを入れています。' 'を指定することで、各数字の後にスペースが入り、1行にまとめて表示されます。end=' , 'とすれば数字がカンマ区切りになり、end=''とすれば数字が隙間なくつながって表示されます。
次の例はフィボナッチ数列の要素を表示する代わりに、そのリストを返す関数です。result.append(a)という表記がありますが、この.はresultというリストの中にある機能を使いますよという合図です。


引数の個数が可変の関数を定義することができ、3つの形態があります。
引数のデフォルト値
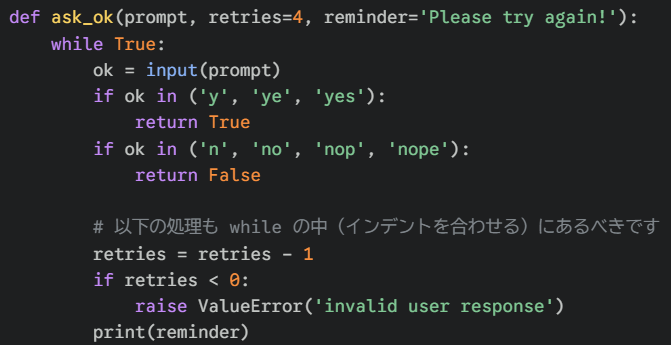
この例では、はい、いいえで答えられない検索がされた場合、検索回数が1ずつ減っていく様子を表しています。検索のチャンスは4回であり、5回目になろうとすると強制的に終了する様子もうかがえます。
ok = input(prompt)で入力を待っている様子もプログラマーという感じですね。
次のように関数を作るときに初期値を決めておくと、「普段はシンプルに使い、必要な時だけ細かくカスタマイズする」 という便利な使い分けができるようになります。例えば上の例におけるask_ofを実際にどうやって呼び出すか(使うか)という呼び出し方を工夫することができます。次の3つの例では下に行くにつれて自分で設定している感が出ます。
ask_ok('Do you really want to quit?') とした場合は質問文(prompt)だけを指定して呼び出します。残りの設定は初期値が使われます。つまり、「最大4回のリトライ」が可能で、失敗時のメッセージは 「Please try again!」 になります。
ask_ok('OK to overwrite the file?', 2) とした場合は質問文に加えて、2番目の設定(retries)を 2に上書きします。この場合、リトライは2回までしか許されません。3回間違えるとエラーになるので、ちょっと厳しめの設定にしたい時に使います。
ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!') とした場合は3つの設定すべてを自分で指定し、リトライは2回まで、さらに間違えた時のメッセージが 「Come on, only yes or no!(おいおい、YesかNoだけで答えてくれ!)」 という独自の文章に変わります。
次にデフォルト値の意味について解説します。

結果が6と表示されず5となる理由の理解が大事です。結果は引数を指定せずに呼び出したので、定義時に固定されたデフォルト値が使われます。定義の段階でi=5ということなので、その段階でargのデフォルトが5と決まってしまいます。関数を呼び出すたびにデフォルト値を計算し直す必要がないため、動作が高速になります。また、外部の変数が後から書き換えられても、関数の初期設定が勝手に変わらないため、予測通りの動きを保てます。
キーワード引数

この例題はオウムの例ですが少々かわいそうな例題です。この関数を呼び出すと、渡されたデータ(電圧、状態、動作、種類)を使って、オウムに関する4行のテキストを表示します。end=' 'のため、指定されたaction(動詞)のあとにスペースが入ります。

しかし無効となるコールがあります。位置引数→キーワード引数の原則はとても大事です。

次の例は複数の値をとることによるTypeErrorが発生します。

最初の位置引数の0を見て、「1番目の引数である aに0を入れよう」と判断します。次にキーワード引数のa=0を見て、「引数 a に0 を入れよう」と判断します。さっき位置引数でaに値を入れたのに、またaに指定が来た!どっちを使えばいいんだ?」と混乱し、エラーを出します。
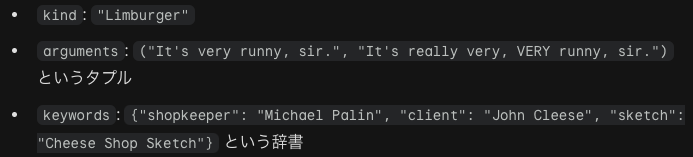
チーズ・ショップの例題があります。

引数の中で、*を1回つけるとタプルを、**となると辞書を表します。次のようなコールをします。

かなり紛らわしいので何を指しているのかをまとめます。
よって出力は以下のようになります。ここでprint("_" *40)はハイフンが40個並んだ線であることに注意しましょう。

特殊引数

/ や*は有っても無くても良いです。どちらも存在しない場合は、引数は位置引数とキーワード引数としても渡すことができます。この原則を無視するとTypeErrorがおきます。

第1の関数の引数は位置引数またはキーワード引数として渡せます。第2の関数は位置引数しか使えず、第3の関数はキーワード引数しか使えず、第4の関数は左から順に、位置引数、位置引数またはキーワード引数、キーワード引数が使えます。

これがエラーが起きる理由は、例えば初めの値をname=1として代入しているのに、次の引数(辞書)で'name'=2として渡そうとすると、nameで値が重複することになりエラーが起きます。このような例でTRUEを出したいときは次のようにします。

位置のみの引数はユーザーに引数名を見せたくないときに使用します。関数の呼び出し時に順序を強制したいときや、いくつかの位置引数と任意個数のキーワード引数を取りたいときに便利です。キーワードのみ引数は引数名に意味があるとき明示することで関数宣言がより理解しやすくなり、ユーザーが引数の位置に頼ることを防ぎたいときに使います。APIについては、引数名が将来変更されることで破壊的API変更となることを防ぐために位置のみ引数を使うと良いです。
任意引数のリスト

この例題は引数の並び順が生むルールについて考える内容です。
*args(可変長引数)が持つ、すべてを吸い込む掃除機のような性質です。*argsは、それより前にある引数に入り切らなかった残りのすべてをまとめて引き受けます。そのため*argsは最後に置くのが基本です。
*argsの後ろにさらに引数を書くと、その引数は位置(順番)を指定することができず、必ず名前=値という形式(キーワード引数)で指定しないとならなくなります。

名前を指定しない場合、3つの単語は*argsに吸収されます。sepには何も渡されていないと判断されてデフォルト値の/が使われます。そのため/で繋がれた文字列が返ります。名前を指定して値を渡す場合、3つの単語は*argsに入ります。sepにも.という名前をつけて渡しているので、ドットで繋がれた文字が返ります。
引数リストのアンパック
リストや辞書にまとめられたデータを関数に渡す直前でバラバラにして渡す(アンパック)手法について考えます。

range(*args)と書くとリストの中身がバラバラになりrange(3,6)と解釈します。

上の例題は辞書に対してアンパックを適用した例です。
lambda(ラムダ)式

xはこの関数の引数です。nは一度設定したらずっと覚えています。これをクロージャ(関数閉包)といいます。またデータソートとしてもラムダ式は使われます。

なぜこの例でラムダ式を使う必要があるのかを考えました。それは「デフォルトの並び替えルール(pairs.sort()とすればOKです)とは違う、特別なルール(2番目の要素で並べる)をその場で作るため」です。通常は1番目の要素(インデックス0)を基準にタプルのリストを並べ替えます。この例では2番目(インデックス1)を基準に並べ替えようとしているためデフォルトとは違った表現をする必要があります。
ドキュメンテーション文字列(docstring)
プログラミングにおけるコメントの一種ですが、単なるメモ以上の役割を持っています。ドキュメンテーション文字列とは、最初の行に記述される文字列のことですが、複数行に渡るのでトリプルクォートで囲んで作成します。使用目的は、その関数が何をするためのものかをプログラム自身に記憶させるためです。一例をあげます。


__doc__はPythonが自動的に用意してくれる変数(属性)です。ここに関数の冒頭に書いた文字列が格納されています。それを出力するだけの関数になります。
関数注釈(関数アノテーション)
アノテーションとは、この引数にはどのようなデータ(型)を入れてほしいかというヒントを書き込む機能です。

この例では、引数のアノテーションと戻り値のアノテーションがあります。これは定義文の1行目に順に現れています。f.annotations は関数に書き込まれた型ヒント(アノテーション)の情報が、辞書形式で自動的に格納されている特別な変数です。これを表示することで、どのような型指定がされているかを確認できます。
今回は'spam'しか位置引数がないので、hamが'spam'になるだけです。eggはそのままです。
幕間つなぎ:コーディングスタイル
PythonではコーディングスタイルとしてPEP8が大事です。
タブは禁止でインデントを用います。
79文字以下で行を折り返します。
関数などでブロック分離の際は空白行を用います。
コメント行は独立させます。
docstringを使います。
演算子やカンマの後にはスペースを入れ括弧内側には入れません。
クラスなどには一貫した命令を行います。メソッドの1行目には常にselfを用います。
UTF-8かASCⅡを用います。
データ構造→7問
リストについての補足
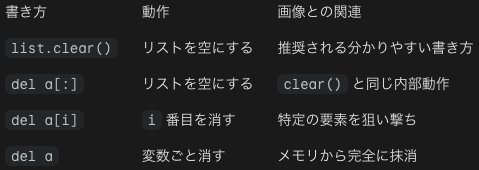
a[len(a):] はスライスで、リストの最後の要素の後ろ(空の場所)という意味で、a[len(a):]=[x] とは、リストの末尾の空っぽの空間に新しい要素xを流し込むという意味になります。これはlist.append(x)と同じです。a[len(a):]=iterablea とは、末尾に反復可能体iterableの全アイテムを追加することでリストを伸長します。これはlist.extend(iterable)と同じです。list.insert(i,x)は、第1引数は挿入したい位置のインデックスで、第2引数はリストに入れたい具体的なデータです。挿入はこの要素の前に行われます。末尾に追加したい場合は、a.insert(len(a),x)とします。list.remove(x)は値がxに等しい最初のアイテムを削除します。xがないとValueErrorが出ます。list.pop([i]) は指定された位置のアイテムをリストから削除します。a.pop()はリストの最後のアイテムを返しリストから削除します。list.clear( ) はリストからすべてのアイテムを削除します。del a[:]と同じです。a=[]はリストを初期化してaと名づけるという意味なので注意です。
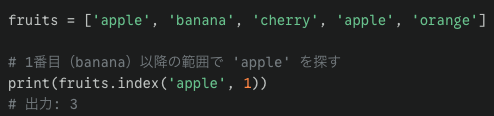
list.index(x[, start[, end]]) は値がxに等しい最初のアイテムのインデックス(0始まり)を返します。アイテムがない場合はValueErrorとなります。これは複雑なので順に考えます。list.index(x)はxと同じ値を差がしてその最初の位置を返します。list.index(x, start, end) は検索する範囲を限定できます。

list.count(x)はリスト中のxの個数を返します。list.reverse()はリストの要素を逆順にします。list.copy()はa[:]と同じです。


リストをスタックとして使う
スタック(LIFO)のトップにアイテムを積むにはappend()を使います。アイテムの削除はpop()を使います。
リストをキュートして使う
キュー(FIFO)はリストでは先頭のappendやpopは効率が悪くなります。そのため実装では先頭と末尾の両方で要素の追加とポップが高速にできるように、collections.dequeを使うべきです。

deque.popleft()は先頭を削除します。
リスト内包
リスト内包はリストを生成する簡潔な方法です。作成方法によっては変数xがリスト作成後に残ってしまうことがあり注意が必要です。次のように設定すればその副作用を防げます。ただし、以下の表記よりもリストの中にfor文を入れることによるリスト内包による表記が最もシンプルになります。

map関数は、「データの集まりの各要素に対して、指定したルールを一括適用する」という役割を持ちます。第1引数はラムダ式で、第2引数はrange(10)です。これら2つの引数に対してmap関数が適用されます。mapそのものは計算の準備ができている状態(mapオブジェクト)を返すだけなので、最後にlist() で囲むことで、計算結果を具体的なリスト形式に変換しています。
リスト内包の一例は次です。
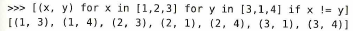
またタプルの例も考えることができます。

この例に対して様々なフィルタをかけてみます。weapon.strip() for weapon in freshfruit について文字列の前後にある余計な空白を削除strip( )する意味です。リスト内の文字列を一括で掃除したいときに非常に便利です。
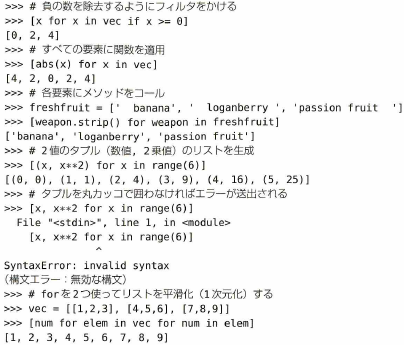
上の例でエラーが出たのは2値のタプルを作るのに()がなかったためです。
最後のリストの平滑化について、2次元リスト(リストの中のリスト)を、1次元の平らなリストに変換します。[num for elem in vec for num in elem] について次のように考えていきます。

また、リスト内包には複合式や入れ子の関数を含むことができます。round(pi, i)で円周率を小数第i位まで丸めるという意味です。

入れ子のリスト内包
リスト内包の先頭の式は任意のあらゆる式が使えるので、ここにリスト内包を入れることもできます。

行と列を入れ替えるリスト内包を考えます。

[[row[i] for row in matrix] for i in range(4)]において外側のループであるfor i in range(4)は「新しく作る行の数」を決めています。元の列が4つあったので、0番から3番まで4回繰り返します。次に内側のループ[row[i] for row in matrix]は、各「新・行」の中身を作っています。

元の行列の縦のライン(列)を、1本ずつ引っこ抜いて、横に並べ直している」と考えるとイメージしやすいです。
しかしこの表現は複雑なので、次の内容と同じになります。

通常のfor文は処理を1行ずつ終えるのでデバッグしやすいですが、コードが長くなり記述に手間がかかります。そこで現実にはzip関数が使われます。これはビルドイン関数の一種です。

zip()は、複数のリストなどの要素を、同じ位置同士でペア(タプル)にする組み込み関数です。list(zip(*matrix))について、*matrixは、リスト(3つのリストが入った1つのリスト)の前に*がついているので、リストの中身をバラバラにして展開するという意味になります。つまり*matrixと書くと、zip関数には3つの独立したリストが引数として渡されます。zipは渡された複数リストを0番目同士、1番目同士というセットにしていきます。この動作が転置の作業となっています。最後にlist( )で読みやすい形に変換しています。
delは変数を丸ごと削除する場合にも使えます。例えば、del aとすると、これ以降aを参照するとエラーとなります。
タプルとシーケンス
タプルは一度作ったら中身を変更できません。これを不変体といいます。しかしリスト(可変体です)の同種類のみのデータと比べタプルは異種類のデータセットを固定して扱えます。またリストより少し高速でメモリ消費が少ないです。

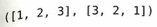
最後の箇所が難しいので具体例で説明します。


タプルから見れば0番目の要素が指している住所は変わっていないのでルール違反にはなりません。住所の先にあるリストの中身を変えているだけです。

要素が1個のタプルを作る際は、必ず最後に,をつけましょう!
t = 12345, 54321, 'hello!'という行のように、通常、変数は1つの値しか持てませんが、Pythonではカンマで区切って並べると、それらを「1つの箱(タプル)」にまとめて入れてくれます。これをタプル・パッキングといいます。
カッコ() を書かなくても、カンマがあるだけでPythonは「あ、これは箱詰め(パッキング)だな」と理解してくれます。
次に逆の操作を考えます。x, y, z = t つまり、箱tの中身を、別々の変数x, y, z に一度に取り出します。これは段ボール箱を開けて、中身をそれぞれ決まった場所(変数)に並べる作業で、シーケンス・アンパッキング(荷解き)といいます。その結果、x には12345が、y には54321が、z には'hello!'が入ります。
この機能により、通常はtempを作るべき入れ替えの作業がスムーズにできます。a, b = b, aとすれば、これだけで2文字が入れ替わります。その理由は右辺で「パッキング(箱詰め)」し、左辺で「アンパッキング(荷解き)」を同時に行っているからです。
集合(set)
集合のデータ型は存在判定や、重複エントリの排除があります。集合の生成には{ }やset( )関数を使用します。空の集合を生成するにはset( )を用います。{ }だと空のディクショナリを生成してしまうからです。

a = {x for x in 'abracadabra' if x not in 'abc'} は、文字列からxという名前で1文字ずつ取り出しますが、その際にxがa, b, c のいずれでもない場合に採用します。採用された文字を{ }で囲って集合でまとめます。
ディクショナリ
辞書は{ }を用います。


まだ辞書にない新しい名前を指定して値を代入すると、自動的にペアが追加されます。またキーが簡単な文字列なら、キーワード引数でペアを指定するのが楽な場合があります。

この場合はキーワード引数なのでクォートが不要です。Pythonが内部で自動的に文字列のキーに変換してくれるためです。
ループのテクニック



以下の例は逆順や並べ替えは reversed() やsorted() を用いる例です。seeで重複を消してから並べ替える高度なテクニックは、sorted(set(basket)) です。




この例は不純物(欠損値)が含まれたデータから正しい数値だけを抽出する実践的なコードです。if not math.isnan(value): はもし値がNaN(非数)でないなら新しいリストに追加するというフィルター処理を行なっています。結果は、float('NaN') が排除され、計算可能な数値だけのリストが完成します。
条件についての補足
a<b==cは、aはbより小さく、かつbはcと等しいという意味です。andやorはブール演算子です。この演算子ではnotの順位が最も高く、orが最も低いです。ブール演算子は短絡演算子とも言われます。これは引数の評価が左から右へ行われ、結論が決定した時点で評価をやめるためです。
空の文字列はPythonでは偽とみなされます。

このプログラムは最初に見つかった有効な値を取り出す内容です。一般の言語のorは「真(True)か偽(False)か」だけを返しますが、Pythonのorは短絡評価(ショートサーキット)が行えます。2番目の内容が合致するので、その内容が変数に代入されます。
name = input_name or "名無しさん" というコードは「ユーザーが名前を入力しなかったら、代わりに『名無しさん』と表示する」といった処理を1行で書けたことになります。
シーケンスの比較、その他の型の比較
Pythonでは辞書式序列で比較します。最初に違う値が出てきた時点で、その値の大小がシーケンス全体の大小として決定します。もし片方がもう片方の接頭辞であり、そこまでの要素がすべて同じなら短い方がいいと判定されます。文字列は文字列コードで比較されます。Aは65でCは67です。

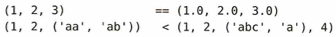
型が混ざっている場合は、例えば整数と浮動小数点は、値が同じならTrueと判定されます。入れ子のときは、中に入っているタプル同士も再帰的に辞書式順序で比較されます。しかし(1,2)<abなどを比較しようとすると。Python3ではTypeErrorが発生します。
気楽な入門編→››6問
除算は常にfloatを返します。切り下げ除算(小数点以下切り捨て)をしたい場合は17 // 3 のようにすれば 5 返ってきます。NameErrorに注意しましょう。

対話モードでは最初に表示した式を変数_(アンダースコア)に代入しているので計算を続けるのが非常に楽です。round(_, 2)は_の値を小数点第3位を四捨五入して小数点第2位まで表示させる意味です。また複素数を表示させるには虚数単位iをjまたはJとします。
文字列ではバックスラッシュ(\)でクォート文字のエスケープができます。「エスケープ」とは、一言でいうと「特別な記号を、ただの文字として扱わせるための合図」のことです。つまり次の引用符はただの『文字』だよ」とPythonに伝えることができます。


print()関数について注目します。

上の例ではそのまま評価した場合と、print() を用いた場合の見た目の違いに注目します。print() 関数の場合はバックスラッシュなどがなくなり最終的に画面に出したい文字だけがすっきりと表示されます。改行(\n)についても同様です。\を前置した文字が特殊文字として解釈されるのが嫌なときはraw文字列を用いれば良いです。これは最初の引用符の前にrを置きます。

上の例ではファイルパスのように表示したいのですが、最初の例では\nが改行として働いてしまいます。次の例では引用符の前にrをつけています。そのため「この引用符の中にある\は、改行などの命令(エスケープシーケンス)ではなく、ただの文字として扱ってね」という合図になります。そのため意図した通りに、\もnも表示されました。
このようにraw文字列はWindowsのファイルパスや、正規表現の際に用いることが一般的です。
文字列リテラルを複数行に渡り記述する際はトリプルクォートを用います。列挙された文字列リテラル(引用符で囲まれたもの)は自動的に連結されます。そのため+記号を使わなくてもOKです。ただし、変数と文字列リテラルは連結できません。その際はSyntaxErrorがおきます。この問題は+記号を用いれば解決します。
大きすぎるインデックスを指定するとIndexErrorが生じます。例えば Pythonを例にとると、word[42]としたらIndexErrorが起きる場合でも、スライスのインデックスでは範囲外を指定した場合でも良い具合に対処してくれます。

Pythonの文字列は改変できない(不変体)であることに注意しましょう。

この例では0番目の文字をJに書き換えようとしていますが、文字列は変更不可なのでエラーになります。また2番目以降の文字をまとめて書き換えようとしていますが、同様のエラーがおきます。文字列を変えたい場合は次のようにします。

ライブラリリファレンスは公式の説明書を意味します。pythonにはPython標準ライブラリリファレンスがあります。

リスト
リストには異なる型のアイテムを入れることもできますが、通常は同じ型を入れます。スライシングはリストのシャローコピーを新しく作って返すことになります。またリストは連結の操作もサポートします。連結は+記号で行えます。
文字列は不変体
リストは可変体
スライスへの代入も可能で、リストの長さを変えることもリストの内容をクリアにすることもできます。

またリストは入れ子にできます。

標準ライブラリめぐり→4問
OSインターフェイス
OSモジュールはオペレーティングシステムとやり取りするための関数をいくつも提供します。

Pythonプログラムの中からフォルダを開く、フォルダを作るなどの操作を命令して実行しています。getcwdはget current working directoryの略です。'C:\Python39' はPythonがどのフォルダ(作業ディレクトリ)を見ているかを表示します。この場合はCドライブのPython39フォルダの中です。chdirはchange directoryの略です。作業するフォルダを指定した場所 /server/accesslogs に変更します。mkdirはmake directoryの略で、この命令を使って新しくtoday という名前のフォルダを作成しています。最後の0は命令が成功したというシステムからの返事です。これを終了コードといいます。


Pythonでそのモジュールの中にはどのような機能があるのかを調べるための2つのツールです。dir(os) はこのモジュールにはどんな名前の道具が入っているか?を確認するものです。またhelp(os)は詳細な取り扱い説明書を見るものです。

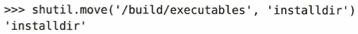
shutilはshell utilitiesの略で、先ほどのosモジュールよりもファイル単位、フォルダ単位でのコピーや移動といった、より実務的な管理作業を得意とする道具箱です。shutil.copyfile('data.db', 'archive.db') はファイルのコピーを行います。現在のフォルダにあるdata.db というファイルを、同じ内容のまま archive.db という新しい名前で保存します。成功すると新しく作られた方のファイル名が表示されます。shutil.move('/build/executables', 'installdir') はファイルやフォルダの移動(または名前変更)を行います。/build/executables にある中身を、installdir という場所に丸ごと移動させます。成功すると移動先のパスであるinstalldir が表示されます。
Pythonを使えば、手作業でドラッグ&ドロップしなくても、プログラム1行でファイルのバックアップや配置(移動)を自動化できるのですね!
ファイルのワイルドカード

globモジュールを使って、特定の条件に合うファイル名を探し出す操作をしています。これはフォルダの中にどんなファイルがあるかをワイルドカード(*)を使って検索する機能です。glob.glob('*.py') は最後が.py で終わるすべてのファイルを探し出します。
コマンドライン引数

まずPythonのシステム自体に関わる機能を扱う道具sysを読み込みます。sys.argv はargument vector(引数の配列)の略で、プログラムに渡されたすべての単語を保持しているリストです。動作として、実行時にどのような言葉が入力されたかを表示します。'demo.py', 'one', 'two', 'three' の解釈は、python demo.py one two three をプログラムが実行したことを示しています。リストの0番目には実行したプログラム名が入ります。以下にはリストに格納された単語が順番に並んでいます。

argparseはどの言葉がファイル名で、どれがオプション(設定)かを自動で判別し、ヘルプメッセージまで作成してくれる便利な道具箱です。複雑なので役割をまとめます。

エラー出力のリダイレクトとプログラムの終了
pythonには情報を出力するルートがいくつかあります。stdoutは標準出力で、通常の計算結果やメッセージを出すルートです。stderrは標準エラー出力で警告やエラーメッセージを出すための緊急用ルートです。sys.stderr.write('Warning, log file not found…') は警告:ログファイルがないので新しく作りますよという意味です。
sys.exit( ) はプログラムを潔く終わらせる命令です。必要なファイルが見つからず、これ以上処理を続けられない時や、ユーザーが終了を選択した時に使用します。

文字列パターンマッチング

reモジュールは正規表現(Regular Expression)による高度な文字列操作を実現します。正規表現とは、特定の「文字の並び方のパターン」を指定して、検索や置換を行うための非常に強力な言語のようなものです。re.findallは条件に見合う言葉をすべて見つけます。この例では、fで始まる単語をすべて探しています。

これを満たす単語がリストとして抽出されます。
re.sub は重複した言葉を一つにまとめます。re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat') # 結果: 'cat in the hat' は同じ単語が2回連続して並んでいる(うっかりミスのような)場所を見つけ、それを1つにまとめています。

しかし次のような場合は正規表現でなく、文字列メソッドを使用します。読みやすくデバッグしやすいからです。

数学
mathモジュールを使うと、浮動小数点数数学用の下層のCライブラリ関数にアクセスできます。cos(π/4)はmath.cos(math.pi/4)と入力します。log2(1024)はmath.log(1024, 2)と入力します。


SciPyプロジェクトには、他のも数多くの数値計算用モジュールがあります。
インターネットへのアクセス
urllib.requestはURLにあるデータを取得するもので、smtplibはメールを送るものです。

from urllib.request import urlopen はインターネット上のURLを開くための道具urlopenを開きます。with urlopen('http://…') as response: で指定したアドレスに接続してデータを取得します。withを使う事により、データの読み込みが終わった後に自動で接続を閉じてくれる(後片付けをしてくれる)ようになります。for line in response: で送られてきたデータ(何行もあるテキストデータ)を、1行ずつ順番に読み込みます。line = line.decode('utf-8') はインターネットから届くデータは、コンピュータ用の「バイナリ形式」になっているので、decode('utf-8') を使って、僕たちが読める「テキスト形式」に変換(デコード)しています。if 'EST' in line or 'EDT' in line: はその行の中に「EST(東部標準時)」または「EDT(東部夏時間)」という文字が含まれているかチェックします。print(line) は条件に当てはまった行だけを画面に表示します。

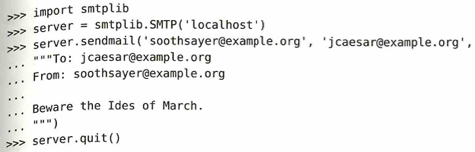
これはプログラムがメールの作成から送信完了までをどう進めているかの話です。上の例題と流れは似ています。server = smtplib.SMTP('localhost') はメールを配送してくれるサーバー(郵便局のような存在)に接続します。ここではlocalhostで動いているサーバーを指定しています。server.sendmail(送信元, 送信先, メッセージ内容) は実際にメールを発送する命令です。メッセージ内容にはトリプルクォートが使われており、宛先・差出人・本文といった「メールの形式」を複数行で一気に作成しています。server.quit() でサーバーとの接続を終了します。
日付と時間

srftime(string Format Time)メソッドは日付データを読みやすい文字列に変換します。

データ圧縮
モジュールは、zlib, gzip, lzma, zipfile, tarfile があります。次の例はzipbモジュールを使ってデータの圧縮と展開を行なっています。

s = b'witch which has which witches wrist watch' は頭のbはバイト列という意味です。この時点で41文字です。t = zlib.compress(s) でデータ圧縮を行なっています。この状態で37文字に減りました。zlib.decompress(t) は圧縮されたデータtを元の状態に解凍しています。zlib.crc32(s) はデータの指紋のようなものでチェックサムです。データが転送中に壊れていないか確認するにために使われる数値です。
パフォーマンス計測
timeitモジュールは小さいパフォーマンスの差をすばやく示します。profile, pstatsモジュールは大きめのコードブロックに対してプログラム全体の実行統計(どこがボトルネックか)を調べる時に使われます。次の例は、「どちらの書き方のほうが実行スピードが速いか?」をミリ秒単位で計測(プロファイリング) している様子です。
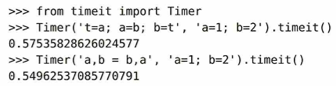
timeitモジュールは、デフォルトで100万回その処理を繰り返し、その合計時間を返します。
品質管理
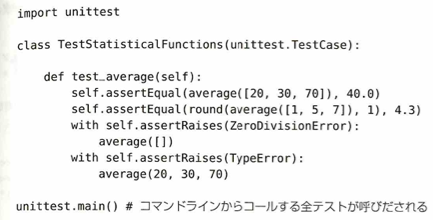

説明文の中に>>>があったらdoctestと覚えるのがコツです。
このコードの最大の特徴は、「関数の説明文(docstring)の中に、実行例をそのまま書き込んでいる」 点にあります。doctest.testmod() の命令を出すと、Pythonが説明文の中の >>> 部分を自動的に見つけ出し、実際に計算した結果と説明文に書いてある結果が一致するか を検証してくれます。
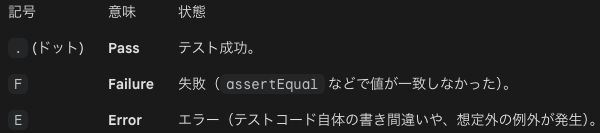
次にunittestを紹介します。unittestモジュールは「独立したテストプログラムをしっかり組む」ためのより本格的な道具です。

unittestの実行結果の記号は下記になります。
電池付きであること
xmlrpc.client, xmlrpc.serverモジュールは、少しの手間でリモートプロシージャコールが実装できます。ただしXMLの知識は不要です。
emailパッケージはMIMEやRFC2822ベースのメッセージを処理できます。smtplib, poplib と異なりメッセージの送受信はしません。emailパッケージは完全なツールセットです。
jsonパッケージはデータ交換で用います。csvモジュールはCSV形式ファイルの直接の読み書きをサポートします。XMLの処理は、xml.etree.ElementTree, xml.dom, sml.sax の各パッケージでサポートされています。
sqlite3モジュールで、SQLiteデータベースライブラリにアクセスできたりします。
国際化はgettext, locale などのモジュール群、codecsパッケージなどのモジュールでサポートされています。
エラーと例外→4問
エラーには構文エラー(SyntaxError)と例外(exception)があります。
構文エラー
次のコードはプロンプト(>>>)があることから、Pythonの対話モードが命令を入力してくださいと出ていることがわかり、何らかのエラーが発生して、その対応のコードになります。File "<stdin>", line 1 について、stdinは標準入力という意味で、その場で打ち込んだ内容を処理していることを示しています。SyntaxError: invalid syntax はPythonのインタープリタ(実行プログラム)が文法的に解釈できないと判断したときに表示されるPython専用の警告です。

パーサ(構文解釈器)は違反のある行を表示し、最初にエラーが検知された点を小さな矢印(^)で表示します。エラーは矢印より前のトークン(コードを構成する最小単位の単語)が原因です。この例では、エラーはprint関数で検知されます。それは直前にコロン:がないからです。ファイル名と行番号が表示(File "", line 1)されるので、スクリプトからの入力でもどこを見ればよいかわかります。
例外
文や式が構文的に正しくても実行しようとするとエラーが起きることがあります。

例外のほとんどはプログラムで処理されず、結果はエラーメッセージに現れます。ZeroDivisionErrorは0で割ろうとすると出るエラーです。NameErrorはまだ作っていない名前を使おうとすると出るエラーです。TypeErrorはデータ型が異なるものを足そうとすると起こります。Traceback (most recent call last): はエラーが発生するまでの軌跡です。
例外の処理
以下の例はユーザーが有効な整数を入力するまで入力を促しつづけますが、ユーザーがプログラムに割り込みをかけて終了させることもできます。この時keyboardInterrupt例外が送出されます。

While True:は真となるまで処理を繰り返します。try:ブロックは、エラーが起きるかもしれない処理を書きます。int(input(...)) は、ユーザーが入力した文字を「整数」に変換する命令です。真の場合にbreakが発動し、ループを抜け出します。except ValueError: はもし ValueError が起きたら、ここを実行してね」という指示です。このようにtry exceptを使うことで、ユーザーの入力ミスを許容で、プログラムを安定して動かし続けることができます。

ハンドラとは、特定のイベントやエラーが発生した際に、それをどう処理するかを受け持つコード(担当者)のことです。exceptブロックは例外ハンドラです。一度の処理で実行されるハンドラは1つまでです。また未処理例外とは、プログラム実行中にエラーが発生した際に、それを適切に処理するコード(ハンドラ)が用意されておらず、プログラムが強制終了してしまう状態のことです。

次のコードはBCDの順に表示します。

最初の設定がややこしいのでまとめます。
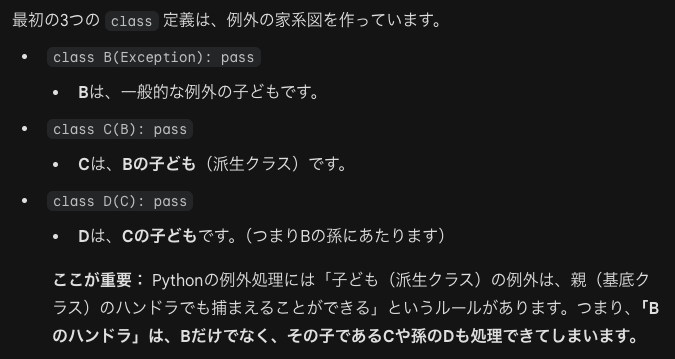
この問題では、exceptがDCBの順で並んでいます。DでDがあるかチェックします。Dがないので次はCでチェックします。CがないのでBでチェックします。Bは洗い網でBCDを捉えられます。Cは次に粗くCDを捉えます。DはDしか捉えることができません。

BCDの順でチェックすると最初のBの網で全部引っかかってしまい、遮蔽(その下まで辿り着けない、BBBと出力される)がおき、バグの原因となります。

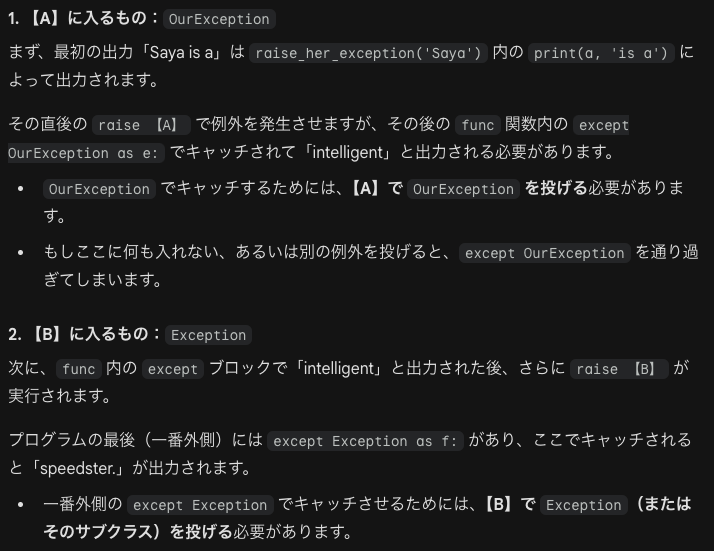
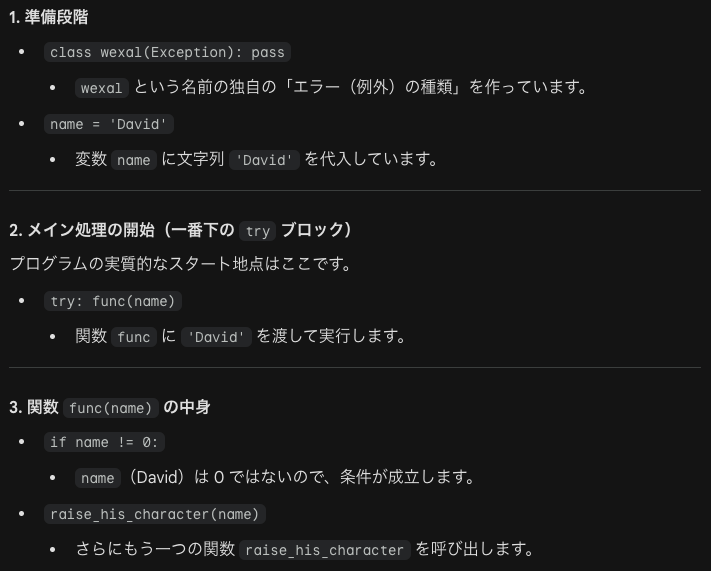
この例は、実際のファイル読み込み作業を例に、複数のエラーを使い分ける方法を示しています。except OSError as err: は「ファイルが見つからない」「開けない」などのシステム的なエラーを専門に扱います。except ValueError: はファイルは開けたけれど、中のデータが数字に変換できなかった場合を扱います。except: は上記のどれにも当てはまらない「予想外のエラー」をすべて受け止めます。raise: は予想外のエラーだった場合、ログだけ残して、あえてエラーを再発させてプログラマに知らせます(これを例外の再送出と呼びます)。

else句により、open(ファイルを開く)だけを try に入れることで、関係ない場所(行数カウントなど)で起きたエラーを誤って捕まえてしまうのを防ぎます。



さらに10番と11番が難しいので別に解説します。
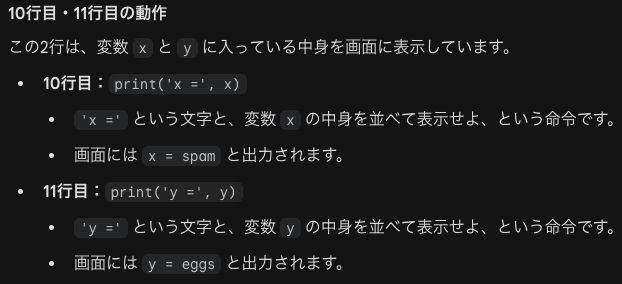

深い場所(関数の中)でトラブルが起きても、浅い場所(メインの処理)で一括してエラーを見守り、対処することができます。つまりエラーが発生した場所のすぐ側で処理する必要はないということです。
例外の送出

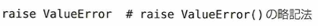


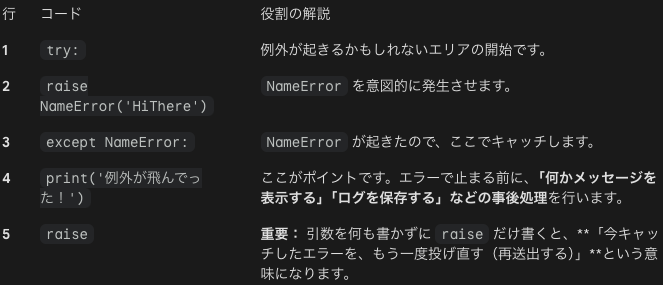
しかしprintの後でまたraise(今捕まえたこのエラーを、もう一度発生させて外側に丸投げする)があります。そのため次のようなことが起きます。
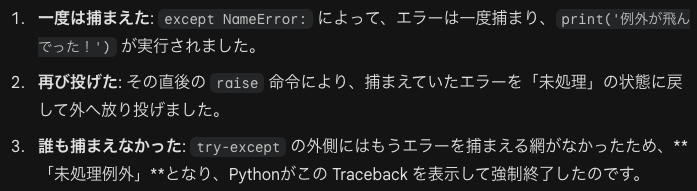
最後にNameErrorが出たのは、最終的に「未処理」になったため、Pythonはプログラムを強制終了し、どこでエラーが起きたかを知らせるための Traceback(エラーレポート)を表示した、というわけです。
初見時ではかなり難しく感じます。
例外の連鎖
あるエラーが原因で別のエラーが発生した因果関係を記録する例です。

from exc を使った場合: Pythonは「Aが原因でBが起きた」という履歴をすべて保持します。
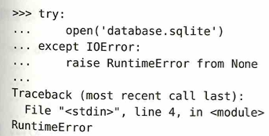
open('database.sqlite') は存在しないファイルを開こうとして、IOError が発生します。raise RuntimeError from None は通常、エラーを捕まえて別のエラーを投げ直すと、Pythonは自動的に「元の原因(IOError)」もレポートに載せようとします。しかし、ここで from None と書くことで、「元のエラーの情報はいらないので、履歴を消して新しいエラーだけを表示してくれ」と指示しています。
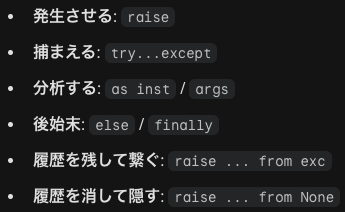
ユーザー定義例外

1番目の例は、ベースとなるエラーを作ります。すべての独自エラーの親となるErrorクラスを定義しています。Exceptionを継承することで、Pythonの標準的なエラーと同じようにtry-exceptで捕まえられるようになります。2番目の例は、具体的なエラーを設定します。ユーザーの入力ミス専用のエラーです。「どの入力式(expression)」で「どんな間違い(message)」があったのかという情報を、エラー自身が保持できるように設計されています。3番目の例は、状態推移のエラーを設計します。システムの状態変更が許可されないときに使うエラーです。「前の状態」「次になろうとした状態」「理由」の3つの情報をセットで持ち運びます。
クリーンアップ動作の定義

finally ブロック: ここに書かれた print('Goodbye, world!') は、上のエラーによってプログラムが止まる直前に、必ず実行されます。


この例では何がなんでもfinallyを実行することの証明になっています笑

この例でも「どれほど予期せぬエラーが起きてプログラムがクラッシュしたとしても、finally だけは必ず最後に実行される」という、Pythonの鉄の掟を証明しています。
オブジェクトに定義済のクリーンアップ動作

このコードの問題は、この部分を実行した後の不定時間の間、ファイルを開きっぱなしにしていることです。次の例でこの対処を述べます。
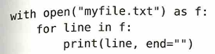
with ブロックを抜けた瞬間に、Pythonがバックグラウンドで自動的に f.close( ) を実行します。これにより、開発者が手動で閉じるのを忘れるというミスが物理的に起こらなくなります。fとはファイルのfという意味です。別にfを使わなくても構いません。
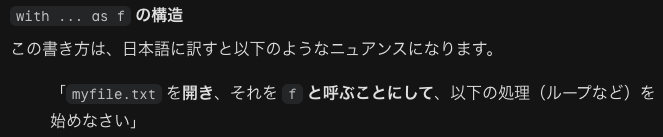
食欲をそそってみようか→1問
Pythonはエラーチェック機能がかなり多いです。データ型の一般性が高いのでPython対応可能な問題領域は広いです。Pythonで書いたプログラムはモジュール群に分割して再利用が可能です。Pythonはインタープリタ言語であり、コンパイルもリンクも不要でプログラム開発の時間を節約できます。Pythonはプログラムを小さく読みやすく書けます。
高水準なデータ型
文のグルーピングはインデント
変数や引数の宣言が不要
Pythonは拡張可能です。Pythonの由来は、BBCのテレビ番組『Monty Python's Flying Circus』です。
対話環境での入力行編集とヒストリ置換→1問
インタープリタの種類によって、KornシェルやGNU Bashのような機能をサポートしています。GNU Readlineライブラリを実装しており、さまざまな編集スタイルをサポートします。
Tabキーを使って保管機能を呼び出せます。Pythonの命令の名前、現在のローカル変数、使用できるモジュール名前を検索します。これはインタープリタ起動時に自動的に有効になります。string.aのようなドット月の表記は、最後の.まで式を評価します。しかし__getattr__( )メソッドのオブジェクトがあると、定義されたコードが実行される可能性があるので注意しましょう。デフォルトでは/.python_historyのファイルにヒストリを保存できます。
インタープリターは自動的にインデントを行います。またカッコや引用符などをチェックします。拡張された対話型インタープリタではbpythonがあります。これはタブ補完、オブジェクト検索、高度なヒストリ管理があります。他にはIPythonという拡張対話環境があります。
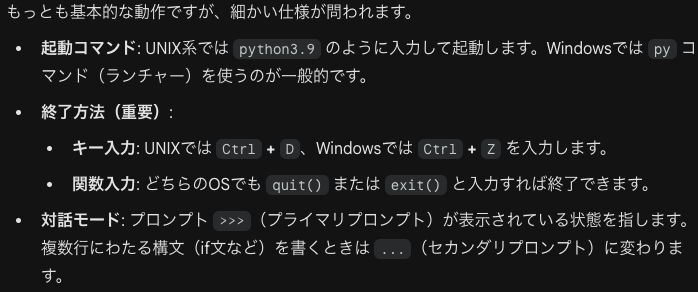
Pythonインタープリタの使い方→1問
インタープリタの起動と終了
インタープリタが使用可能な場合、通常は、/user/local/bin/python3.9としてインストールされています。

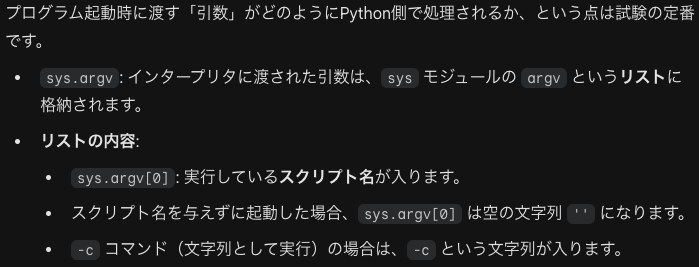
コマンドライン引数の取り扱い(sys.argv)
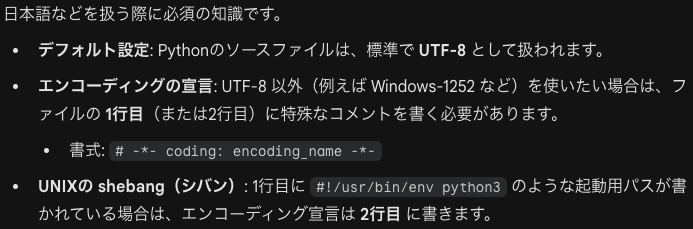
ソースコードのエンコーディング

仮想環境とパッケージ→1問
この章は意外とごちゃごちゃしているので、まずはポイントをおさえてから、細かい箇所を見ていきます。
仮想環境(venv)の基本
pip を使ったパッケージ管理

環境の記録と再現(requirements.txt)
以下、細かい箇所です。
イントロダクション
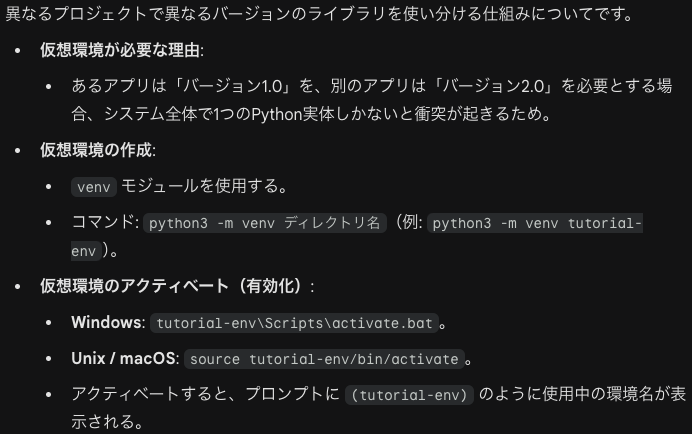
Pythonのインストール実体が1つだけではすべてのアプリケーションの要求を満たせません。仮想環境の生成によりこの問題は解決されます。Pythonでプログラミングをする際に、プロジェクトごとに「独立した部屋」を作るようなイメージです。例えばアプリケーションAにはバージョン1.0の入った仮想環境を、アプリケーションBにはバージョン2.0の入った別の仮想環境を持たせることができます。アプリケーションBがバージョン3.0にアップグレードされたライブラリを必要となっても、アプリケーションAの環境には影響しません。
仮想環境の生成
仮想環境の生成や管理に使われるモジュールをvenv(virtual environment)といいます。

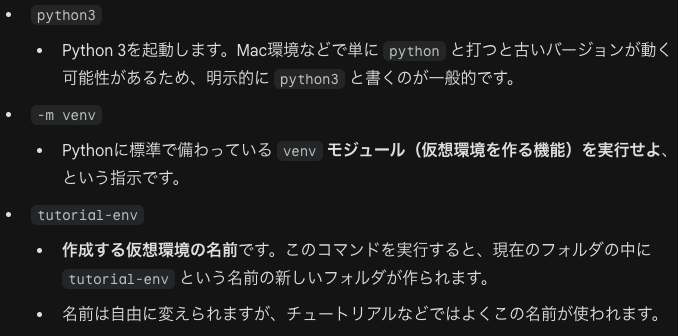
次にアクティベートをします。

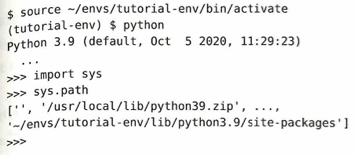
上のはbash向けです。csh, fish を使う場合は、activate.csh, activate.fishとします。仮想環境をアクティベートするとシェル・プロンプト(コンピュータがあなたの命令(コマンド)を待っている状態を示す「合図」のことです。ターミナルやコマンドプロンプトを開いたときに表示される、$ や %、> といった記号、およびその前に表示されている文字の並びを指します。)が使用中の仮想環境を示すものに変更されます。

Pythonと入力したときに指定の特定バージョンのインストール実体(ショートカットや名前だけではなく、「実際にコンピュータの中に保存されたプログラムの本体(ファイルやデータ)」のことを指します。)が実行されるように環境が改変されます。

pipによるパッケージ管理

(tutorial-env): 現在「tutorial-env」という名前の仮想環境が有効になっていることを示しています。これにより、システム全体を汚さず、このプロジェクト専用のライブラリ管理ができます。pip search: PyPI(Python Package Index)という公式のリポジトリから、パッケージを検索するコマンドです。astronomy: 検索ワードです。ここでは「天文学」に関連するライブラリを探しています。skyfield - Elegant astronomy for Pythonは、パッケージ名: skyfieldで、Python用の「エレガントな」天文学ライブラリ。惑星の位置計算や天体イベントの予測によく使われる、非常に人気のあるライブラリです。gary - Galactic astronomy and gravitational dynamics. について、パッケージ名: garyは、銀河天文学と重力力学のためのツール。銀河の構造や、星が重力でどう動くかをシミュレーションする際などに使われます。novas - The United States Naval Observatory NOVAS astronomy library は、パッケージ名: novasでアメリカ海軍天文台(USNO)が提供する「NOVAS」という計算ルーチンのPython版。非常に精密な天体の位置計算(座標変換など)に使われます。astroobs - Provides astronomy ephemeris to plan telescope observations は、パッケージ名: astroobsで、望遠鏡での観測計画を立てるための天体暦を提供します。いつ、どこに、どの星が見えるかを調べるためのツールです。PyAstronomy - A collection of astronomy related tools for Python. は、パッケージ名: PyAstronomyで、天文学に関連する様々なツールを集めたコレクション。スペクトル解析やフィッティングなど、実用的な解析機能が詰まっています。
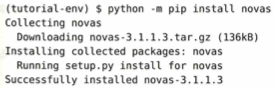
(tutorial-env) $ python -m pip install novas はpython -m pip: Pythonを経由して pip を実行するという指示です。単に pip install と打つのと同じ役割ですが、複数のPython環境がPCにある場合に「現在動かしているPythonに対してインストールする」という、より確実な方法です。Collecting novas は、Collecting: 「集めています」という意味です。インターネット上の公式リポジトリ(PyPI)から、指定された novas という名前のパッケージを探し出している状態です。Downloading novas-3.1.1.3.tar.gz (136kB) は、Downloading: ファイルをダウンロードしています。(136kB): ファイルのサイズです。非常に軽量なライブラリであることがわかります。Installing collected packages: novas は、Installing: ダウンロードしたファイルを解凍し、Pythonから使えるように適切なフォルダへ配置する作業を開始したことを伝えています。Running setup.py install for novas は、Running setup.py: このパッケージに含まれる「インストール手順書(setup.py)」を読み込み、インストールに必要な初期設定やビルドを行っています。Successfully installed novas-3.1.1.3 は、Successfully installed: 「無事にインストールが成功しました!」という最終報告です。これで、あなたのプログラムの中で import novas と書けば、このライブラリの機能が使えるようになりました。
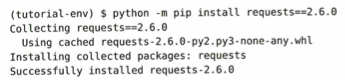
(tutorial-env) $ python -m pip install requests==2.6.0 は、requests: ウェブサイトからデータを取得したりする際に使う、Pythonで最も人気のあるライブラリの一つです。==2.6.0: ここが重要です。「最新版ではなく、ピンポイントで 2.6.0 というバージョンを入れてください」という指示です。開発現場では「最新版だとプログラムが動かなくなる」といった理由で、あえて古いバージョンを指定することがよくあります。Collecting requests==2.6.0 は指定された requests のバージョン 2.6.0 を探しています。Using cached requests-2.6.0-py2.py3-none-any.whl は、Using cached: ここが1枚目と異なります。以前に同じファイルをダウンロードしたことがあるため、「ネットから落とし直さずに、PC内に保存されていたデータを使います」という意味です。これにより、インストールが高速になります。.whl (Wheelファイル): 1枚目の .tar.gz 形式よりも、さらにインストールが速くて簡単な「完成済みパッケージ」のような形式です。Installing collected packages: requests はPC内のキャッシュから取り出した requests を、仮想環境 tutorial-env の中に配置する準備をしています。Successfully installed requests-2.6.0 は、無事に バージョン 2.6.0 のインストールが完了しました。
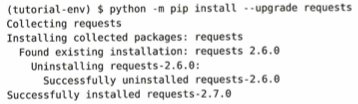
(tutorial-env) $ python -m pip install --upgrade requests は、--upgrade: これが今回のキーとなる命令です。「もしすでにインストールされていても、それを最新のバージョンに更新してください」という意味です。Collecting requests は、インターネット上のリポジトリから、requests の最新バージョンを探しています。Installing collected packages: requests は、ダウンロードした最新版のインストール準備に入ります。Found existing installation: requests 2.6.0: 「すでにバージョン 2.6.0 が入っているのを見つけました」と報告しています。Uninstalling requests-2.6.0:: 新しいものを入れる前に、古い 2.6.0 を削除(アンインストール)し始めます。Successfully uninstalled requests-2.6.0: 古いバージョンの削除が完了しました。Successfully installed requests-2.7.0 は、無事に、最新である バージョン 2.7.0 のインストールが完了しました。
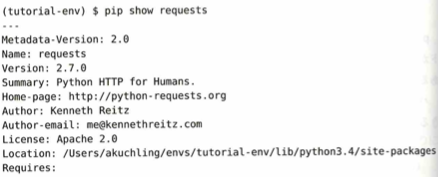
(tutorial-env) $ pip show requests は、pip show: 指定したパッケージの詳細なステータスを表示するコマンドです。requests: 調べたいパッケージ名です。先ほどアップデートした結果が反映されているか確認しています。Metadata-Version: 2.0 は、この情報自体のフォーマットバージョンです(パッケージのバージョンとは別物です)。Name: requests は、パッケージの名前です。Version: 2.7.0 は、重要ポイント: 先ほどのアップデートにより、バージョンが 2.7.0 になっていることがここで確認できます。Summary: Python HTTP for Humans. は、パッケージの短い説明です。「人間のためのHTTP(通信用ライブラリ)」という、このライブラリの有名なキャッチコピーです。Home-page: http://python-requests.org は、公式サイトのURLです。使いかたのドキュメントなどを探す際に役立ちます。Author: Kenneth Reitz は、作者の連絡先メールアドレスです。License: Apache 2.0 は、利用規約(ライセンス)の種類です。Apache 2.0は、商用利用もしやすい自由度の高いライセンスです。Location: /Users/akuchling/envs/tutorial-env/lib/python3.4/site-packages は、重要ポイント: このライブラリの実体が、PC内のどのフォルダに保存されているかを示しています。ここでは仮想環境 tutorial-env の中にあることがわかります。Requires: は、このライブラリを動かすために、他に必要なライブラリ(依存関係)が表示される場所です。空欄の場合は、単体で動くことを意味します。

(tutorial-env) $ pip list は、pip list: 現在有効なPython環境(ここでは tutorial-env)にインストールされているパッケージの名前とバージョンを、アルファベット順に並べて表示するコマンドです。novas (3.1.1.3) は、最初の操作でインストールした天文学ライブラリです。numpy (1.9.2) は、数値計算を高速に行うための非常に有名なライブラリです。他のライブラリを入れた際に自動的に入ったか、最初から環境に含まれていたものと考えられます。pip (7.0.3) は、今まさに使っている「パッケージ管理ツール」自身も、一つのパッケージとして管理されています。requests (2.7.0) は、重要ポイント: バージョン 2.6.0 を入れた後、--upgrade で更新した結果、しっかり 2.7.0 になっていることが確認できます。setuptools (16.0) は、Pythonのパッケージをインストールしたりビルドしたりするのを助ける、基礎的なツールです。

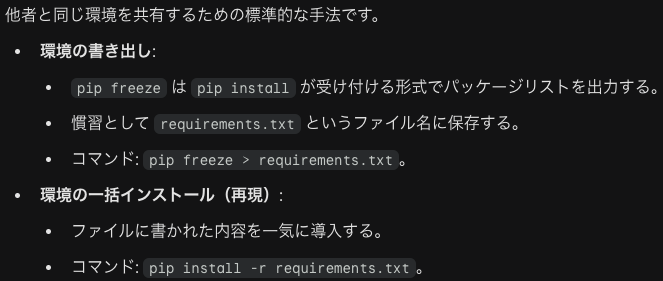
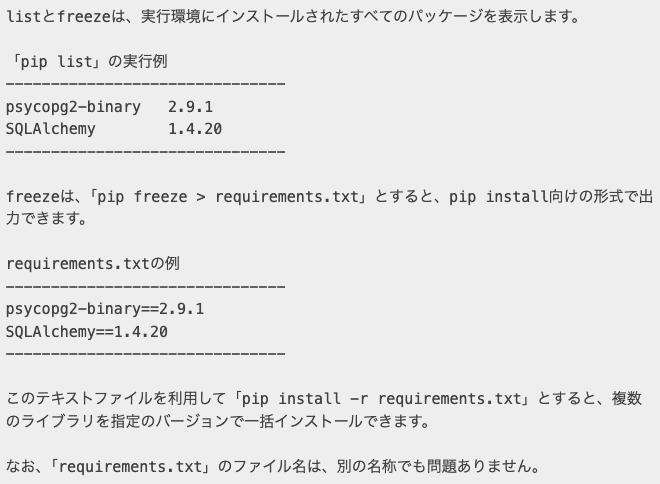
(tutorial-env) $ pip freeze > requirements.txt は、pip freeze: 現在の環境にインストールされているライブラリとそのバージョンを、パッケージ名==バージョン という形式で出力するコマンドです。> (リダイレクト): 本来画面に表示される結果を、ファイルの中に流し込むための記号です。requirements.txt: 書き出し先のファイル名です。Pythonの世界では、必要なライブラリの一覧をこの名前のファイルに保存するのが標準的なルールとなっています。(tutorial-env) $ cat requirements.txt は、cat: 指定したファイルの中身を画面に表示するコマンドです。「正しく書き込めたかな?」と確認しています。novas==3.1.1.3, numpy==1.9.2, requests==2.7.0 は、これらは pip list で確認した内容と同じですが、すべてに == が付いています。これにより、将来このファイルを使ってインストールする際、「全く同じバージョン」が確実に導入されるようになります。
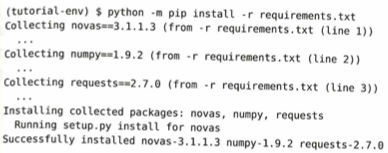
(tutorial-env) $ python -m pip install -r requirements.txt は、-r: 「この後に続くファイル(requirements)の中に書かれたパッケージをすべてインストールして」という指示です。これにより、一つずつパッケージ名を手で入力する手間が省け、書き出された当時と全く同じバージョンが自動で選択されます。requirements.txt の中身を1行ずつ読み取って実行しています。Collecting novas==3.1.1.3 (from -r requirements.txt (line 1)) は、ファイルの1行目に書かれた novas のバージョン 3.1.1.3 を探し出しています。Collecting numpy==1.9.2 (from -r requirements.txt (line 2))は、同様に、2行目の numpy を探しています。Collecting requests==2.7.0 (from -r requirements.txt (line 3)) は、3行目の requests を探しています。Installing collected packages: novas, numpy, requests Running setup.py install for novas は、必要な全てのパッケージが揃ったので、一気にインストールを開始しています。Successfully installed novas-3.1.1.3 numpy-1.9.2 requests-2.7.0 は、全てのインストールが成功しました。これで、元の環境と寸分違わぬクローン環境が完成したことになります。
以下の内容は試験に合格するという目的から考えると、いわゆる学習効率が低い箇所です。そのため上述の『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』を用いて出てきた内容で総合的に学習します。
モジュール→2問
『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の学習と下記の模試の学習で代用します。また最後に黒本『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の2周目の際にまとめます。
入出力→1問
『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の学習と下記の模試の学習で代用します。また最後に黒本『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の2周目の際にまとめます。
標準ライブラリめぐりーpartⅡ→1問
『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の学習と下記の模試の学習で代用します。また最後に黒本『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の2周目の際にまとめます。
クラス→2問
『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の学習と下記の模試の学習で代用します。また最後に黒本『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の2周目の際にまとめます。
模擬試験
| 模試・教材 | 難易度 | 特徴・本番との比較 |
| DIVE INTO EXAM | ★☆☆〜★★☆ | 最も基礎的。本番の形式に慣れるのに最適で、難易度は本番と同等か、やや易しめです。 |
| ExamAPP(初級) | ★☆☆ | 非常に基本的な文法のみ。自信をつけるための最初のステップに最適です。 |
| 黒本(巻末模試) | ★★☆ | 最も本番に近い難易度と出題傾向です。 解説が非常に充実しており、これを完璧にするのが合格への最短ルートです。 |
| 本番試験 | ★★☆ | チュートリアルに忠実な出題ですが、一部に細かい仕様を問う問題が混ざります。 |
| ExamAPP(中級) | ★★☆〜★★★ | 本番と同等か、少し細かい知識を問われます。全問正解を目指したいレベルです。 |
| PyQ 模擬試験 | ★★★☆ | 基礎知識を正確に理解しているかを問う良問が多いです。本番よりも少しだけ捻った問題が含まれます。 |
| PRIME STUDY | ★★★★☆ | シリーズの中で最も難易度が高く、ひっかけ問題が多いです。ここで7割取れれば本番は安泰です。 |
| ExamAPP(上級) | ★★★★☆ | かなりマニアックな仕様や、実務でもあまり使わないような細かい挙動が問われます。満点を取れなくても焦る必要はありません。 |
模擬試験は複数回行いました。上の表は難易度が低い順から難しい順に並んでいますが、以下では行った順に列挙していきます。
基本的に黒本とチュートリアルを1周した段階で臨んでいます。模試は時間を計測して解いて、すぐに採点して復習、これを繰り返しています。ただしExam APPの上級は難易度が高すぎると判断して解いていません。
黒本の総仕上げ問題:1周目

まずは『徹底攻略Python 3 エンジニア認定[基礎試験]問題集』の最後の章の模試に取り掛かりました。結果は合格点に1点届かずでしたが、初めての模試で合格点付近を取れたことで自信がつきました。以下、復習です。
対話モードの1次プロンプトは>>>です。2次プロンプトは…です。関数内で定義されている変数は、関数の外側で定義したグローバル変数には値を直接代入できません。関数の外側と内側の変数は同名でも別の変数として扱われます。指定済みの引数に対しキーワード引数による際指定はできません。指定したキーワード引数が存在しない場合はTypeErrorが発生します。
リストとタプルは*を先頭につけると要素を位置引数に展開して関数に渡せます。ディクショナリは**を先頭につけるとキーワード引数として指定できます。短絡演算子において、andは左から評価して最初に偽になった評価結果が最終結果になり、orは左から評価して最初に真になった評価結果が最終結果となります。タプルにおいてtuple( )関数を用いる場合、その引数はリストなどの反復可能体である必要があります。
setに要素を追加する場合はadd( )メソッドを用います。append( )メソッドはリストの場合です。


この場合は、from .. load import *となります。なぜなら名前としても*が使えるからです。
テキストモードで読み書きの際には、r+
バイナリモードで新規に書き込む時、wb
バイナリモードで追加で書き込む時。ab
バイナリモードで読み込むときには、rbです。
for文の文法でinが抜けると構文エラーが起きます。except節での( )には例外をすべて列挙します。ValueErrorはint(times)で整数に変換できない値の時に起きます。


①はbirdsong = ga-ga-で、②はself.birdsong = coinです。
glob.findall()というメソッドはないので実行するとAttributeErrorが起きます。glob.glob("*.txt)とすれば、globモジュールについて、カレントディレクトリにある拡張子が、.txtであるファイル名のリストを取得できます。

このファイルを、python main.py --command = show tokyo osakaのように実行すると次のようになります。

reモジュールには正規表現を扱う関数が含まれます。re.subで対象文字列内で特定のパターンにマッチする部分を置換文字列に変換できます。


第2引数は、置換文字列、第3引数は文字列全体を示しています。第1引数により結果の形が決まります。
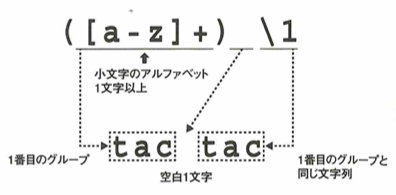
すなわち、tac tac をtacに置換します。するとtic tac toe になります。

この例では、文字列sで2回現れるtacを削除して出力します。結果はtic toe になります。
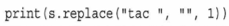
この例では、第3引数で変換回数を1回にすると、tic tac toeになります。

self.assertEqualの代わりにassertも使えますが、その場合は差異を確認できません。self.assertとかくと構文エラーになります。

textwrapモジュールのfill() 関数を用いると、width幅に収まるように整形します。,の後で改行されます。print関数やpprint関数はリストを対象とします。print("\n". join(text))では , が出力されません。
対話モードの入力履歴はデフォルトでは、.python_historyで保存されます。
ディープロ模試(1回目)
前回の黒本模試の復習を終えてすぐにディープロの模試に挑戦しました。30分で回答をして、結果は31/40=77.5%で合格点を取れました。ただし消去法による回答が多かったので要復習です。
ディープロの模試は以前にG検定の対策で使用したことがあり懐かしさを感じました。ちなみに模試は無料で行えます。模試ごとにランダムで40問選んで出題してくれ、素晴らしいサービスです。
reprlib.repr( ) はコンテナオブジェクトの出力の長さを減らし、同時にソートもする関数です。リストのー表記では、右端(右端の文字が−1に相当するので)の空白は0という認識が正しいです。sys.pathの初期化で参照しないものは、スクリプトが存在するフォルダのシンボリックリンク先です。

rangeは何も指定がないときは0から開始されます。コマンドライン引数を取得するためのモジュールは、sysです。
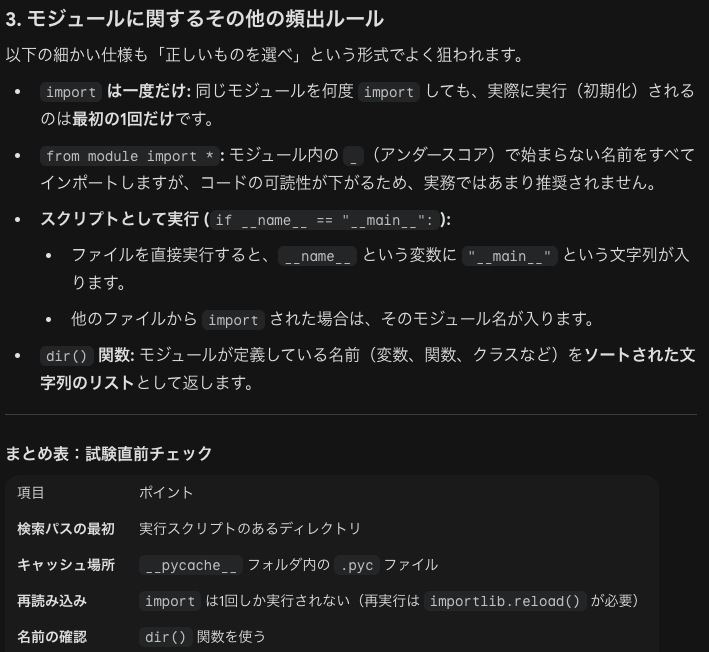
ビルドイン関数dir()について、モジュールが定義している名前を確認することができます。
removeは最初にある文字を消します。Pythonにおけるタブ補完機能はインタプリタ起動時に自動で有効になります。コンパイル済Pythonファイルの拡張子はpycです。パッケージとは、ドット区切りモジュール名を使ってpythonのモジュールを構築する方法です。関数内で変数に代入を行うと、その値がローカル変数のシンボル表に記録されます。Pythonの文法上、else節は必ず「全てのexcept節よりも後ろ」に書かなければならないと決まっています。タプルはimmutableであり、アンパッキングしてアクセスすることができます。


最後に要注意問題がありました。round(数値、桁数)では戻り値は浮動小数点数になります。
第1回PRIME STUDY模試
pythonでは変数や引数の宣言は必要ありません。Pythonにおいて、シャープ記号 # は基本的にコメントの開始を意味しますが、一つだけ例外があります。それは 「文字列(クォーテーションの中)に含まれている場合」 です。

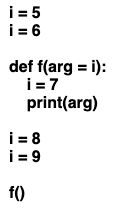

*の数は1個のときは位置引数、2個のときはキーワード引数です。つまりタプルとして、辞書として受け取る違いです。


ただし辞書は、キーはイミュータブルでないといけません。つまりリストをキーにしてはなりません。
Unicode順では大文字よりも小文字の方が後です。例えばH<eとなります。

with 文(コンテキストマネージャ)を使用してファイルを開くと、ブロックを抜けた際(エラー発生時も含む)に、自動的に f.close() が呼ばれ、ファイルが適切に閉じられます。
次の問題が難問です。

クラスに__init__()メソッドが定義してあると、新規生成されたインスタンスに対して自動的に__init__()メソッドがコールされます。__init__()メソッドに引数を与えることはできます。



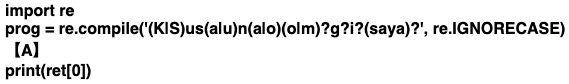

loggingモジュールのメッセージの優先度について、CRITICAL > ERROR > WARNING > INFO > DEBUGです。システム停止などの致命的な「CRITICAL」が最優先で、開発時のデバッグ情報である「DEBUG」が最も低くなります。
仮想環境の削除対象となるパッケージは複数指定できます。
第2回PRIME STUDY模試
Pythonは読みやすく、書きやすく、他のスクリプト言語(AwkやPerl)よりも汎用性が高いです。スクリプト名やそれ以降の引数群は、文字列のリストとして扱われます。これにアクセスするためにインポートすべきモジュール名は sys であり、リスト名は argv です。コマンドライン引数は文字列のリストになり、import sys をして sys.argv で取得します。対話型インタープリタでは文字列は引用符に囲まれ、特殊文字はバックスラッシュでエスケープされた状態で出力されます。print() 関数では...エスケープ文字や特殊文字がプリントされた状態で出力されます。raw文字列を作るには、単語の raw ではなく、引用符の前に r を一文字だけ置きます。range(Zen[0:5]) はエラーになります。range() の引数には、リストではなく「整数」を渡す必要があります。


この問題はかなりのひっかけ問題だと思います。見事に間違えました。
定義の順番は必ず *引数 が先、**引数 が後です。
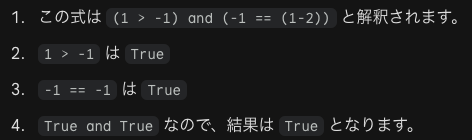
引数部分の : int や : str もすべてアノテーションに含まれます。アノテーションは引数と戻り値の両方に記述できる「注釈」のことです。__annotations__ という属性に保存される、という名前が問われることがあります。ネストしたリスト(行列)の縦と横を入れ替える「転置」に関するものにおいて、list(zip(matrix)) と、アスタリスク(*)を忘れるとエラーまたは意図しない結果になります。正しいコードは power = list(zip(*matrix))です。(-1, -10, -3, -4) > (-1, -2, -5)はFalseで、1 > -1 == (1-2)はTrueです。
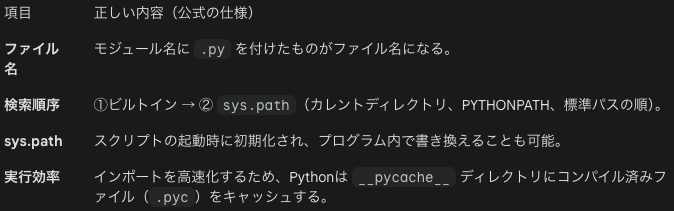
sys.path は、入力スクリプトのあるディレクトリ、PYTHONPATH、インストールごとのデフォルトで初期化されます。
例外のほとんどはプログラムでは処理されず、その結果はエラーメッセージにあらわれます。エラーメッセージの最終行には、NameError、TypeErrorなど例外の型が記されています。

次の問題は難問です。


次も難しいですが良問です。ポイントは次の通りです。まずはこれを覚えてから問題に移ります。




次はモジュールの問題です。


Pythonのインポートは 「どこから (from) 」「何を (import) 」 持ってくるかという順番で書きます。
from (モジュール名) import (クラス名) というルールに従います。したがって、from datetime import date となります。
loggingモジュールのメッセージの優先度として正しいものはどれか考えます。左から順に優先度が低いものとする場合、DEBUG、INFO、WARNING、ERROR、CRITICALです。

仮想環境 (venv) とセットで出題されることが多いので、python -m venv コマンドで環境を作った後に、これらの pip コマンドでパッケージを管理するという流れを意識しておくと完璧です。
第3回PRIME STUDY模試
for f in fruits[:]: ここで [:](スライス)を使っているため、ループは元のリストそのものではなく、その時点のコピーに対して行われます。つまり、ループは必ず「apple → kiwi → plum」の3回で固定されます。
else: は通常 if と同じ高さに書く必要があります。もし else を使うなら、一番下の「even number」の print 文を else: ブロックの中に入れなければなりません。continue があることで、それ以降の処理(偶数用のprint文)をスキップして、次のループ(次の数字)へ移動します。


関数注釈(アノテーション)はリストではなく 「辞書(dict)」 として __annotations__ 属性に格納されます。注釈自体は関数の他の部分に影響を与えることはありません(ただのメモ書きのようなものです)。
リスト内包表記 [a ** 3 for a in range(5)] は、map 関数を使って書き換えることができます。map(関数, イテラブル) は map オブジェクトを返すため、最終的にリストの形にするには list() で囲む必要があります。完成形:list(map(lambda a: a**3, range(5)))
ディクショナリに対する in や not in による判定の対象は『値』ではなく『キー』です。ディクショナリから「キー」と「値」を同時に取り出してループを回すには、items() メソッドを使います。例: for k, v in dict.items():


open()はファイルオブジェクトを返す関数です。open関数は第1引数にファイル名を、第2引数にモードを与えて使います。モードはファイルを読み込み専用で開くなら「r」、書き出し専用なら「w」、追加なら「a」、読み書き両用なら「r+」を指定します。
elseはエラーが一度も起きなかったときだけ実行されます。パーサ(構文解釈器)はエラー部に下線を引きません。
次の問題は本当に難しいです。


次の問題も難問です。






self.m() は「実行(呼び出し)」、m(self): は「定義」という違いを意識すると、ミスを防げます。

仮想環境を作成、管理するのに使われるスクリプトはpyvenvです。

PyQ:「Python3 エンジニア認定基礎試験」の模擬試験
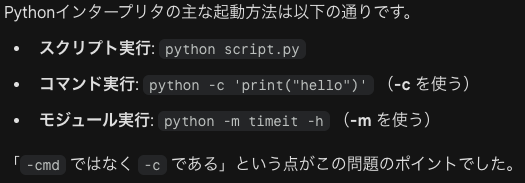
インタープリターを対話モードで起動すると、プロンプトが>>>と表示されます。インタープリターは、引数をつけて実行できます。この引数は、sysモジュールのargv属性で取得できます。 引数にソースファイル名を指定すると、そのファイルを実行します。さらに、python -m モジュール名とすると、モジュールのソースファイル名を完全な形で指定したかのように実行できます。
"""…"""や'''…'''のようにダブルクォーテーションやシングルクォーテーションを3つ使って囲めます。これを三重引用符といい、文字列内で直接改行できます。""…""のような記述はできません。位置, / ,位置またはキーワード, *, キーワードです。
ドキュメンテーション文字列の1行めは大文字で開始してピリオドで終わります。
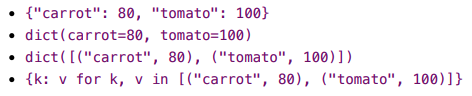
ディクショナリは、dict("carrot"=80, "tomato"=100)と書くことはできません。


NameErroeは存在しない名前を使おうとするとき、TypeErrorは期待する型と異なるとき、ValueErrorは期待する値と異なるとき、SyntaxErrorは文法間違いです。
raise 新しい例外 from 古い例外で例外の連鎖となります。

クラスPath2はクラスPath1を継承しています。このとき、Path1を基底クラス、Path2を派生クラスとい
います。pth1.join()を出力するとhome/taroになります。pth2.join()に出力について説明します。派生クラスのオブジェクトは、基底クラスのメソッドが使えます。 メソッドjoin()は、派生クラスのPath2に定義されていませんが、基底クラスのPath1に定義されています。そのため、pth2.join()を実行できます。メソッドinitで、pth2.sepを"\"に設定されているので、pth2.join()を出力するとusers\taroになります。
プログラム内で書かれている "\\" は「バックスラッシュ1本」を表すための書き方であることに注意しましょう。

次の問題は今までに出てないタイプの問題です。
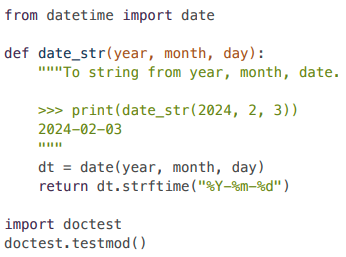
上記を実行すると、doctest.testmod()が、モジュール内の関数のドキュメンテーション文字列を調べま
す。具体的には、print(date_str(2024, 2, 3))を実行し、その出力が2024-02-03と同じかどうかをチェ
ックします。

デフォルトでは、WARNINGとERRORとCRITICALの関数で出力され、INFOとDEBUGの関数では出力されま
せん。


拡張されたインタープリターとして、bpythonやIPythonがあります。if文などのブロック内で改行しても、インデントが自動的に挿入されたりはしません。
ExamApp:基礎・初級
print文の前にインデントがないと「IndentationError」になります。文字列はインデックス指定ができます。len()はリストの要素数のカウントにも使えます。rangeの引数はカウントする回数を記述します。
関数の処理結果を関数の外で使う場合はreturnで返す必要があります。returnがない場合はNONEが還ります。



辞書の値の変更は可能ですが、キーの変更はできません。

変数そのものを削除するとNameErrorになります。set()関数で集合を作成する場合は、引数をリストで指定するか、タプルで指定します。

優先順に、比較演算子→not→and→orです。
構文エラーが発生すると最初にエラーを検知した箇所に^(キャレット)記号がつきます。例外エラーはTypeError, AttributeError, ZeroDivisionError, NameError, IndexErrorなどです。構文エラーはSyntaxError, IndentationErrorです。



想定外の例外が発生した場合にプログラムを終了する場合は、try文で判定して、sys.exit()で終わらせることができます。openyxlは pythonでは外部ライブラリです。

ExamApp:基礎・中級




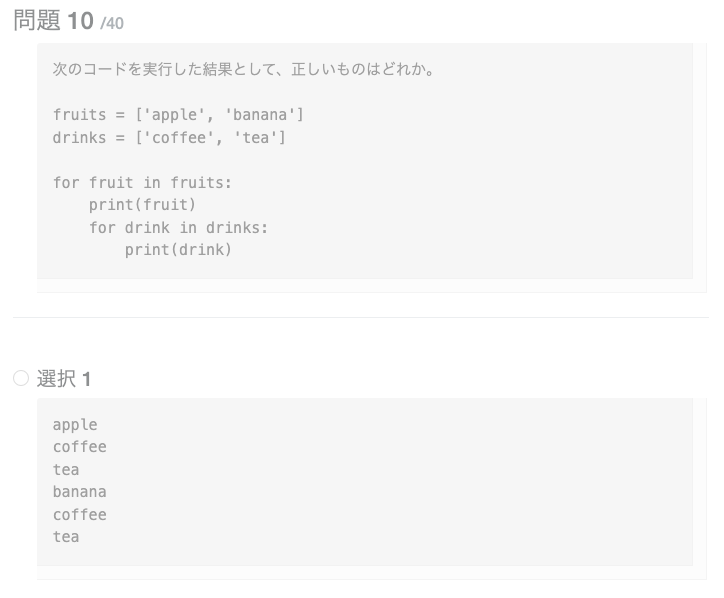
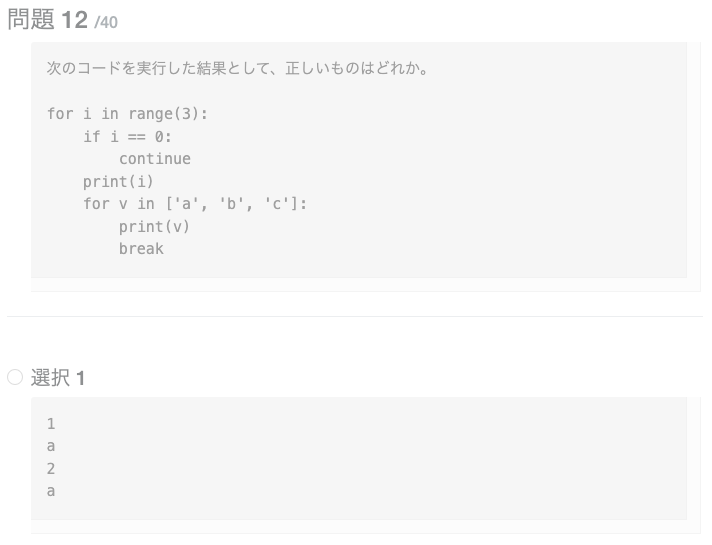
for, if文で代入した変数は、それぞれの文の外から参照できます。要素が1つのタプルを作るとき、最後にカンマを付けます。
Falseになるだけではエラーは表示されません。


if __name__ == '__main__':」は、インタープリタで関数が意図せず実行されないようにしたり、「python module.py」でfunc()を確実に実行するために記述します。読み書き両用はr+です。try文に複数のexcept節がある場合、一度の処理で実行されるexcept節は一つまでです。「ハンドラ」とは「except節で設定した処理」を指します。
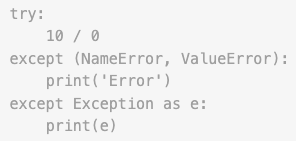

tryのelse節はtry節が例外を送出しなかった場合に実行されます。try文のexcept節は、try節から呼び出された関数で発生した例外も処理します。
難問です。


__init__メソッドは、インスタンス変数を初期化するために使います。「random.randint(a, b)」は、「a以上、b以下」の整数を返します。requestsは標準ライブラリではなく外部ライブラリで、インストールが必要です。emailという標準ライブラリはありますが、mailというライブラリはありません。アップグレードする際の記述は、「pip install --upgrade requests」か、「pip install -U requests」です。
ディープロ模試(2回目)
あれ?次は上級ではないのですか?
クラスとスコープの理解に限界を感じて、このまま上級に進んで混乱を増すより、ディープロで本番レベルの模試をこなして基礎的な箇所で穴がある箇所を減らしていく作業に入ろうと思いました。
IPythonはPythonの対話型インタプリタの中で存在するものです。バイナリデータレコードの処理を行うモジュールはstructです。コンパイル済Pythonファイルの拡張子はpycです。
黒本の総仕上げ問題:2周目
tuple( )関数の引数はリストなどの反復可能体です。
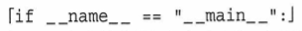





黒本(本番2日前)2周目の復習
1周目で飛ばした箇所で間違えた箇所を復習します。
対話モードを起動するとバージョン番号に続いて、ヘルプおよび著作権情報などを確認するコマンドが表示され、一次プロンプトが表示されます。
フォーマット演算子でbは2進数、xは16進数です。リストの要素を加えるときは.append(値)の他に、+=[値]もあります。sorted( )関数は昇順です。関数定義の最後には:を付けます。*はタプル、**は辞書。
docstringは__doc__という属性で参照できます。


setに要素を追加する方法ではadd( )メソッドでもできます。
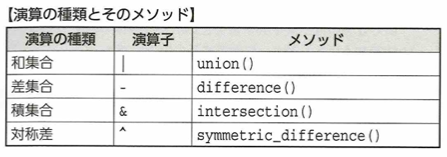

インポートされるファイルをモジュールといいます。import calendar、calendar.prmonth(2000,1)などとします。しかし関数のみをインポートする場合は、from calc import addなどとします。名前をすべてインポートする場合はfrom calc import * などとします。ただし_で始まらない名前すべてです。__all__があれば、そのリストの名前だけインポートされます。

__name__はモジュールの属性であり、モジュール名が自動で代入されます。メインモジュール(スクとリプトとして実行された.pyファイル)で実行している場合は、__main__が代入されます。

難問です。



次の問題は良問です。




modeの引数について、open(ファイル名、mode= モード )に対して、r+は読み書き両用です。wは新規、aは追記書き込みです。
loadやreadという組み込み関数はありません。fp.load( )というメソッドもありません。ただしread( )メソッドはあります。これはファイルの内容を読み込むメソッドです。fp.read( )とするとファイルの内容を取得できます。
open( )関数の返り値のファイルオブジェクトはファイル処理後に閉じる必要があります。閉じるにはclose( )メソッドを使用します。with文を使うと閉じる処理が自動化できます。例外発生時も使えます。
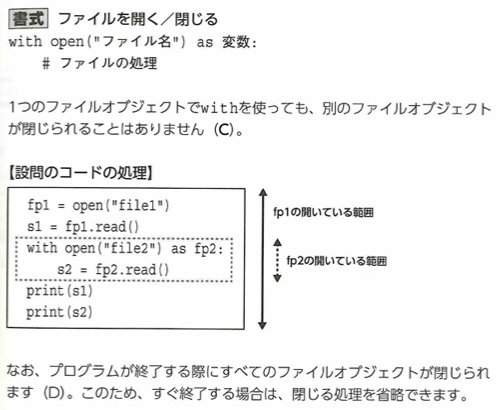
ファイルを1行ずつ読み込むのは、for s in fp: # 変数sに1行入れる です。
ファイルオブジェクトもリストと同様に反復可能体です。そのためfor文で繰り返すことができるのです。上の例ではfpをファイルオブジェクトとしています。fp.read( )が処理するのはファイル全体の文字列です。for s in fp.read( ): とすると1文字ずつの処理になります。1行ずつというときは、for s in fp:であり、for s in fp.readlines( ):やfor s in list(fp)も同じ意味です。
ファイルにデータを書き込む際は、write( )メソッドを使います。fp.write(文字列)とします。ただしdump,wrhiteなどという組み込み関数はありません。またfp.dump( )メソッドもありません。
JSON形式の書き込みは、json.dump( )メソッド、json.dumps( )という関数を使用できます。JSON形式の読み込みは、json.load( )メソッド、json.loads( )という関数を使用できます。これら2つは関数ですがメソッドです。


文法として正しくないと構文エラー(SyntaxError)が出ます。NameErrorは未定義の変数や関数を使用すると出ます。KeyErroρはディクショナリに存在しないキーを参照しようとすると出ます。ValueErrorはデータ型が合っていても値が不適切な場合に出ます。TypeErrorはデータ型が合っていない場合に出ます。

クリーンアップ動作は、例外発生の有無によらず実行する処理です。try節にfinally節を追加し、クリーンアップ動作を定義できます。
クラス名は各単語の頭文字を大文字にします。クラスはクラス変数、インスタンス変数、メソッドで構成されます。クラスから生成されたオブジェクトをインスタンスといいます。


クラスのインスタンス化は、duck=Duck( )です。クラス( )はインスタンスを返り値とする関数です。メソッド内にインスタンス変数と同名の変数がある場合、それらは別の変数として扱われます。


他のメソッドを呼び出す際は、メソッド名の先頭にself.を付けます。

定義済みのクラスを基にして別のクラスを作成することを継承といいます。元のクラスを基底クラス、継承先を派生クラスといいます。例えば、class Duck(Bird):です。type( )関数では判定を行うことはできません。instance( )関数はオブジェクトの型やクラスを判定する場合です。これは判定ができます。
python3エンジニア認定基礎試験の本番

本番では24/40を確実に取っておけば残り16問のうち期待値的には4問を正解するのでギリギリ合格点の28点に届くだろうという気持ちで挑みました。模試では合計11回挑戦して合格点を超えた回数が5回でしたので、かなり慎重に挑みました。本番はリラックスして受験することができ、35/40という成績で合格することができました!
よかったですね!
黒本→模試→チュートリアル→本番という順で学習をしました。この試験はチュートリアルで大事な部分が理解できるか?が問われていると合格して思いました。
試験の難易度は、ITパスポートより難しく基本情報技術者試験の科目Bより難しいことはないという感触でした。この試験を通して、 python3に対して少しだけ自信がつきました。挑戦することができて、良かったです。次は情報セキュリティマネジメント試験に1ヶ月以内に挑みます!

{kind=link}