.jpg)
2025年3月14日にデータサイエンティスト検定(リテラシーレベル)を受験して8割を超えることができました。また4月23日に合格発表があり無事に合格できましたので、ここまでの学習法などをシェアします。
近年注目されているデータサイエンスの名前がついた有名なデータサイエンティスト検定(リテラシーレベル)について学習記録を交えた対策記事になります。対策書として最もオーソドックスな『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』を用いた学習が間違いないです。

本記事は上記書籍の概要の学習記録および、DS検定の学習記録ですが、データエンジニアリングの分野は特にアウトプットが大事になります。アウトプットは『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』を用いた学習を合格者の多くは実践しています。

DS検定は合格ラインが8割(で各分野での足切りも噂されています)と高いため、合格者の間では以下のDS検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』まで学習しておいた方が良いとのことですのでご紹介いたします。
この教科書は随所に節末問題があり全部合わせると1つの模試になるくらいの量が掲載されております。また模試を除く最後の章では、合否に関わってくる100個の用語が適切に理解できているか?を試せる3択での語彙チェック問題が100問までついており、お得感が満載です。

また模試も大事です。上の3冊の書籍に付属している模試やネット上の模試などを駆使して合格を目指していきましょう!学習の進め方について、僕はリファレンスブック→黒本→緑本と進めていますが、緑本がリファレンスブックよりも大事な点をおさえるのに特化し問題量も多いことから、緑本を先に学習しておくと学習効率が高まって良いです。
DS検定リテラシーレベルの概要
データサイエンティスト検定リテラシーレベルとは、スキルレベルとしては見習いレベルであり、プロジェクトの担当テーマを扱える程度です。スキルは全部で203個あり、それに、数理・データサイネス・AI(リテラシーレベル)モデルカリキュラムの内容を加えたものが試験範囲となっています。
青本の著者であるヤン先生の著作『データサイエンティスト検定[リテラシーレベル][徹底解説+良質問題+模試(PDF)] 最強の合格テキスト』によりますと、2024年の秋の試験から試験範囲に生成AIとLLMの内容が目立ってきているとのことです。そのためG検定(対策記事はこちら)を取得もしくは学習している方は有利になります。
.jpg)
2013年度に設立されたデータサイエンティスト協会が2015年に発表したデータサイエンティストスキルチェックリストに基づき発足したデータサイエンティスト検定リテラシーレベルは2021年4月に誕生したまだ新しい検定ですが、今後の需要はさらに増していくと思われます。なぜならこのチェックリストを構成する、ビジネス力、データサイエンス力、データエンジニアリング力はこの後の社会で重宝されていくと確信していくからです。
試験は年3回行われます。受験料は一般が11000円で学生が5500円になります。100問の選択問題を100分で行い、合格ラインが約80%と合格率が高めな検定試験です。難問が数問混じっていると公表されています。またひっかけ問題が目立つので注意が必要です。試験形式はCBTになります。
データサイエンス力
数学的理解
線形代数基礎
ベクトルの内積で、全ての成分が1のベクトルを用いることにより算術平均を表すことができます。行列において単位行列はEよりIの方の記号で表します。固有値や固有ベクトルはデータサイエンスでは主成分分析などで用います。具体的には高次元のデータに対してより低い次元でデータの性質を説明するときに使います。
微分・積分基礎
偏微分においてはナブラ記号を用いて∇f=(∂f/∂x_1,…,∂f/∂x_n)表記に慣れましょう。このナブラは機械学習に登場する勾配(勾配ベクトル)で、勾配の向きは関数fの値が最も大きく増加する方向で、十分小さな定数Cに対して、勾配の向きに距離C進むと関数の値はC‖∇f‖程度増加します。
(d/dx)F(x)=f(x)を微積分学の基本定理と言います。
集合論基礎
集合についてPythonのプログラムとの対応を覚えます。和集合、積集合、差集合、対称差集合を、ぞれぞれ|、&、-、^で記述します。補集合ついては、Pythonに演算子は準備されていません。またこれら5つの集合の種類を論理演算と対応させると、それぞれA OR B、A AND B、A AND NOT B、A XOR B、NOT Aとなります。ちなみに対称差集合は△記号で表現します。
科学的解析の基礎
統計数理基礎
DS検定では条件付き確率を統計検定と同じような記号で表記します。また右に裾を引いた(右に裾が重い)分布は小さい順に、最頻値→中央値→平均値となります。また第1四分位数を25パーセンタイルなどと表現します。確率分布は二項分布、ポアソン分布、正規分布、指数分布、カイ2乗分布(誤差の2乗和がこの分布によく従う)が範囲です。正規分布の期待値と分散や標準化も試験の範囲です。因果→相関ですが、逆は偽です。これは疑似相関があるためです。通常の相関係数をピアソンの相関係数(ピアソンの積率相関は量的データのみ計算可能)と言います。スピアマンの順位相関は質的データである順位データに対して、2つの変数の単調関係を示します。単調関係とは、一方の変数が増加するとき、他方の変数が増加し続ける度合いです。
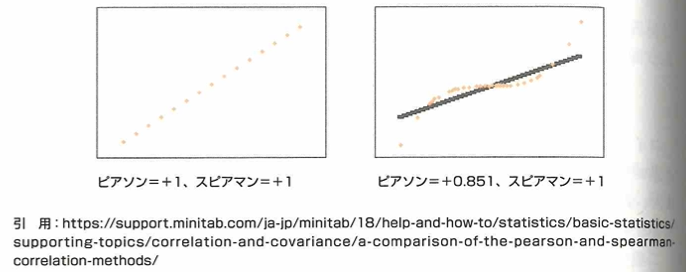
右図ではデータが3次曲線であり、直線関係(厳密な線形関係)でないのでピアソンの積率相関は1を下回りますが、スピアマンの順位相関は、値の増加の幅を気にせずに単調関係のみを評価するので1のまま不変です。
尺度について量的データには比例尺度(長さや絶対温度、質量など絶対的なゼロ点を持つデータの尺度)と間隔尺度(℃などで倍率の計算ができない尺度)があります。質的データには、順序尺度(等級や満足度のような分類や種類を区別するラベルとしてのデータ)と名義尺度(子供を0、成人を1とするなど内容区別のためだけに数値が与えられているデータ尺度)があります。
片対数グラフとは、yとxが指数関数の関係にある際に使い勝手の良いグラフです。
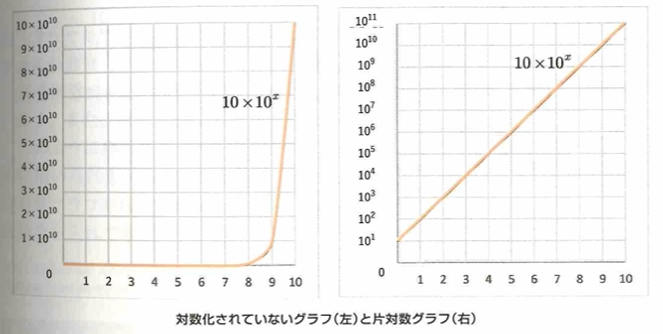
次に似た考えを用いて両対数グラフを考えます。このときにy軸を10を底とする常用対数を取ります。つまりy=B×A^xのときに両辺に常用対数を取ると、log_10(y)=Alog_10(x)+log_10(B)となり、左辺をあらためてyとし、右辺のlog_10(x)をあらためてxとすると、y=Ax+B’の形になります。
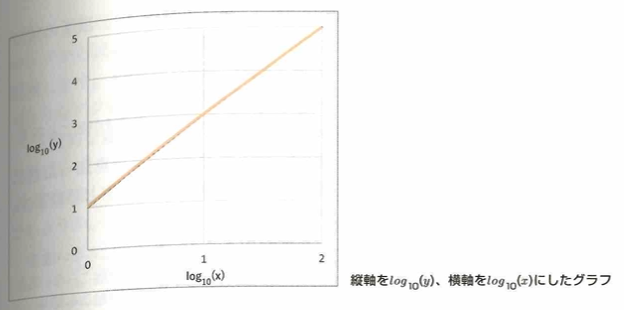
統計検定などでたまに見かける内容に片対数グラフ(縦軸だけ対数をとる)や両対数グラフという名前がついているだけに過ぎませんが、面白いですね。
ベイズの定理では、迷惑メールに関する問題なども解けるようにしておきましょう。
推定・検定
記述統計学は、特定の集団におけるデータを表やグラフや統計量から読み解いて考察するものです。推測統計学とは、無作為に集められたデータから母集団の特徴や情報を推測する統計学です。また点推定の欠点は誤差がわからないことです。DS検定では、検出力のことを検定力という表記をします。検定力が低い状況で統計的仮説検定を行うことはあまり適切でないことに注意しましょう。検定関連では、ウェルチのt検定まで出題されますので注意しましょう。
アソシエーション分析
アソシエーション分析など、DS検定では統計検定1級を学習していても聞き慣れない単語が出てきますので、注意して学習しましょう!
共起性を測るために共起頻度を把握します。これは、XとYの両方が起きている事象の数です。支持度は、全事象の中で、XとYが同時に起こる回数つまり共起頻度の割合です。信頼度は事象Xが起こった条件での事象Yが起きる割合です。リフト値は事象Xが起こった条件のもとで事象Yも起こる確率を、事象Yが起こった確率で割った値です。
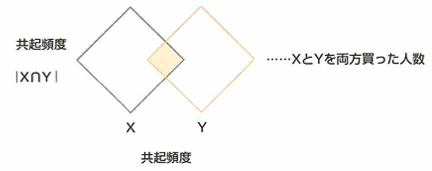
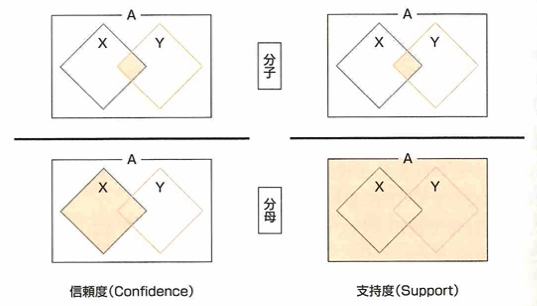
このような概念はアソシエーション分析という教師なし学習の手法で用います。例えば通販サイトにおける「Xを買った人は、Yも買っている」発見をもとにしたレコメンドとして用います。
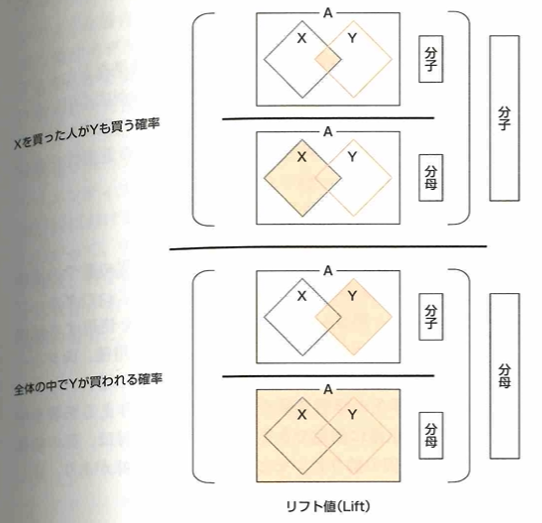
レコメンドと共起頻度の大きな違いは、XとYに方向性があるかないかです。共起頻度の指標ではXとYを置き換えられますが、レコメンドでは、XとYに方向性があります。
因果推論
処置群とは実験群のことで、対照群と合わせて実験計画などで用います。交絡因子とは共変量のことです。ある変数が他の変数に影響を与える影響を知りたい場合、影響を受けると仮定する変数をアウトカム、影響を与えると仮定する変数を要因(介入変数、暴露因子)と言います。交絡因子とは、アウトカムに影響を与え、要因と関係があり、要因とアウトカムの中間因子でないとされます。中間因子とは要因とアウトカムの中間に存在する因子のことです。
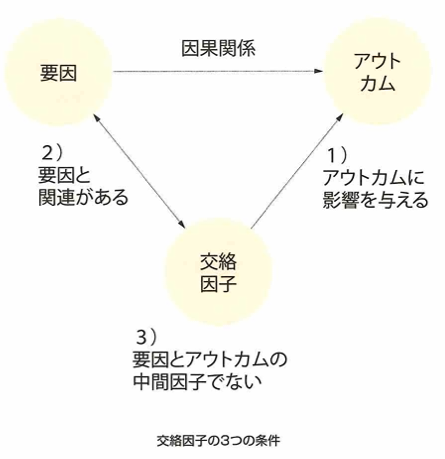
中間因子の働きにより、因果効果を誤る例は下記です。喫煙が中間因子なら上の→の線上にあることが前提と考えています。
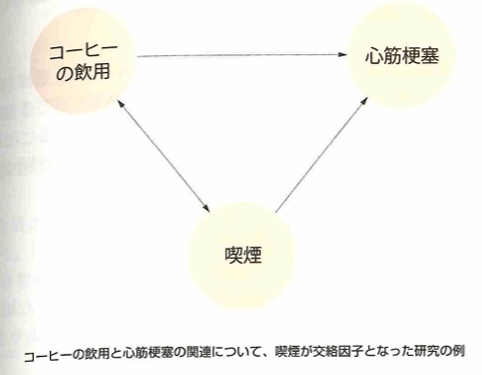
「心筋梗塞と喫煙に関係がある」を自明とした場合、コーヒー飲用が心筋梗塞に影響を与える(因果効果がある)と仮説を立てたとき、上図の関係から、交絡因子の喫煙により、コーヒーの飲用が心筋梗塞に影響を与える(因果効果がある)…☆と誤認する可能性があります。交絡因子とは、アウトカムに影響を与え、要因と関係があり、要因とアウトカムの中間因子でない、つまり最後の部分が大事で、中間因子とは要因とアウトカムの中間に存在する因子のことですので、要因が中間因子に影響し、中間因子がアウトカムに影響する構造になっていないことが交絡因子の条件の1つなので、このコーヒーの例では喫煙が交絡因子であることが、☆の誤認の原因となっています。
この部分は実験計画法の箇所でも詳しくは触れていない部分ですので重要な概念だと感じます。
交絡因子があると因果関係の判断を誤りやすいのですね。『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』の内容の例はこのようにハッとさせられる内容が多いことも特徴的ですね!
選択バイアスとは、分析対象として選ばれた人とそうでない人の間に存在する特性の違いによって生じる系統的な誤差を意味し、選択バイアスが存在するとデータ入手時点で歪みが発生していることになります。選択バイアスには脱落バイアス、欠測データバイアス、自己選択バイアスなどがあります。脱落バイアスは時間的な追跡があるときに途中で対象者が離脱してしまったときなどに生じます。欠測データバイアスは、欠測を含むデータか否かでデータ入手時点で既に歪みが発生してしまうバイアスです。自己選択バイアスは治験などで健康に自信がある人などが多く集まってしまうことによる既に形成された歪みが発生してしまっているバイアスのことです。
データの理解・検証
データ理解
データ分析のプロセスは、データ確認およびデータ構造把握→データクレンジングつまりデータ加工と整形→基本集計(各種クロス集計)→詳細分析(モデル作成、機械学習の実行)です。
時系列データにおいて、トレンドとは、細かな変動を除いた全体のデータの傾向です。移動平均において間隔を広げると長期傾向を掴めますが細かい傾向変化を掴むことが難しくなります。周期性の概念も大事です。移動平均の間隔を周期性の周期に合わせることも大事です。周期を特定するために自己相関分析や偏自己相関分析があります。前者は、一連の観測値が、それ自体のラグとどの程度相関しているかを分析するもので、後者は相関を見たいもの以外の影響(例えばt期とtーk期との関係を見たい場合に、tーk+1、…、tー1期の影響)を取り除いて分析するものです。
時系列データ同士の回帰分析において、見せかけの回帰に注意しましょう。以下の2つのランダム変数を考えます。
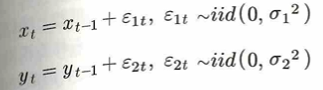
ここで、次のような回帰モデルを考えると、2変数の間に有意な関係があるような結果が出ることがあります。
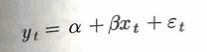
この見せかけの回帰の対策として、ラグ変数を含めた回帰や、差分を取った回帰などが考えられます。
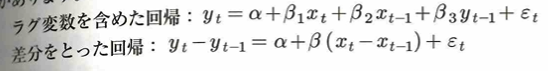
詳しくは統計検定1級の経済分野方面での名著の沖本本『経済・ファイナンスデータの計量時系列分析』に掲載されています。

データ準備
サンプリング
標本により得られる推定値と母集団から得られる値との差を標本誤差といいます。この標本誤差を算出することはできないので、標準誤差という統計量を用いることで確率的に評価します。つまり標準誤差が標本調査結果の信頼性を表します。アンケート調査において、1回のアンケートの1回を標本数やサンプル数といい、アンケートの被験者の数をサンプルサイズと言います。標準誤差は次の式で求められます。nは標本のサンプルサイズです。

標本誤差は正しい抽出法により母集団の特徴が反映されると期待される標本で生じる誤差ですが、サンプリングバイアス(バイアス)とは、不適切な抽出方法により母集団の特徴が反映されていない標本が抽出されることになります。
実験計画法とは1920年代にフィッシャーが開発したものです。フィッシャーの3原則とは、反復(いくつかの水準や処理などについて実験を繰り返す)と無作為化(実験の時間や空間など、結果に影響を与えると考えられる条件を無作為に入れ替える)と局所管理(実験の時間や空間など、結果に影響を与えると考えられる条件を局所化して実験する)です。この実験計画法という統計手法を用いる分析方法に分散分析があります。その他には最適計画や、シミュレーション実験があります。

DS検定の内容を大幅に逸脱していますが、上で述べた最適計画の内容が応答曲面法の一種として掲載されています。D最適化計画などの統計検定1級理工学分野相当の高難易度の内容を解説している日本語の本は本書しか見たことがありません。僕も先日(2025/2)に購入しました。
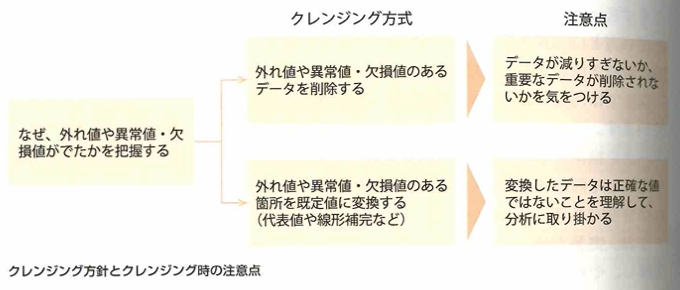
データクレンジング
外れ値の中で外れている理由が判明しているものを異常値と言います。欠損値は欠測値や欠落値とも呼ばれます。
データ加工
データの標準化において標準化後は平均0、分散1となります。データを一定のルールに従って変形し、扱いやすくする加工処理をスケーリング、尺度の変更とも呼ばれます。正規化とは、データの最大値と最小値をそれぞれ1と0にする加工処理で、最大値と最小値が決まっている場合に有効な手法です。
特徴量エンジニアリング
良い特徴量はデータの特徴を反映し、モデルの改善に役立てられます。二値化や離散化は実務的観点から意味を持つ場合に実施されることがあります。ある閾値について二値や多値に分ける場合や、ビニングという区間ごとにグループ化して等間隔や分位点で分割する方法があります。対数変換や一般化したBox -Cox変換やYeo -Johonson変換もあります。交互作用特徴量の作成は、変数間に線形では見れない関係がある場合に実際されます。
データ可視化
方向性定義
データの可視化は探索目的、検証目的、伝達目的があります。
軸出し
データ可視化における層化とは、比較して可視化したい分類別に分けることを言います。どのような属性で分けると差がくっきり浮かび上がるか、その属性での差を見ることで何がわかるかといった仮説が、層化する際の比較軸の候補になります。
データ加工
アンサンブル平均とは同一条件下におけるデータの集合平均です。
表現・実装技法
データインク比は、データインク比=データインク/総インクで表現します。データインクは情報量をもつインクで、その要素がなくなるとチャートのメッセージが変わってしまう、失われてしまうインクです。データインク比はチャートジャンクというグラフの過剰なビジュアル表現を減らす基本方針です。データインク比は0〜1で、1に近いほど良いチャートです。データ濃度はデータ濃度=画面上のデータポイントの数/データを表示するディスプレイの面積です。画面の単位面積あたりの情報量を示し、値が高いほど良いグラフです。ただしどちらの手法でも過剰に高めようとすると、かえって何がメッセージか不明確になります。
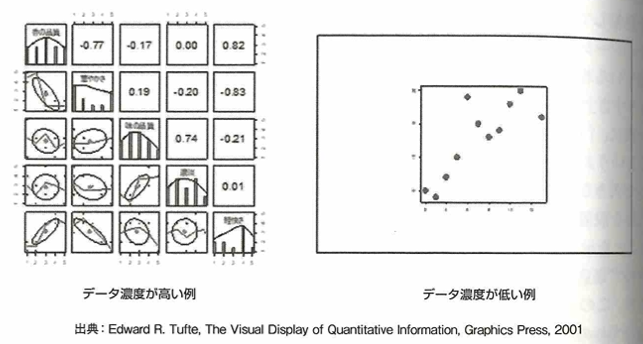
3次元の情報を2次元に付加する可視化の方法で、平行プロット、散布図行列、ヒートマップをおさえます。
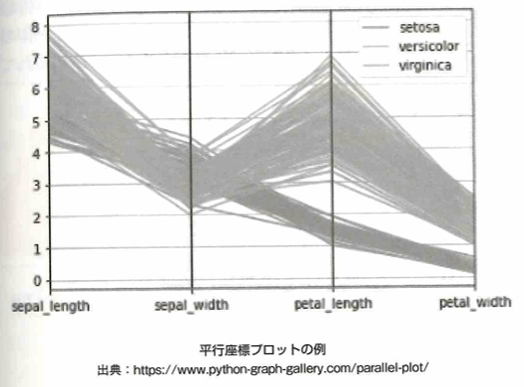
上図のように、n変量のデータ表示では、垂直な等間隔なn本の平行線で構成される背景が描写されます。折れ線グラフと似ていますが、折れ線グラフは横軸の順番に意味がありますが、並行座標プロットでは順番に意味はありません。
意味抽出
外れ値の判定法として、箱ヒゲ図を用いる方法があります。第1四分位数ー3×四分位偏差より小さいものや、第3四分位数+3×四分位偏差より大きい、つまり下限境界点と上限境界点からも外れた値が外れ値です。
モデル化
回帰・分類
目的変数と説明変数を標準化してから実行した重回帰分析から得られた回帰係数を標準偏回帰係数と言います。目的変数の実測値と予測値の相関係数を重相関係数と言います。これは0から1の値になります。これを2乗した値が決定係数です。またロジスティック回帰分析も大事です。
統計的評価
2値分類問題において、真陽性率(TPR)と偽陽性率(FPR)を用いてROC曲線を考えて、面積AUCまで考えます。
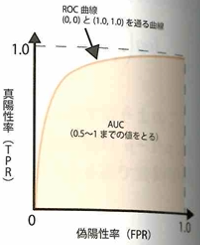
TPRは実測値が正例のうち予測値も正例であった割合で、FPRは実測値が負例で予測値が正例の割合です。モデルの精度が100%のとき、ROC曲線は両端点を通る直線となり、AUCは1になります。下記の混同行列を意識すると理解しやすいです。
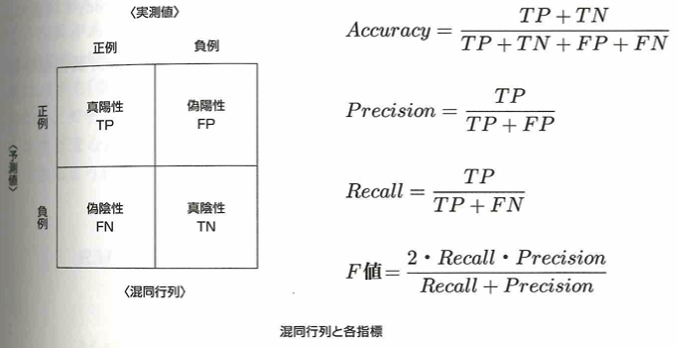
F値はRecall(再現率)とPrecision(適合率)の調和平均になります。これら2つのものは互いにトレードオフの関係です。ちなみにAccuracyは正解率です。ここまでは二値でしたが、多値分類の評価については、macro平均(クラスごとに評価指標を計算した後に平均する)、不均衡の場合は各クラスに重みをつけた重み付き平均を用います。micro平均は全予測のうち正しく予測できた割合を指すので、Accuracyと同義です。
平均平方二乗誤差(RMSE)や平均絶対誤差(MAE)、誤差率を測るMAPE、決定係数も大切です。
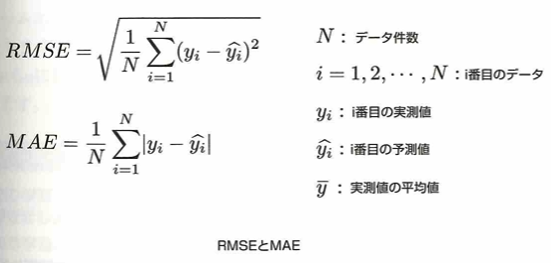
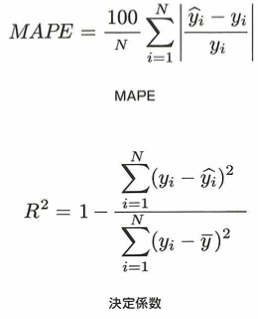
MAPEなどは統計検定でも出てこないので所見になりますね。
機械学習
教師あり学習において、特徴量(説明変数)と目的変数の関係性をモデルにより学習します。分類とは、目的変数がカテゴリ値などの質的変数を予測することで、回帰とは連続値である目的変数を予測することです。手法は、線形回帰、ロジスティック回帰、k近傍方、サポートベクターマシン、ニューラルネットワーク、決定木、ランダムフォレスト、勾配ブースティングなどです。教師なし学習はクラスタリングなどを用います。階層型と非階層型に分けられ、後者にはk-means法などがあります。強化学習は、与えられた環境の中で報酬が最大になるようにエージェントが行動を繰り返すことでモデルを構築します。方策反復法と価値反復法に分けることができます。AlphaGoに採用される深層学習と組み合わされたDeep Q-Network(DQN)などがあります。
機械学習により、分類問題、予測問題、クラスタリング、異常検知などが期待できます。教師あり学習の欠点は正解データの数が少なかったり正確性がないとダメになるところです。また正解データを用意する際にコストがかかる点などもデメリットです。教師なし学習はGANなどもあります。どの特徴量を選ぶかで結果が変わりますので探索的に結果を解釈し妥当性を判断しないといけません。
過学習とは、学習回数が増えるにつれて、訓練データの誤差が減少するのに対し、未知データに対する予測誤差である汎化誤差が増加する状態です。過学習は訓練データ数に比べてモデルが複雑で自由度が高い(説明変数が多い)時に発生し、未知データを安定して予測できない事態が生じます。
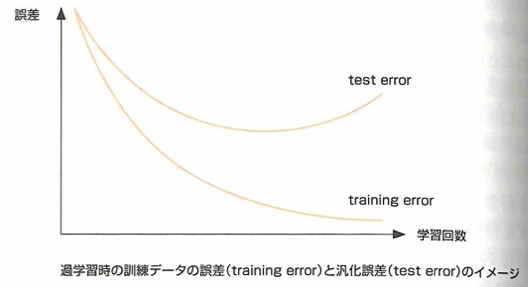
過学習を防ぐには訓練データ数を増やす、単純モデルに変更する、正則化する(モデルの煩雑さに罰則をかけ、複雑さを抑える)、学習方法として交差検証法を用いる、学習の早期打ち切りをするなどがあります。過学習の反対の状態を未学習、アンダーフィッティング、過少適合(別名は過小学習)と言います。これは訓練データにも未知データにも適合しない状態です。
次元の呪いとは、特徴量が増えることによりデータの次元が増えるので指数関数的に計算量が増加し、解決したい問題の解決を阻むことです。分類問題などで発生し、距離の計算をした比較が難しくなり想定したクラスタを作るのが困難になります。次元の呪いの解消には、特徴量選択、次元圧縮などがあります。教師あり学習では正則化などのテクニックで次元の呪いを回避できますが、教師なし学習では回避が難しいので、最初からむやみに次元を増やしすぎないことが大事です。
教師あり学習で精度の高い機械学習モデルを構築するために大量の教師データが必要になります。そこで教師データ数が不足する際に、正解に相当する出力値のついていない教師なしデータに対して、正解を付与して教師データを作るアノテーションを行う必要があります。機械学習を用いたチャットボットの回答精度を上げるため、テキストに使われる単語の中で解答精度の向上に重要と判断した単語を意味づけするタグ付けと言われるアノテーションを行います。画像や映像の分析では、タグ付けに加えて、画像の範囲を特定する4点の座標を指定するバウンディングボックスと言われるアノテーションが行われます。アノテーションは人手で行う方法や半教師あり学習、アクティブラーニングなどがあります。前者は一部の正解を付与した教師データと大量の教師なしデータを組み合わせて、教師なしデータに対する推論結果を得て、機械学習モデルによる半自動的なアノテーションを行います。後者は、前半までは前者と同じで、残りの大量の教師なしデータのデータの中から機械学習モデルの学習に効果的なデータを抽出し、そのデータに対して人が正解を付与し、教師データを増やしていく方法です。
バイアスが入った状態でのモデルの出力結果のことを、「モデルの出力が差別的な振る舞いをしている」と表現します。学習の段階で特徴量からセンシティブ属性を除いたり、層化抽出を行ってデータの偏りの緩和を行うとともに、モデル検証時に、センシティブ属性ごとの予測値の分布や精度を確認し、結果として差別的な振る舞いとなっていないか検証することが重要になります。
透明性の原則ではAIネットワークシステムの動作の説明可能性および検証可能性を確保することとしています。説明可能性の確保の方法は、大域的な説明と局所的な説明の2つに分類できます。大域的な説明は学習済みモデルがどのようにして予測するかモデル単位で説明する方法です。局所的な説明は、機械学習で構築した複雑なモデルへの特定の入力で得られた予測結果やその予測プロセスを根拠に説明する方法です。
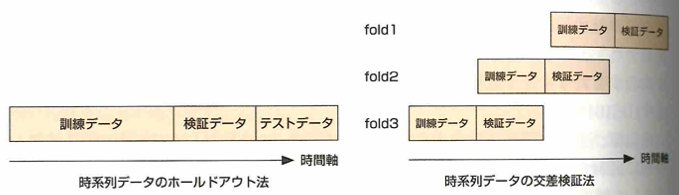
モデルの汎化性能(未知データにも高い精度で出力できる性質や能力のこと)を高める方法は、ホールドアウト法と交差検証法があります。ホールドアウト法は、データセットを2か3つに分類します。3つの場合は訓練データ:検証データ:テストデータ=7:2:1などの割合で分類します。生成した訓練データで機械学習モデルを構築し、検証データでモデルの評価指標を最大化できるようにパラメータチューニングを行い、テストデータを用いてモデルの汎化性能を確認します。データに偏りがない場合はホールドアウト法で良いですが、そうでない場合は問題が発生します。交差検証法は、テストデータを除外したデータセットをランダムにk個のブロックに分割し、そのうちの1つを検証データ、残りのk-1個を訓練データとして精度を評価します。これをk回行って平均化するのがk-fold交差検証法です。
時系列データを用いて機械学習のモデルを構築するとき、単純にホールドアウト法や交差検証法を行うと、検証データと同じ期間のデータでモデルを学習できてしまい、モデルの性能を過大評価してしまいます。これは時系列データが時間的に近いレコードほどデータの傾向も似ている性質があるためです。ここで時系列データに対応した交差検証法の考え方を用います。訓練データは検証データより未来のデータを含めないようにすることです。
機械学習モデルは、データ構成の変化により、学習完了後から精度が劣化します。データ構成の変化として、コンセプトドリフトやデータドリフトがあります。コンセプトドリフトは、目的変数の概念が変化する場合に発生します。データドリフトはモデルの特徴量の分布が学習時から変化した場合に発生します。モデルの精度劣化を防ぐため、データドリフトの検知、モデル精度その監視が運用時には必要です。これらはMLOps(Machine Learning Operations)において運用上欠かせない要素で、モデル精度が劣化していると確認できたら関係者にアラート通知する仕組みが大事です。
基本的構造を持つニューラルネットワークは入力層、中間層、出力層からなるパーセプトロンという構造を有する学習モデルです。1つのパーセプトロンは入力値に対して重みづけ総和を計算する部分と、出力値を決定する活性化関数から構成されます。
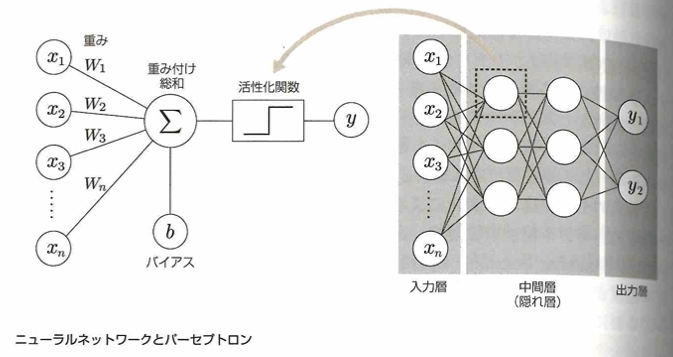
中間層を複数構成して多層にしたものを深層学習(ディープラーニング)となります。入力層は欠損値を扱えません。標準化した上で入力します。中間層は、ReLU関数などの活性化関数を用います。出力層ではタスクに合わせた活性化関数を用います。回帰なら恒等関数、二値分類ならシグモイド関数、多値分類ならソフトマックス関数を用います。ニューラルネットワークの学習は、出力層から得られた予測値と実測値(教師データ)との差を誤差とし、誤差の操作を損失関数として求め、損失関数を最小化するように学習します。損失関数の値をもとに重みとバイアスを更新し、更新された重みとバイアスを用いて再び予測し、損失関数の最小化を行うよう重みの更新を繰り返す誤差逆伝播法を用います。各層の重みを更新しながら誤差を最小化していくので、勾配(損失関数を重みで微分した値)が用いられます。出力層から入力層に向けて勾配が掛け合わされていくので、各層の勾配で小さい値が続くと、入力層付近の勾配が0になり、学習がうまく進まなくなってしまいます。これが勾配消失問題で、浅い層のニューラルネットワークではあまり深刻な問題ではありませんが、対策としては中間層の活性化関数にReLU関数を用いることが一般的です。
決定木は、ある特徴量が閾値以上か否かで境界を分割していく手法で、境界面は非線形になります。汎化性能が低いので、ランダムフォレストや勾配ブースティングなどのアンサンブル学習モデルを使用することが一般的です。ランダムフォレストは、データの一部をサンプリングしたデータ(特徴量もサンプリングします)でそれぞれ学習し、その多数決(平均)を予測値とするモデルです。勾配ブースティングは、現状のモデルの残差を予測し、それらを足し合わせた値(最初の予測値+残差の和)が教師データに近づくように学習します。勾配ブースティングにサンプリングや正則化などの改善をしたモデルが、XGBoostやLightGBMです。これらのモデルはパラメータ数が多く、ライブラリを使用する際は値の設定に注意します。max_depthは木の深さを意味し、大きい値ほど深く、分割ルールが増えます。そのため過学習を起こす場合があります。決定木系のモデルはインプットデータの欠損値の他やスケーリングなどの前処理をする必要がないので、分析の初手で使用されることが多いです。結果の解釈は、特徴量ごとに分割に使用された回数や目的関数の改善の寄与度を集計することで、各特徴量の重要度を計算できます。精度を向上させる局面では、分割に使用された回数よりも目的関数の改善の寄与度を確認します。
多くのデータが集められない場合に、プライバシー強化技術(PETs)という問題を生じさせないで実行可能な分析技術が開発されています。連合学習はその1つです。
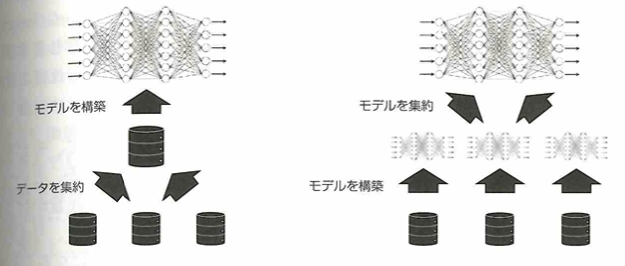
予測能力の高いモデル作成には、データの改善とモデルの構築手法の改善があります。データの改善はデータ量の増加、データの質を高めることが大事です。モデルの構築手法は、アルゴリズムの選択、特徴量エンジニアリングが大事です。
深層学習
ニューラルネットワークの層を深くしてモデルの表現力を豊かにし、勾配消失問題をある程度解消したモデルを深層学習といます。画像、音声などの非構造化データに対して適用され、層を深くすることで、さまざまな特徴抽出が可能です。人間が特徴量を定義する必要がなく、モデルが大量の訓練データから特徴量を自動的に抽出します。2012年にGoogleが深層学習を用いて、猫と教えることなく、猫を認識できました。そして人間の認識精度を超えることが多々あります。ILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像認識の世界大会で、2015年にマイクロソフトが人間の目の精度を超える深層学習モデルを開発し、技術的なブレクスルーが起きました。2020年にOpenAIがGRT-3を発表しました。深層学習モデルは学習済みモデルとして公開されているものもあり、ダウンロードしてそのまま使用でき、重みの一部を取り出して別のタスクとして転移学習などで活用できます。
分析の際には種類によらず同じアルゴリズムを適用できるように、最終的にはテンソルの集まりにします。画像はピクセルごとに色を表す数値に、音声は一定の時間ごとに音の振幅を数値に、テキストは文を単語に区切り単語の出現状況を数値に変換します。このような数値変換したデータでも、データ生成、数値の持つ意味が異なるデータ同士の場合は、両者を合わせて取り扱うことが難しいです。この画像、音声、テキストなどの種類をモダリティと言います。これらは別のモダリティと言えます。人間が認知できないだけでネットワークグラフのデータなど、別のモダリティを表すことができるデータもあります。データ分析上、単純に合わせることができず、異なった取り扱いをする必要のあるデータの違いがデータサイエンスやAIにおけるモダリティとなります。モダリティが異なれば計算機上でのデータ処理方法も異なります。近年では、複数のモダリティを同時に扱えるマルチモーダルモデルが開発されています。大規模言語モデルの登場以降に激しく加速しました。テキストで指示して画像を生成するモデルをはじめとして、多様なモダリティをつなぐモデルが開発されています。
時系列解析
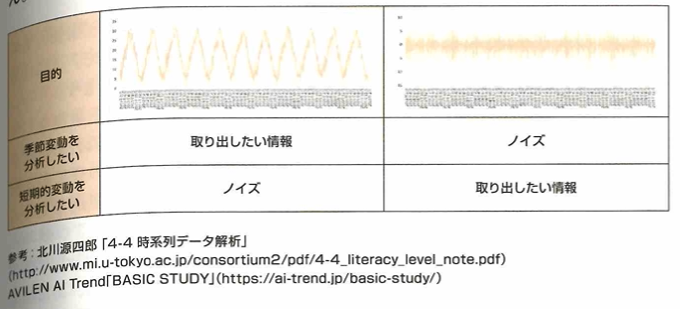
トレンド(傾向変動)、季節成分(季節変動)、周期性(循環変動)があります。季節変動以外の周期変動を周期性と言います。また、もとの時系列データから傾向変動や季節変動を除去して残った変動を短期的変動があります。これは階差を用いて求めます。これにより外れ値を見つけられます。ノイズ(不規則変動)とは取り出したい情報以外の不要な情報です。
クラスタリング
教師あり学習は、ロジスティック回帰、サポートベクターマシン、決定木(分類)があります。教師なし学習は、クラスタリングがあり代表的な手法として、デンドログラムを作成する階層クラスタリングや、k-means法などによる非階層クラスタリングがあります。
ネットワーク分析
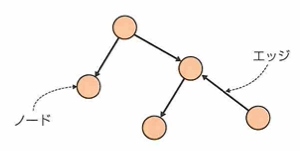
有向グラフと無向グラフがあります。次数とはノードに接続するエッジの数です。重みとはノード間の関係の程度を表す時に使います。その際はエッジに重みという数値を付加します。都市間の移動の所要時間などに使います。
モデル利活用
レコメンド
コンテンツベースフィルタリングと協調フィルタリングがあります。コンテンツベースフィルタリングは、アイテム自体の特性に焦点を合わせたアプローチです。新規ユーザーに対しても有効です。しかし新ジャンルなどには難しいです。
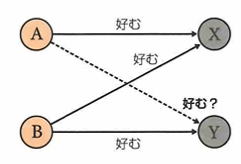
協調フィルタリングは2種類あります。1つはユーザーベースで、他方はアイテムベースです。ユーザーベースでは、類似した評価パターンを持つユーザー同士を見つけ出し、あるユーザーが未評価のアイテムに対して、その評価パターンが類似するユーザーの評価をもとに推薦をします。アイテムベースでは、アイテム同士の類似性に注目し、あるアイテムに高評価をしたユーザーに対して、類似した他のアイテムを推薦します。利点は、アイテム内容や属性などを事前に分析する必要がないこと、多様なユーザーの好みを捉えることができることです。新規ユーザーやアイテムへの推薦が難しい(コールドスタート問題)が欠点です。これら2つのフィルタリングを合わせたハイブリッドなアプローチを取ることもあります。
非構造化データ処理
自然言語処理
不要なテキストデータの特徴を抑える際に必要なクリーニング処理の代表例として、小文字化、数値置換、半角変換、記号除去、ステミングがあります。AIなどは文字や単語の意味でなく、文字コードというコンピュータ固有の識別コード体系により違いを見ます。そのため1と1は別物と処理します。また、数字の代償や記号の有無、時制が意味を持たない場合があります。その際は数字を全て0に置き換える数値置換や、!などを除去する記号除去を行なった上で、時制などによる単語の一部の変化をなくし表記を統一するステミングを行うと不要な特徴がなくなり、分析目的に沿った文章の意味である構築と勉強の違いを浮き彫りにできます。
文章を形態素という意味のある最小の塊に分割し、それぞれの形態素に関して品詞を把握する作業を形態素解析と言います。日本語では英語より形態素解析に時間がかかるので、公開されている形態素解析器を用います。MeCab、Janome、JUMANなどがあります。文章中の形態素や文節の関係性などを分析することを係り受け解析と言います。KNP、CaboChaなどのツールがあります。ツールにより出力結果が異なる場合があります。
自然言語処理を用いて、固有表現抽出、要約・知識獲得・情報抽出、機械翻訳、検索・文書分類、評判・感情分析、推薦、質問応答などができます。近年ではGLUEという指標を用いることがあります。これは上でのタスクをはじめとした9つのタスクにおけるスコアを算出するベンチマークとして利用されます。
画像認識
標本化(サンプリング)と量子化のプロセスで行われます。標本化は画像を縦横それぞれ等間隔の格子状の点に分割する作業で、この格子をピクセル(画素)と言います。格子の幅(サンプリング間隔)が大きいとピクセル数が少なくなるので、ジャギーという階段状のギザギザが現れて全体がぼんやりしたり、エイリアシングという本来存在しない縞模様(モアレ)が表示されます。量子化は標本化によってできた画素の濃度を離散値化(レベル化)する作業です。2レベル(1ビット)あれば濃淡が2段階で表現され、レベルが増えるとより正確に表示されます。標本化と同様に量子化もレベルが少ないとレベルの境界(エッジ)が際立って表示されるので、ある程度の量子化レベルが必要です。一般的には256レベル存在する8ビットがよく用いられます。これに加えて画像の色と画像データのフォーマットにより画像のデータサイズが決まります。色はグレースケールや色の三原色(RGB)を組み合わせたカラーなどがあります。フォーマットはJPEG、PNG、BMP、TIFFなどがあり、フォーマットにより圧縮率や圧縮方法が異なります。
画像補正処理、画像加工処理(代表例はフィルタ処理)、画像変換処理(傷などを目立たせる)などもあります。
画像データの前処理にはフィルタ処理の他にも、複数の画像をまとめたデータセットとして画像を扱う際のクリーニング処理もあります。リサイズ、トリミング、パディング(不足する部分を適当な色のピクセルで埋め合わせる)があります。さらに画像識別AIモデルの精度向上などに向けて、各ピクセルの濃淡度やRGB値を扱いやすいように標準化や正規化を行います。ここでは最大値や最小値が決まっているため、最大値や最小値を統一する正規化を選択すべきです。
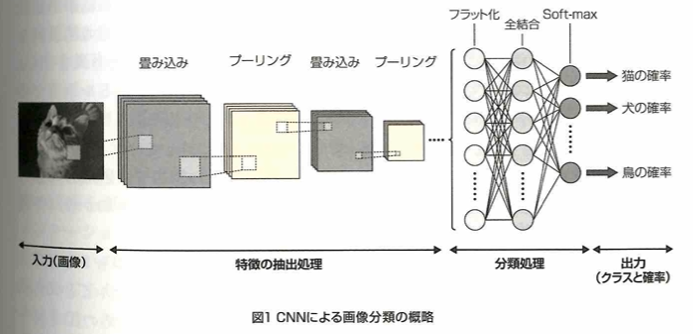
画像分類は入力された画像について被写体のクラスを分類するタスクです。最も高い確率のクラスを採用します。次の図は畳み込みニューラルネットワーク(CNN)による画像分類の概略です。
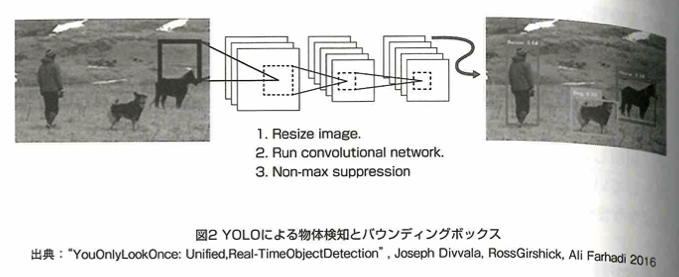
物体検出は画像の中でどの物体がどの位置に写っているかを認識するタスクです。バウンディングボックスという区画情報で表現され、その中に写っている物体が何であるかを識別します。
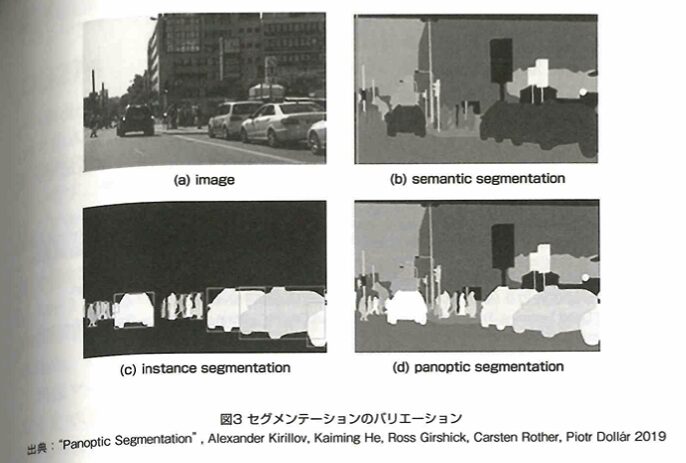
セグメンテーションとは、画像のピクセル1つ1つに対してクラスへの割り当てを行います。セマンティックセグメンテーション、インスタンスセグメンテーション(数えられるものを識別)、パノプティックセグメンテーション(前2つの両方の出力)などがあります。
応用的なタスクもあり、人の姿勢推定、顔認識、自動運転などもあります。
映像認識
動画データは映像データと音声データから成ります。映像はフレームが構成しています。1秒間に何枚のフレームを表示するかがフレームレートでfpsで表します。映像データと音声データはともに圧縮し2つのデータを1つにまとめてMP4、AVI、MOVなどで保存します。圧縮作業をエンコードと言いいます。再生の際にデータ復元する作業をデコードと言います。両方できるソフトなどをコーデックと言います。PythonではOpenCVというライブラリを使い、大量の動画および画像データをまとめて処理できます。
音声認識
マイクが1秒間に波の情報を数字に変換する回数をサンプリングレート(サンプリング周波数)といい、44.1kHzや48kHzが一般的です。値が大きいほど音波の情報をたくさん取得しているので高音質になりますがデータが大きくなります。あるサンプリングレートで取得した音を1つ1つ数字に変える際に、置き換える数字が取ることのできる幅を量子化ビット数と言います。CDの量子化ビット数は16ビットですが、これは音波を2の16乗の幅で数値化することを意味します。保存法はWAV形式で、マイクで取得した情報をそのまま保存するので高音質ですがデータ量が大きいです。MP3形式は人間の可聴領域に着目して開発されました。これは人間が聞き取れない音の領域を排除することで、データ量を小さくすることで開発されました。ただし、機械の故障予知などのために稼働音を分析する際は、MP3形式は避けた方が良いです。
生成
大規模言語モデル
ハルシネーションについて、データに起因する問題、訓練過程に起因する問題、推論過程に起因する問題などがあります。データに起因するものに対して、データのバイアス、知識の限界、データに含まれる知識の不十分な活用、訓練データに含まれる誤情報などがあります。
以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『データサイエンス力の数理統計』の復習です。
系統抽出法は、通し番号をつけた名簿を作成し、1番目の調査対象を無作為に選び、2番目以降の調査対象を一定の間隔で抽出する方法です。多段抽出法は、母集団をいくつかのグループに分け、そこから無作為抽出でいくつかのグループを選ぶ、という操作を繰り返して、最終的に選ばれたグループの中から調査対象を無作為に抽出する方法です。集落抽出法は、母集団を小集団であるクラスタに分け、分けられたクラスタの中からいくつかのクラスタを無作為に抽出し、それぞれのクラスタ内の全ての個体を調査する方法です。層別抽出法は、母集団をあらかじめいくつかの層(グループ)に分けておき、各層の中から必要な数の調査対象を無作為に抽出する方法です。
正規分布の曲線をベルカーブとも言います。IQR(interquartile range)を四分位範囲といい、Q3+1.5IQRとQ1-1.5IQRを上限と下限としてそこの範囲外となったデータを外れ値と皆します。
オッズをp/(1-p)として対数オッズを考えます。これを関数として考えたものをロジット関数と言います。ロジット関数の逆関数を(標準)シグモイド関数といいます。この関数は点(0,1/2)に対して点対象で、値域は0<y<1です。
集合演算はブーリアン演算、ブール演算にておいて用いられます。SQLのようなデータベース言語において論理演算を実行できます。
以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『データサイエンス力の機械学習』の復習です。
単回帰分析では切片bも回帰係数に含まれます。0から1の範囲に収まるように変換する方法を0-1正規化といいます。(x-xの最小値)/(xの最大値-xの最小値)で求めます。外れ値の影響を受けやすいです。画像データは各ピクセルの値が0~255と扱われるので0-1正規化が用いれらます。0-1正規化は外れ値に対する対処法ではありません。標準化を行ってから閾値を超えたデータを外れ値とみなして除去する方法があります。データの両端を5~10%カットして外れ値の侵入を防ぐ方法もあります。ただしこの方法では正常なデータも除去してしまう恐れがあります。外れ値には異常値と欠損値があります。MAEは外れ値の影響を受けにくく、MSEは受けやすいです。標本誤差とは、標本値と母集団値との差のことです。
回帰とは入力データに対して連続値を出力することで、分類とは入力データに対してカテゴリを出力することです。ランダムフォレストは回帰問題と分類問題の両方に対応できます。
ワンホットエンコーディングは、対象となる変数を、その変数が取りうる値(カテゴリ)ごとに別々の変数に分解します。カテゴリーをダミー変数に変換する場合、単純に0,1,2などとすると、数値の大小が学習に影響を及ぼす場合があります。そのためワンホットエンコーディングがよく用いられます。つまり行列表示にして0と1を割り当てていきます。
原系列において、前後時刻の差分を計算すると、差分系列が得られます。差分系列では長期的な傾向が取り除かれ、局所的な変化が強調されます。移動平均法では長期傾向が得られます。
データドリフトとは入力データのうち、モデルのパフォーマンス低下につながるような変更をいいます。データの脱落とは含まれていないデータの存在を無視することです。グラフの視認性や解釈性に関する指標としてデータインク比があります。データを印刷するために費やしたインク量÷グラフィック全体の印刷に費やしたインク量です。1に近いほど簡潔でよい表現です。比較して可視化したい分類によってデータを分けることを層化といいます。
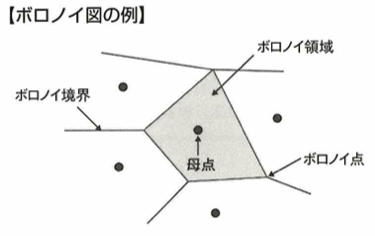
棒グラフとヒストグラムは役割が異なります。積み上げ棒グラフでは内訳の微妙な変化を読み取ることはできません。ボロノイ図は平面上に複数個の点がある場合に、任意の点と一番近い点を把握するための表現です。距離の近い点同士を線で結び、その垂直二等分線をつなぐことによって作ります。このようにしてできた分割をボロノイ分割といいます。また、配置された点を母点といい、その周りの領域をボロノイ領域といい、その交点をボロノイ点といいます。ボロノイ図は電波の届きにくい領域を考えることに応用されます。隣接するボロノイ領域の母点同士を結んだ図形をドロネー図といいます。温度の違いを色で表現するサーモグラフィーもヒートマップの一種です。平行座標プロットでは4次元以上のデータを可視化できます。主に名義尺度と複数の数値がセットになったデータで用います。
カテゴライズとは量的変数をカテゴリ変数に変換することです。ビン化とはデータを等間隔の区間で分割することです。区間のことをビンといい、区間の大きさをビン幅といいます。各ビンに含まれるデータの個数を度数といいます。ヒストグラムとは、ビン化したデータの度数を可視化したものです。アンサンブル平均とは同一条件において得られた測定値を平均した値で、異なる条件下で得られた測定値を平均した値を時間平均といいます。
CNN(畳み込みニューラルネットワーク)は画像分類や物体検出に用います。
次元の呪いとは、機械学習において入力の次元数(説明変数の数)が増えると、学習の難しさが指数関数的に増大する現象です。これにより予測精度が低下する場合があります。データの次元数削減には主成分分析などがあります。
モデルの大域的説明とは、機械学習を用いて構築した複雑なモデルを人間にとって解釈可能で可読性の高いモデルを用いて再現することです。局所的な説明は、近似を行うことによって生じる精度の低下を回避する方法の1つで、機械学習モデルへの特定の入力に対する予測結果や予測プロセスを元に、モデル自体の解釈を試みる方法です。
自然言語とは人間が日常的にコミュニケーションに用いている言語です。日本語の形態素解析に用いられるツールは、MeCab、JUMAN、ChaSenなどです。MeCabの解析結果を入力とする係り受け解析(形態素解析の解析結果をもとに各形態素間の係り受け関係を解析すること)ツールがCaboChaです。他にはKNP、GiNZAなどがあります。

データクレンジングで欠損、外れ値、無関係な値などを除去、修正して表記ゆれのある単語を同一単語と扱うことができます。頻出頻度の低い単語や、タスクに関係のない単語をストップワードといいます。「、」「。」「a」「an」などの記号や冠詞などです。単語の語感を抽出する処理をステミングといいます。ストップワードの除去やステミングもデータクレンジングの一種です。
GLUEは自然言語処理における精度を計測するベンチマークです。固有表現抽出はGLUEに含まれません。固有表現抽出(NER:Named Entity Recognition)は文書中の固有表現を区別して取り出すタスクです。固有名詞や数値表現になります。資源言語処理(NLI)、含意関係認識(RTE)は2つの文の間の含意関係や矛盾の有無を判定するタスクです。照応解析とは、照応詞(代名詞や指示詞など)が文中の何を示しているか(照応関係)を判定するタスクです。SST-2のような評判分析、感情分析というタスクも文書タスクの1つです。
画像データは複数の画素(ピクセル)の集合です。画素について、(R,G,B)=(0,0,0)は黒で表します。白は(255,255,255)です。

JPG、PNGはフルカラー(1677万色)で画像を表現します。PNGで保存された画像は保存を繰り返しても劣化しません。JPG形式は目視で把握できない情報を削除することでデータを圧縮します。そのためJPG形式で保存した画像は保存を繰り返すたびに劣化します。GIFは256色で画像を表現するフォーマットです。フィルタ処理は、ノイズ除去や輪郭抽出など画像に対して特殊な加工を行うことです。
音声データについて、FLAC(Free Lossless Audio Codec)はコーデック(圧縮技術)で圧縮されたものです。可逆圧縮のフォーマットで、MP3は圧縮前のデータに復元できない非可逆圧縮です。動画についてAVIはwindows、MOVはMacにおける標準的な動画フォーマットです。WebMはGoogleによって開発された軽量フォーマットです。MP4も軽量フォーマットです。
バスケット分析は、買い物籠の中身の傾向を解析する手法です。バスケット分析において商品Aと商品Bの売れ行きの関係性を追います。支持度とはP(A∩B)です。期待信頼度はP(B)です。Aから見たBの信頼度はP(B|A)です。これをP(B)で割ったものをAから見たBのリフト値といいます。Aから見たBのリフト値が大きいほど、Aを買った人はついでにBも買う傾向があるといえます。もしこうだったら、こうなるだろうというようにデータの関係性を見つけ出すことをアソシエーション分析といいます。
単体での精度が比較的低いモデルを弱識別器といいます。アンサンブル学習の代表手法として、バギング、ブ―スティングがあります。バギング(代用例はランダムフォレスト)は各モデルを並列的に学習する手法です。ブ―スティング(代表例はAdaBoost)は各モデルを直列的(逐次的)に学習する手法です。kaggleで高い成績を出しているモデルで、勾配ブースティング決定木(GBDT:Gradient Boosting Decision Tree)があります。派生手法として、XGBoost、LightGBM、CatBoostなどがあります。
次はデータサイエンティスト検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』の該当する章『データサイエンス力(基礎)』の復習です。
XORは排他的論理和です。標本分散はnが小さいと母分散から離れていくので不偏分散を考えます。統計で標本を扱う際は不偏分散が使われます。摂氏は間隔尺度ですので30℃は15℃より2倍暑いとは言えません。ピアソンの相関係数は質的データで計算不可能。スピアマンの相関係数は正規分布に従っていないデータに適用できます。2を底とする対数は二進対数でコンピュータの内部処理と相性が良いです。両対数グラフは元のグラフに似ている概形になります。
連続した数値データを不連続なデータ群に部活することを離散化と言います。平均には時間平均とアンサンブル平均(同じ条件)があります。選択バイアス(脱落バイアス(途中で調査から外される)、欠測バイアス(ミスでデータ不足)、自己選択バイアス(対象に意思がある))、情報バイアス(データ加工でのミス)、交絡バイアスがあります。
データ濃度は画面上の単位面積あたりのデータ量です。アニメーションは細部のデータを見落としやすいですが全体像把握に適しています。
次はデータサイエンティスト検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』の該当する章『データサイエンス力(実践)』の復習です。
インフォデミックは情報+感染症の造語で、デマなどで混乱を招く様子です。
データ分析は情報収集→集計→データ可視化→意味合いの抽出です。
アソシエーション分析(条件→事象)はデータマイニングの一種で信頼度(条件付き確率)、支持率(共起頻度が起きる確率)、リフト値(商品が別の商品の購入率をどの程度引き上げているかの指標です。リフト値が高いとセットで人気が高いとなり、低いと別の商品の人気が高いだけになります。つまりリフト値の分子は信頼度で、分母は別の商品が購入される確率です)の3指標があります。共起頻度は積事象部です。
機械学習モデルは、機械学習で得られた数式です。特異値分解は次元削減です。物体検出はバウンディングボックス、領域分類ではセグメンテーションです。アクティブラーニングは能動学習で、一部に正解データを用意し残りの教師なしデータからモデルの学習に効果的なデータを人が選別しアノテーションをし教師データを増やします。
単回帰分析では数多くの項目を2つの分析軸に集約し関係性を分析できます。標準偏回帰係数は目的変数と説明変数を標準化して重回帰分析で得られた係数です。
ソフトマージンを採用するモデルをC-SVMと言います。Cは誤分類をどこまで許容するかのハイパーパラメータで0以上の実数で小さいほど誤分類が許容されやすいです。ガウシアンカーネルはカーネルトリックで使用します。ブースティングでは誤認識したデータを逐次的に学習していきます。マハラノビス距離は相関で決まります。
ウォード法はクラスター内のデータの平方和が小さいクラス同士をまとめます。鎖効果が減り分類感度が高いです。群平均法はクラスター同士で全ての組みの距離を求め平均をクラスター間の距離とします。鎖効果が防止できます。最短距離法は外れ値に弱いです。メディアン法は等しい大きさのクラスターにおける重心法です。エルボー法は適切なクラスター数の推定法です。
ドリフトは時間経過とともにモデルの予測性能が落ちることです。コンセプトドリフト(関係性の差異)とデータドリフト(データの差異)があります。交互作用特徴量は二変数を組み合わせた特徴量の作成で精度向上が期待できます。AutoMLは次のプロセスの真ん中2つを行います。課題と仮説定義→データ収集→モデル作成→モデル運用です。
MAPEは予測値と実測値の差の確率をパーセントにした平均で、ビジネスで役立ちます。多値分類の評価はmacro平均(クラスごとの評価値を出して平均)、重みづけ平均、micro平均(まとめられた混同行列で評価値を算出)があります。

z検定は2標本の平均値に差があるかの検定です。
1000件のデータで900件の学習データと100件の検証データがあるとき機械学習は10回実行されます。つまり10エポックです。
ノイズとは解析対象とならないものです。ARIMAXはARIMAに外生変数(外部要因の変数)を入れたモデルで祝日などを考慮できます。状態空間モデルは目に見えない変動からも予測可能な汎用性の高いモデルです。
クリーニング処理の数値置換は数値を全て0にすることです。ステミングは時制などの統一です。
標本化で荒く区切ると画素数が減りジャギーが被写体の輪郭に現れ、エイリアシング(存在しない縞模様)が生じます。細かくしすぎるとサイズが大きくなります。量子化(標本をデジタル化)は量子化レベルが上がると濃淡を正確に表現できてくるので256レベル(8ビット)が一般的です。PythonではOpenCVで画像処理可能です。動画1秒のフレーム枚数をフレームレートといいfps単位で表現します。映像と音声データをエンコード(圧縮)しコンテナという動画フォーマットにし保存します。再生は復元(デコード)します。この装置をコーデックと言います。
WERは形態素単位で考え、CERは1文字ずつ考える誤り率です。サンプリングレート(1秒間にサンプリングする回数)が高いと高音質です。次に量子化をします。信号を何段階にするかの数値を量子化ビット数と言います。
単調関係は線形でない増加または減少関係です。GPT-3は2020年にOpenAIが発表しました。トレンドは長期の傾向です。
データエンジニアリング力
環境構築
システム企画
オープンデータとは、国、地方公共団体および事業者が保有する官民データのうち、誰もがインターネットなどを通じて容易に加工できるように公開されたデータです。つまりネット上にあるデータはオープンデータでないことに注意しましょう。
2次利用可能ルールが適用され、機械判読に適し、無償で利用できるものです。
ユーザーにサービスを提供するシステムでは、通常、複数台のサーバーを用いて1台のサーバーのように動作するクラスタ構成がとられます。これをクラスタリング(クラスタ化)と言います。これは拡張性(スケーラビリティ)と高可用性(アベイラビリティ)のために用いられます。高可用性を高める構成を冗長構成と言います。ホットスタンバイ、コールドスタンバイ、ウォームスタンバイがあります。ウォームスタンバイは最小限のOSのみを起動しておくような、2者の中間的な構成です。
アーキテクチャ設計
ノーコードツールとはソースコードを書くこともなくソフトウェアを開発できるツールですが、ソフトウェアで使用できるUIなどのパーツはそのツールが提供しているものに限定してしまいますので、小さいソフトウェアの開発に向いています。ローコードツールは、一部のソースコードを書くことでソフトウェアを開発するツールです。UIなどのパーツはそのツールが提供しているものに依存しますが、拡張性がある場合が多く、ノーコードツールよりは柔軟に対応できます。一定レベルのソフトウェアまではローコードツールで対応できます。
仮想化とは、コンピュータのハードウェアを抽象化して1台のサーバで複数のサーバが稼働しているかのように見せる技術です。コンテナ型仮想化は、ホストOS上のカーネル(OSの中核機能)を共有し、プロセスを隔離して管理することにより、ソフトウェアがあたかも別マシン上で動作しているように稼働できます。Dockerはコンテナ方式の仮想化技術の中で最も多く利用されているオープンソースの仮想化ソフトです。
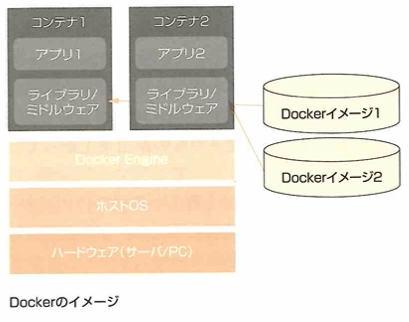
コンテナは当初は一時的なテストで用いましたが現在は展開の容易性を利用して短時間で分散環境を構築する技術としても注目されています。
マネージドサービスはクラウドが提供するサービス形態です。ソフトウェア機能の提供から運用管理までを一体として提供します。Jupiter Notebook、RStudioなどのGUI画面を共有する対話型の分析環境、利用頻度の高い機械学習や統計分析ライブラリを標準装備したプログラム実行環境、クラウドベンダーが独自に提供する直感的なGUI画面を共有する分析環境、分析のチューニングや特徴量生成を自動化するAutoMLサービスなどが各クラウドベンダーから提供されています。短期的なPoCや動作検証、学習を行うことに適しています。
データ収集
クライアント技術
SDKとはSoftware Development Kitです。対象プラットフォームを使用するための説明書、プログラム、API、サンプルコードなどが含まれています。JDK(Java Development Kit)は有名なSDKの1つです。APIはApplication Programming Interfaceです。対象のプラットフォームが持つ機能を、別のプログラムから呼び出して利用できます。APIはC言語の関数、Javaのclass、REST APIなどがあります。APIは形態により使用手順が異なります。C言語の関数で提供されるAPIはライブラリという形で提供され、コンピュータ上で実行可能な形式に変換(コンパイル)して使います。APIを利用するメリットは、外部ソフトウェアとの連携が容易になることです。Windows上で動作するアプリを作成する際に、Win32 API/Win64 APIを用いて簡便にWWindowsが持つ各種機能を使用できます。
Webクローラー・スクレイピングツールはネット上に公開されているWebページの情報を収集するプログラムツールです。Webコンテンツには静的コンテンツと動的コンテンツがあります。前者はいつでもどこでアクセスしても同じWebページが表示されるコンテンツです。後者はアクセスした際の状況に応じて異なるWebページが表示されるコンテンツです。Web検索では、ユーザーにクエリ文字列を入力させ、Webページ要求時にそのクエリ文字列を送信することで、検索結果を表示するWebページを生成し表示します。現在は有償・無償のWebクローラー・スクレイピングツールが多く出回っております。しかしクローラーはやり方を間違えるとWebサーバーに大きな負担を与えかねず、場合によってはサーバーを攻撃する行為になりかねません。
通信技術
通信プロトコルとは通信を行うための規格です。HTTPはWebブラウザがWebサーバーと通信する際に使用されます。HTTPSはHTTP SecureでHTTPの通信がSSLやTLSで暗号化されます。FTPはFile Transfer Protocolです。Telnetは端末から遠隔地にあるサーバーなどを操作する際に使用されます。SSHはSecure Shellで通信内容を暗号化して安全にコンピュータに接続して操作するための通信プロトコルです。HTTPの場合はGET、POST、PUT、DELETEなどのメソッドという操作手続きを持っています。
データ抽出
データ抽出のフォーマットはCSV(Conmma-Separeted Values)、TSV(Tab-Separated Values)などがあります。データベースからデータを抽出し、エクセルを用いて分析する流れでいくつかの注意点があります。意図しない形で読み込まれる、読み込み可能な行数に制限がある、元のデータベースと連動しないなどです。
データ構造
基礎知識
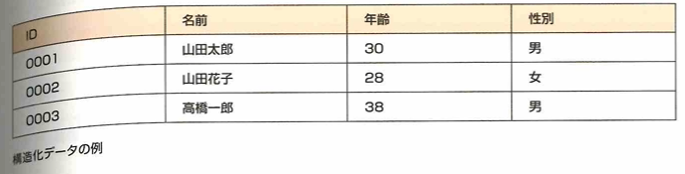
構造化データは一定のルールやフォーマットに従い統一された仕様で記録されたデータです。行と列という概念はJSON、XML、CSV、TSVというデータフォーマットで表現されることもあります。非構造化データは特定のフォーマットに従わず形式やルールが統一されていないデータです。例えば音声、画像、動画などです。この際は前処理でタグ付けや抽出処理を行い、構造化データに変換して利用します。
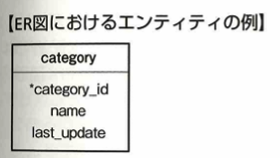
ER図とは実態関連モデル、実態関連図などと言います。関係データベースの構造を可視化するために用います。
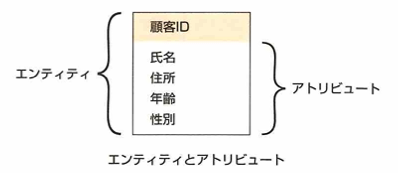
データのまとまりをエンティティ、その属性をアトリビュートと言います。エンティティ間のつながりをリレーションシップといい、線で繋いで表します。IE記法のカーディナリティ記法は次です。
例えば次のように表します。
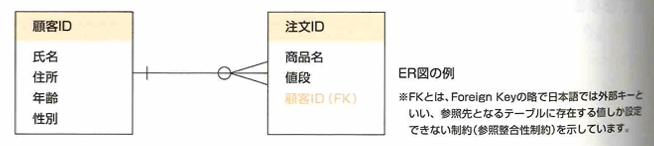
テーブル定義
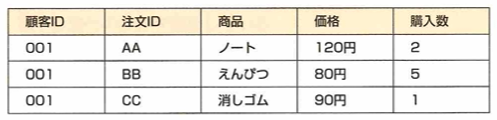
データベースの正規化は、第一正規化、第二正規化、第三正規化があります。候補キーはテーブル上で任意のレコードを特定するためのカラム(列のこと)の集合です。MySQLなどのRDBでは主キーと言います。非キー属性は候補キー以外のカラムです。関数従属性は、特定のカラムAの値が決まった際に、別のカラムBの値も決まる関係性のことです。
部分関数従属性は、候補キーが複数カラムで構成されている際に、非キー属性のカラムが、候補キーの一部に関数従属している関係性です。例えば価格は商品に部分関数従属しています。
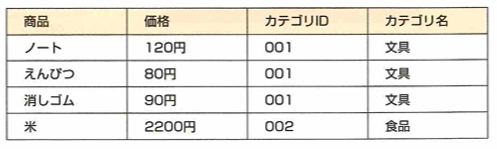
推移従属関係とは、非キー属性のカラムAが、非キー属性のカラムBに関数従属している関係です。例えばカテゴリ名はカテゴリIDに推移従属しています。
第一正規化は、繰り返される項目がなく、レコード単位の情報になっています。非正規化から第一正規化を行ったイメージは次です。
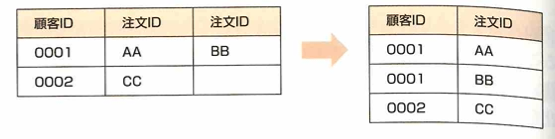
第二正規化は、第一正規化の条件を満たし、部分関数従属がないことです。以下の図では注文IDに部分関数従属されている部分と、商品IDに部分関数従属されている部分があります。候補キーが注文IDと商品IDであることに注意します。
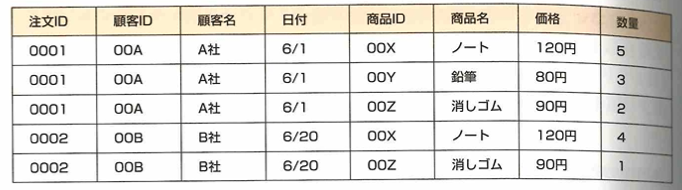
これを次のようにします。
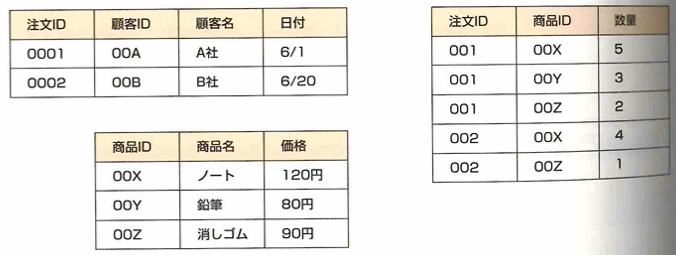
第三正規化は第二正規化の条件を満たし、推移関数従属がないことです。
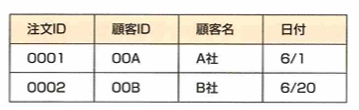
例えば顧客名は顧客IDに推移関数従属していますので、これを以下で第三正規化します。

データ蓄積
DWH
DWH(データウェアハウス)として利用されるアーキテクチャについては、一般のRDBMS(リレーショナルデータベース管理システム)を使う場合の他に、データ分析で必要な加工集積処理に対して、大量のデータを高速に処理できるように設計されたDWHアプライアンスやDWH用のクラウドサービスがあります。企業でデータ分析を行う場合、機能面で優れ、サポート面も受けられる、エンタープライズ用途で有償のDWHが採用されます。分析用途で採用される代表的なDWHアプライアンスには、Oracle ExadataやIBM Integrated Analytics Systemなどがあります。DWHアプライアンスは製品ごとにそれぞれ高速化するための独自の工夫がされています。サーバーを構成するパーツや基盤設計、並列分散処理のためのノード間の連携方式、データの保持形式など、一般的なRDBMSとは異なったアーキテクチャです。代表例としてカラム指向型DBについて考えます。一般的なRDBMSは行指向型DBで、データを行単位で保持しており、トランザクションが発生するたび、行単位で対象レコードを特定し、データの追加、変更、削除などが行われます。カラム思考型DB(列指向型DB)は列単位でデータを蓄積し、列方向に大量にあるデータに対して、特定の列だけを集計・抽出するようなデータ分析や、統計処理などを効率的に行うことができます。しかし1行単位のレコードに対するトランザクション処理などには不向きです。このようにDWHアプライアンスは大量のデータの結合・集計・抽出などにおける処理能力に特化した独特なアーキテクチャを採用しているので、一般的なRDBMSに比べて苦手としている分野もあります。
分散技術
HadoopやSparkの分散技術とは、ネットワークで接続した複数のコンピュータで、分散して処理を行う技術です。一般のRDBMSと比べて、対象データが大規模で更新が少なく、構造が変化しやすい場合に向いています。処理の性能を上げたい場合は、ノード数を増やす方法で対応できます。Hadoopは実際には複数サービスを組み合わせたもので、多様な環境構成になっています。Sparkも同様で、Hadoop関連プロジェクトに含まれ、環境構成のパターンがより複雑になります。Hadoopベースの技術としてHDFS(Hadoop Distributed File System)と、分散技術における汎用性なクラスタ管理システムであるYARNがあります。HDFSは、複数ノードのストレージに分散してデータを保存することで、1ノードのストレージ容量を超えるデータを蓄積・利用できる仕組みです。巨大なファイルを高スループットで提供できる点がメリットですが、小さなファイルを大量に扱う場合や、低レイテンシ(データ転送などにかかる応答が早く遅延が少ない)が求められる場合は向いていません。Hadoopのデータ処理の仕組みであるMapReduceアプリケーションはノードのストレージが通常メモリに比べて大きく、巨大なデータ処理ができるのがメリットですが、デメリットは、ノードのストレージに対する読み書きが何度も発生し、ストレージはメモリに比べて読み書きが遅いので、反復的な処理などに弱い点があります。Sparkでは、RDD(Resilient Distributed Dataset)などの仕組みを用いたメモリ上の分散処理によって、メリットとデメリットがMapReduceと逆になります。実際の操作はRDDより、DataFrameやDataSetといったインターフェイスを使ってプログラミングします。
NoSQLデータストアとは一般的なRDBMSと異なるデータベース管理システムの総称です。代表的なNoSQLデータストアには、HBase、Cassandra、Mongo DB、CouchDB、Amazon DynamoDB、Cloudant、Azure Cosmos DBなどがあります。SQL以外の方法で操作する必要があり、テーブル構造に固定化されず、ハードウェアの拡張性が高く、より大規模なデータを取り扱え、低レイテンシである処理に強い特徴があります。近年では各クラウドベンダーがマネージド型のNoSQLを提供し、これらにより環境構築を行わず容易にNoSQLを活用できるようになりました。多くのNoSQLマネージドサービスが重量型の課金体系で、大量データを蓄積した場合のコストもリレーショナルデータベース(RDBMS)タイプのマネージドサービスより安くなります。さらにNoSQLはAPIなどで操作し、拡張性に優れ、大量データでも安定した性能でデータアクセスできるメリットがあります。NoSQLはRDBMSのSQLで提供されるデータ操作機能を全て実現できません。データ活用の要件に応じてRDBMSとNoSQLを使い分けることが大事です。
クラウド
さまざまな形式のデータを蓄積できるストレージにいったんデータを蓄積しておくことが一般的です。クラウド上の代表的なストレージサービスに、Amazon S3、Google Cloud Strage、IBM Cloud Object Storageなどがあります。アクセス権限の設定に漏れがあると予期せぬ外部からのアクセスを許してしまうリスクが生じます。
データ加工
フィルタリング処理
絞り込みなどでフィルタリング処理を行います。SQLではWHERE句を用いて絞り込みます。IN・LIKE・BETWEEN・AND・ORなどを用いて抽出する方法もあります。

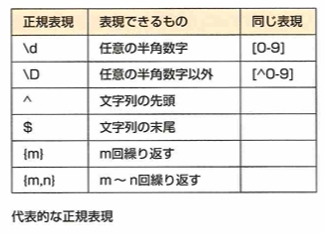
正規表現とは文字列のパターンを記述する構文です。文字列中に特定のパターンが含まれているか判断したり。特定の部分を抽出できます。代表的な正規表現は下記になります。
ソート処理
SQLの処理としてORDER BYによるソート処理があります。ASC、DESCはそれぞれ昇順、降順という意味です。

結合処理
内部結合、外部結合、自己結合、UNION処理などがあります。

エクセルにおいてVLOOKUP関数があります。SQLではINNER JOIN(内部結合)、LEFT OUTER JOIN(左外部結合)を使います。
前処理
クレンジング処理について考えます。クレンジングの対象となるデータを抽出する必要があり、フィルタリングの能力が大事になります。抽出したデータに対して置換処理や除外処理を行います。クレンジングルールを決めて数式や関数などを用いてクレンジングします。
マッピング処理
マッピング処理とはある値を別の値と対応づける処理を指します。マッピング処理はマスター(対応表)のもとで行います。取得したマスターが最新であるかに注意します。マスターや属性情報などのソースデータの変更履歴を保存し、データ上で表現することを、スロー・チェンジ・ディメンションと言います。
サンプリング処理
有名な方法を把握することが大事です。

集計処理
データの基本的な特徴を表す値に基本統計量があります。

Pythonの場合はPandasというライブラリのdescribe関数を用いて、最大値などの一覧表を作成できます。
変換・演算処理
データを操作する際はデータ型に気をつけます。数値型、文字型、日付型などがあります。SQL、Python、エクセルでの四則演算について例が書かれています。
文字コードは文字をコンピュータで処理するため、文字の種類を割り振った(符号化した)ものがあり、EUC-JP、JIS(ISO-2022JP)、Shift_JIS、UTF-8、UTF-16が例としてあります。データ作成したシステムツールと、それを集約して分析を行うシステムやツールが異なる場合に用います。たとえばWindowsにデフォルトで入っているメモ帳を使う場合、変換元のテキストファイルを開くと右下の表示で文字コードを確認できます。そのファイルを別名で保存する場合、エンコードを切り替えて保存することで、文字コードを容易に変更できます。

データ出力
データ加工や分析をした結果を特定のフォーマットデータとしてエクスポートできます。代表的なフォーマットはこちらです。

データをデータベースに挿入するには複数の方法があります。対象がリレーショナルデータベースのときはSQLのINSERT文を用いてレコードを挿入します。CSV形式などのデータファイルを一括して挿入する場合は、対称のデータベース製品が提供するLOADコマンドやIMPORTコマンドが良く利用されます。リレーショナルデータベースのテーブルにはデータの型や桁数などが定義されており、投入対称のデータがテーブルの定義に従っている必要があります。またデータ項目がデータ型に従っていても、NOT NULL制約、一意性制約、外部参照制約などのデータベースの制約に違反すると挿入時にエラーとなるので、制約の理解が必要です。

データ展開
分析をするためのデータには社内のシステムに蓄積されたデータを利用するケースもあれば、公開されているWeb上のデータを習得して、利用することもあります。WebAPIは、HTTPなどのインターネット関連技術を利用してデータを送受信するための規格で、代表的なものにREST、SOAPがあります。このようなオープンな規格を用いて、異なるシステムからも同一の手順や仕様でデータを取得できます。

データ連携
ファイル共有サーバーは社内など自らの管理スペース内にサーバーを設置するオンプレミス型で設置されることもありますが、最近はクラウド上のファイル共有サービス利用が広まっています。デメリットは災害時の復旧などです。ファイル共有にはFTPサーバーを使うこともあります。FTPサーバーとのファイルの転送にはFTP(File Transfer Protocol)を用います。暗号化されていないので注意が必要です。分析担当者は共有されたデータファイルをエクセルなどに取り込んで分析します。
BIツールとは、ビジネスインテリジェンスツールの略で、社内にあるさまざまなデータを集約し、一目でわかるように見える化するためのツールです。

BIツールはエンタープライズBIとセルフBIに分けられます。前者は2000年ごろから登場したツールです。データの加工・集計・分析・出力が複雑で、IT部門など専門部署にて管理されます。後者はわかりやすいUI(ユーザーインターフェイス)上で、ユーザー自身がレポート作成やデータ分析を行えます。

データのグラフ化には次のような作業が必要です。

プログラミング
基礎プログラミング
データの抽出、データの加工、データの分析の流れにおいて用いるプログラム言語について以下のようなものがあります。

プログラムの中でデータを保持する領域のことを変数といい、そのデータがどういった種類のものかをコンピュータに解釈させるために付与される属性をデータ型といいます。多くのプログラミング言語は整数を扱う整数型、小数を扱う浮動小数点型、真偽の2値をあつかうブール型、文字列を扱う文字列型といったデータ型が備えられています。多くのプログラミング言語は、異なるデータ型同士では算術演算子による処理が行えないため、データ型の変換をする必要があります。この型変換を明示的に指定して行うことを明示的型変換、明示的に指定せずコンピュータの判断によって自動的に行わせることを暗黙の型変換といいます。Pythonでは変数作成時にデータの型宣言を必要としないので、意図しない暗黙の型変換が発生することがあります。
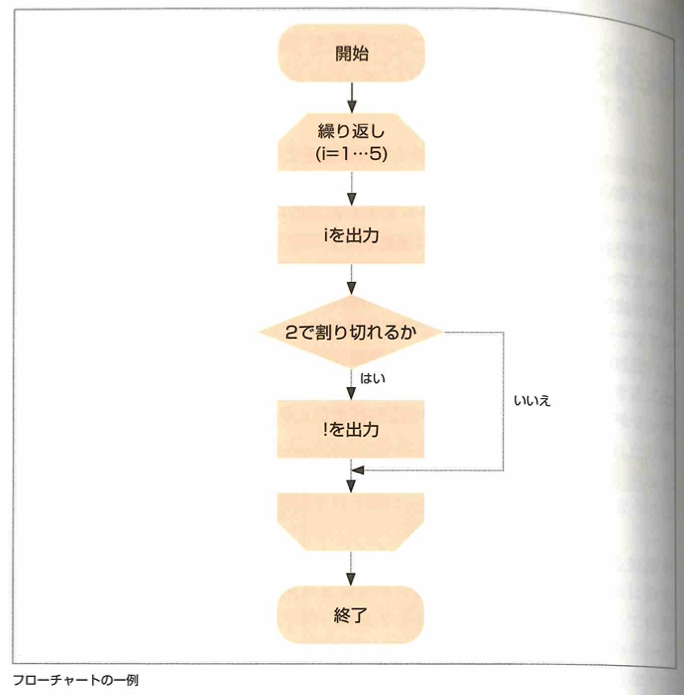
1~5までを出力しつつ、2の倍数のときは!も出力する処理は次のようなフローチャートで表せます。
データ(プロパティ)とそれらを操作する処理(メソッド)を1つにまとめたものを、オブジェクトやクラスといいます。それらを組み合わせてソフトウェア全体を構築しようとする考えをオブジェクト指向といいます。オブジェクト指向を取り入れるプログラミング言語をオブジェクト指向言語といい、Java、C++、Python、R言語などがあります。
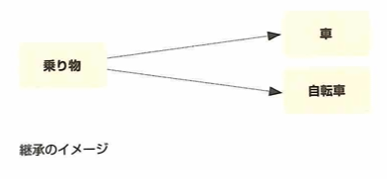
継承とはスーパークラス(親クラス)を継承して、親の特徴を引き継いだクラスをサブクラス(子クラス)といいます。
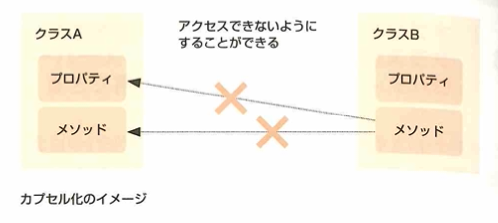
カプセル化とはクラスがもつデータや処理をクラス外から参照できないようにすることです。バグの派生を抑制できたり、ソースコードの可読性が向上します。Javaの場合priveteやpublicとつけると外部からアクセスできたり、できなかったりすることができます。外部のクラスからプロパティを操作する際は、アクセサという操作メソッドを用意し、メソッド経由で操作させるのが一般的です。getter/setterとよばれます。
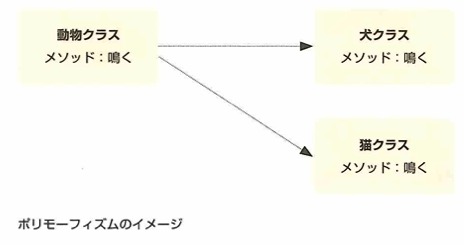
ポリモーフィズムとは継承した機能の一部を変更できることです。犬だとワン、猫だとニャンと出力できます。
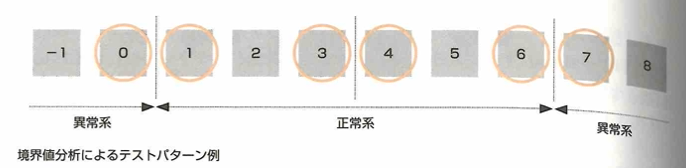
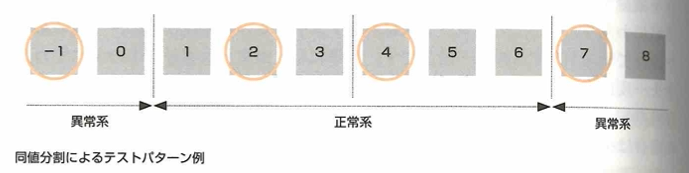
ホワイトボックスは、プログラムに注目して行い、ブラックボックスは入出力に注意して行います。ホワイトボックステストはコードカバレッジ(コード網羅率)で評価します。ブラックボックステストについて、制御フローテストとはプログラムのフローチャートの条件分岐に着目し、分岐条件を網羅するようにテストをする方法です。命令網羅とは対象プログラムの中のすべての命令を一度は実行する方法で、分岐網羅とは対象プログラムの中の分岐を全て行う方法で条件網羅とは、条件分岐についてそれぞれの条件が真または偽になる場合は少なくとも1回は含める方法です。データフローテストとは、プログラムの中で使用されるデータ(変数)に着目し、それがどこで定義され、どこで使用され、どこで消滅するかを検証するテストです。テストケース作成の際は、境界値分析や同値分類法などもあります。
拡張プログラミング
JSONはJavaScriptのオブジェクト記法でデータが定義され、同じファイル内でデータ定義もされます。XMLはデータとは異なるXML Schemaのファイルでデータ定義されます。これらは表形式のCSVと異なり配列や入れ子になる場合があるので、データ定義を確認し、階層を意識してデータ処理を行う必要があります。
組み込み関数は特別な手順なしで呼び出せる関数で、Pythonの場合はprint関数などが該当します。標準ライブラリはプログラミング言語が用意している機能群のことです。外部ライブラリの一例にPythonの機械学習ライブラリのscikit-learnがありあす。
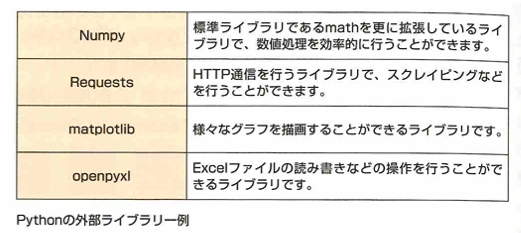
外部ライブラリはプログラムの作業効率をあげるのに欠かせませんが、Javaのログ出力で頻繁に利用された外部ライブラリのLog4jに脆弱性が見つかったケースのようにバグなどが見つかる可能性があります。
AIサービス利用
WebAPI(REST)の活用により、外部サービスを活用し短気期間での分析機能の実現可能になり、外部サービスが提供する最新のテクノロジーやアルゴリズムを利用可能で、分析機能や予測モデルを開発するコストを削減可能で、必要なサービスを組み合わせて柔軟で効率的な開発が可能になりました。このようにメリットがある一方で、次のようなデメリットがあります。APIの認証や通信の暗号化などセキュリティの確保、外部サービスに送信するプライバシーデータの扱い、外部サービスの仕様変更やサービスの停止が発生する可能性があり、外部サービスの課金体系確認やコスト見積りでの注意が必要です。
単語誤り率(WER)と文字誤り率(CER)が大事です。それぞれ次のように定義されます。これらに注意して内容に合わせた適切なAPIを選択するようにします。

迅速なバグ検出と修正、品質向上と一貫性の確保、リソースの最適な利用などが大事です。
アルゴリズム
効率の良いプログラムを書くために繰り返しの処理を見ることは大事です。実行時間計測はプログラムがCPUを使用しているユーザーCPU時間と、OSが使用しているシステムCPU時間に分けて計測されることが多いです。システムCPU時間が長い場合は、システムコール(OSの機能を呼び戻している箇所)を減らせないか検討します。
分析プログラム
Jupiter NotebookやRStudioは対話型の開発環境と呼ばれています。これらは直感的な操作が可能なGUI画面が準備されており、容易にプログラムの実行制御を行います。Jupiter NotebookはPythonやRubyでの開発でよく利用されます。RStudioはRを用いた開発でよく利用されます。
Noteook環境を使ってPythonやRのコードを開発して実行するスキルは大切です。クラウド上の総合環境の利用は次のような利点があります。柔軟なリソース管理、共同作業とリアルタイムコラボレーション、事前構築されたライブラリとツールです。一方でデメリットは、セキュリティ面や、課金体系などです。
SQL
受験報告を調べていると、データエンジニアリングでSQLの内容が思ったよりも多く出題されているようです。そのため本題に入る前に、頻出事項であるSELECT文についてまとめます。
SQLはデータ定義、データ操作、データ制御の機能を持っています。特にDS検定ではデータ操作についてが多く出題されます。
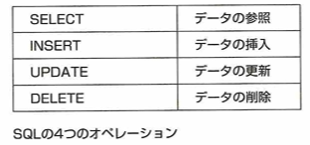
データ操作は、SELECT文、INSERT文(レコードを追加)、UPDATE文、DELETE文があります。そして特に大事な文はSELECT文です。
SELECT句は内容を出力させる命令記号です。
SELECT 呼び出すカラム FROM 表とします。四則演算は+,-,*,/です。WHERE句をつける場合はFROMの後です。WHERE句の後は、WHERE カラム=10などとします。カラム=bとしたいときは、カラム = 'b'とします。NOT,AND,ORの順で出力が優先されます。NOT句はカラム <> a とします。
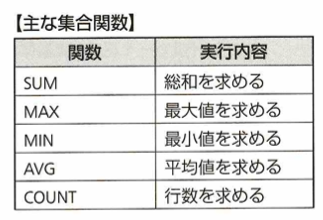
ORDER BY句は、WHERE句の後で書きます。ASC、DECSは昇順、降順です。集合関数は合計などを求めるものです。SUM、AVGは数値以外を引数にできません。BETWEEN演算子はWHERE句で用います。LIKE演算子もWHERE句で使用します。ワイルドカードは%(0文字以上の任意の文字列)と_(1文字以上の任意の文字)です。WHERE カラム LIKE 'ワイルカード' などとします。これらワイルドカードをただの文字としたい場合はESCAPEキーワードを使います。
GROUP BY句について考えます。これはグループにまとめて平均を出すときなどに用います。HAVING句はORDER BY句の後ろに書いて、追加条件を表します。人数を数えるときにCOUNT(*)とすれば上手くいきます。
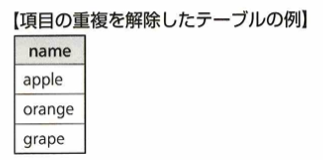
DISTINCT句はSELECT句の後ろで使用し、重複行の削除をします。
以上になりますので、本題に戻りましょう。
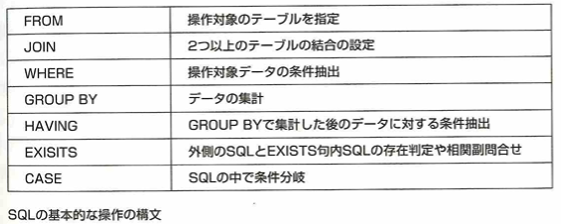
SQL(Structured Query Language)はリレーショナルデータベースのデータを操作する言語です。テーブルやインデックスを定義するDDL文とデータを操作するDML文があります。DCL(Data Control Language、データ制御言語)は、データベース管理システム(DBMS)において、データベースのアクセス権限やセキュリティを管理するためのSQLコマンドの一種です。GRANT(ユーザに特定の権限付与)とREVOKE(付与された権限取り消し)があります。
DML文の基本構文に、下記のSQL記述を組み合わせて操作を行います。
ITセキュリティ
基礎知識
セキュリティの3要素は機密性、完全性、可用性です。それぞれconfidentiality,integrity,availabilityなので頭文字をとってCIAと言います、機密性の対策はパスワード認証、アクセス権限制御、暗号化などで完全性の対策は電子署名、ハッシュ関数などで可用性の対策はシステムの二重化、バックアップなどです。ISO/IEC27001 (JIS Q27001)やISMS(情報セキュリティマネジメントシステム)にはCIAの実現が書かれています。
攻撃と防御手法
アクセス権限を制御することに対して、付与するアクションを認可と言います。これらを考えてデータ資産に対して適切なアクセス権限を設定します。以下のような複数レベルでのアクセス権限管理があります。OSレベル、ネットワークレベル、アプリケーションレベルです。
暗号化技術
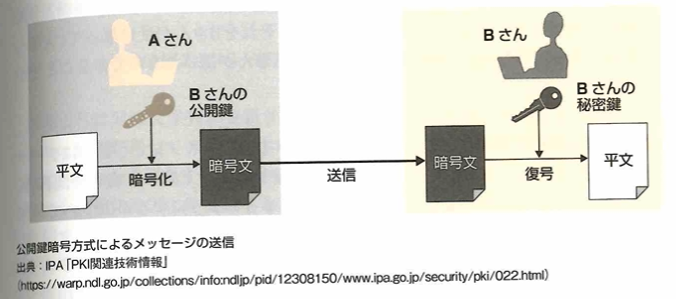
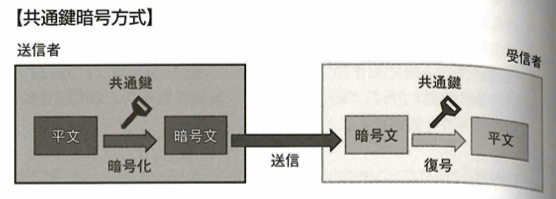
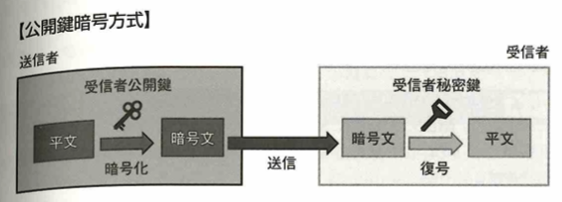
共通鍵は、同じ送信者と受信者が何回も通信をやり取りする際は有用です。公開鍵暗号方式は、秘密鍵で暗号化されたデータは公開鍵で復号可能で、公開鍵で暗号化された鍵は秘密鍵で復号可能です。共通鍵暗号方式の方が漏洩リスクが高いです。SSLでは公開鍵暗号方式を用いて通信を行う2者間で一時的な共通鍵を共有して、その後は共通鍵方式で暗号化を行います。
電子署名は対象データが作成者本人によって作成されたものです。公開鍵暗号方式を活用して電子署名を実現する動作の流れは以下です。

送信者と送信者の公開鍵の関係を保証し、送信者が信頼できる人物や組織であることを証明するため、公開鍵認証基盤(PKI:Public Key INfrasuructure)があります。利用者はこのPKIの認証局に登録された利用者情報と公開鍵を信用してデータ通信を行います。
データを送信する際にメッセージの暗号化を行い、安全にデータを送ることができる仕組みが以下です。
公開鍵暗号化方式のデジタル署名は以下の流れです。
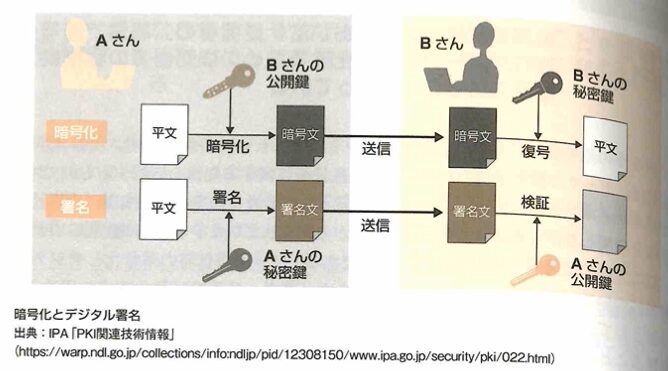
ハッシュ関数は特定の文字列を別の数値文字列に変換する関数です。例えばABCDFGという文字列は8E5Aという別の文字列に変換できます。ハッシュ関数は非可逆な性質を持つので、逆の変換はできません。ハッシュ関数で変換された値は要約値やハッシュ値といいます。データを送る際はハッシュ値も一緒に格納することにより改ざんを検出できます。ハッシュ値は改ざん検出の他にも元データを効率的に検索するためのキーとして活用することもあります。ハッシュ値が短いと、元データが別でも同一のハッシュ値に変換される衝突という事象が発生します。
認証
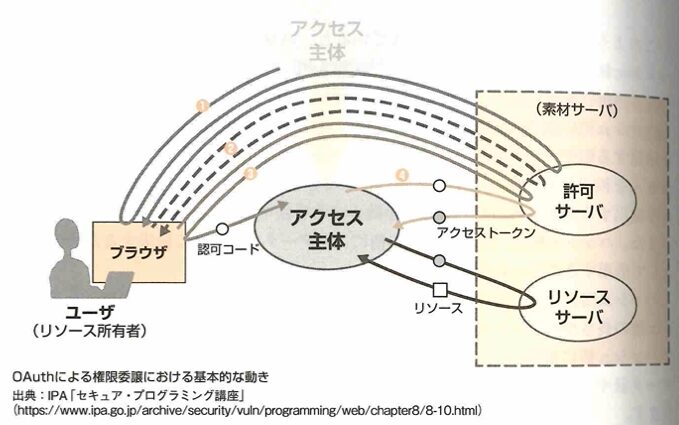
OAuthはリソースへのアクセスの認可を行うための標準仕様です。これは異なるWebサイト間でWebサービスのアクセス権限の認可を行います。このWebサイトへのアクセスやREST APIへのアクセスを許可する仕組みを認可といいます。認可で保護されるWebサイトやAPIをリソースといいます。OAuthでは異なるリソースへの認可を管理するためにアクセストークンを使用します。利用者であるアクセス主体は認証成功後に認可サーバーから一定期間有効なアクセストークンを取得します。アクセス主体はアクセストークンをリソースサーバーに渡すことにより、IDやパスワードを共有することなく、リソースサーバー上のリソースへアクセスできます。
AIシステム運用
AutoML
AutoML(Automated Machine Learning)は自動化された機械学習の略です。ソフトウェアとして提供される形態と、クラウドのマネージドサービスとして提供されるものがあります。

MLOps
バージョン管理は、開発するソフトウェアのソースファイルを蓄積し、ソースコードの変更を追跡管理する機能です。オープンソースのバージョン管理システムとして有名なのがGit、Subversionで、実際に多くのプロジェクトの開発現場でこれらのバージョン管理ツールが採用されています。特にGitをベースとしたウェブサービスであるGitHubはオープンソースソフトウェアの開発ソースやドキュメントの公開に広く活用されています。バージョン管理ツールのドキュメント格納領域をリポジトリといいます。Subversionは集中リポジトリ方式であるのに対して、Gitは分散リポジトリ方式をとっています。RやPythonなどの開発言語を用いて分析モデルをプログラミング開発する場合も、バージョン管理ツールは有用です。バージョン管理ツールを導入するメリットは以下です。

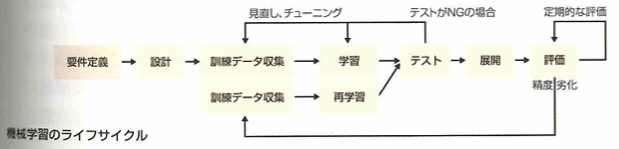
MLOpsはDevOPS(developmento+operations)のエンジニアリング手法やプラクティスを応用し、機械学習モデルの開発から運用までのライフサイクルを統合して分析モデルを継続的に発展させるための実践的手法です。MLOpsはmachine laeaning+operationsです。機械学習モデルの開発と展開に加えて継続的なモデルの評価と訓練データの再取得、モデルの再学習などのライフスタイルを管理します。モデル構築後も定期的な精度の評価と維持・改善活動が必要になります。
AIOPs
AIOps(Artificial Intelligence for IT Operations)は人工知能の技術分野を活用し、コストや負荷のかかるIT運用管理を自動化、簡素化するとともに、IT運用に関わる様々な問題を解決し、システムの品質向上、安定運用を目指すソリューションです。活用事例として以下があります。

生成AI
プロンプトエンジニアリング
生成AIを活用する際はプロンプトエンジニアリング(プロンプト技法)を用いたり、各種APIパラメータの設定を行います。プロンプト技法にはFew-shot Prompting(生成AIに対して同じタスクの入出力ペアを数個与えることでパターンを学習できます)やChain-of-Thought(生成AIに対して思考過程の複数ステップを順番に学習させてから実行させることで、より複雑なタスクを解決させます)などがあります。APIパラメータにはTemperature(モデルが予測する各単語の確率分布に影響を与え、選択肢の確率の大きさを調節します。Temperatureが高いと確率の差が小さくなりランダムに単語が選ばれすくなりますが、低いと確率が高い単語が選ばれやすくなり、文法的で論理的な文章が生成されますが、創造性が低くなります)やTop-p(次に選ばれる単語の候補を確率の高いものから選び、累積確率が閾値pを超えるまで制限します。Top-pは選択肢として考慮される単語の範囲を制御しますが、これが高いと選択肢が広がり、多様な単語が選ばれる可能性がありますが、生成品質が落ちます)があります。
top-pについて、「吾輩は」に続くのは猫が最も確率が高そうで、それをtop-1とします。しかし犬かも知れません。それをtop-2とします。このようにするとtop-pのpを大きくするとランダムだが品質が低下することがわかります。Temperature(言語モデルごとに調整)は猫や犬などの散らばり具合を表します。温度が高いと猫や犬などは似たような確率で登場するので散らばりは小さくなり、温度が低いと猫などが極端に大きく、犬以下が小さいなどが起こるので散らばりが大きくなります。つまり温度は確率間の差のイメージです。
画像生成AIは文章(プロンプト)を入力して該当する画像を自動で生成します。様々な種類のAIがあり、標準機能として事前学習済みモデルを選択できます。サービスによっては自ら用意したデータLoRA(Low~Rank Adaptation)を活用してチューニング可能です。入力は的確で具体的であることにして直接でシンプルな表現します。入力は説明的で、詳細を付け加えていきます。そして正しい文法や表記で入力し、ネガティブプロンプトや強調構文などは生成AIごとに違うのでルールに合わせて利用します。
コーティング支援
大規模言語モデル(LLM)を用いて文章で指示するだけでコードの作成、修正、改良が可能となりました。

上のようなメリットだけでなく下のようなデメリットもあります。

適切なダミーデータの作成は大事です。大規模言語モデルでは類似ダミーデータを自動的に生成できます。

上のメリットだけでなく下のデメリットもあります。

以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『データエンジニアリング力の知識』の復習です。
プログラムやツールを用いてwebサイトからデータを取得することをWebスクレイピングと言います。コピペなどをツールなどを用いて自動化する感じです。これまではPythonなどのコーティングに関する知識がないと実行できませんでしたが、現在ではスクレイピングツールを利用でき初心でも簡単にコーティングできます。代表的なものにoctoparse(視覚的にデータを抽出できるツール)とimport.io(URlを入力するだけでwebサイトのデータを抽出できる)があります。Webクローリングはリンクを辿ってwebサイトを巡回する技術です。APIはプログラム同士で通信を行う仕組みです。HTTPを用いて通信されるAPIをWebAPIと言います。Xなどのよく使うサービスに利用されるWebサービスです。APIの設計思想にREST APIがあります。SOAPはXMLフォーマットで通信を行うプロトコルを定義したものです。APIを応用し、SNSやWebサービス間でアクセス権限の認可を行うプロトコルであるOAuth認証が実現されています。
RDBはテーブルという単位(列はカラムで行はレコード)で管理され、関係(リレーション)という概念でモデル化されます。SQL言語を用います。ソフトウェアはRDBMSを用います。例えばMySQL、PostgreSQL、Oracle Rdbなどが有名です。 ER図を用いてデータベースの構造を俯瞰します。一方でNoSQLはデータベース管理方式を指す言葉で、RDBを管理するためのシステムではありません。SQLを用いずデータベースにアクセスできる仕組みをNoSQLデータストアと言います。データを単に保存しておく場合は、単なるストレージを用います。Amazon S3、Google Cloud Storageなどの利用で、オンプレミスにストレージ用のサーバーを置くより少ない運用工数でストレージを利用できます。
エンティティとはデータのまとまりです。
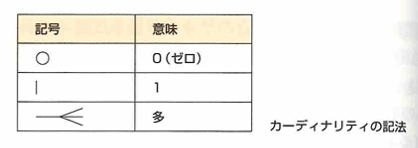
アトリビュートはエンティティ内の各要素です。カーディナリティ(多重度)とはリレーションの始点と終点を一定の記号で表現することです。記号○は0という意味で|は1という意味です。鳥の足(カラスの足からCrow's Feet記法とも呼ばれます)のような記号は2以上という意味です。
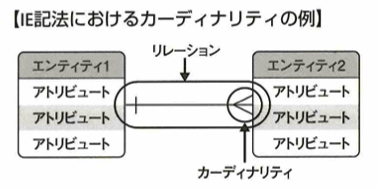
記法はIE記法の他にIDEF1X記法もあります。こちらの方がIE記法よりも用いる記号の種類が多く、より詳細に表現ができます。
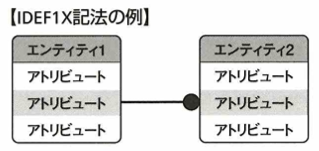
主キー(行つまりレコードを一意に特定するための列つまりカラムを指す用語)と非キー(主キー以外)に対して、非正規形とはデータの冗長性や不整合がある状態を指す用語です。
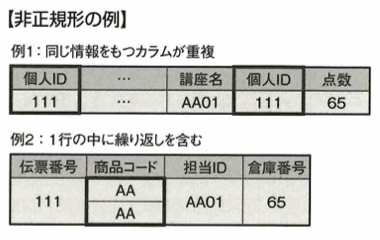
第1正規形は非正規形の持つ冗長性や不整合が解消された状態です。
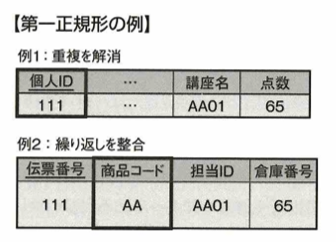
次に第2正規形を考えます。次の図で主キーは講座コードと社員IDです。講座名は講座コードに一意に決定してしまうので、非キーが主キーの一部のみに対して従属しています。この状態を部分関数従属と言います。
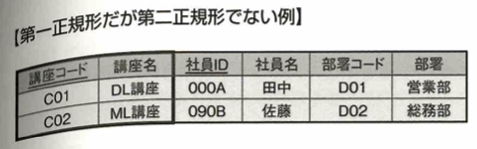
この状態を解消したものを第2正規形と言います。要するに見やすくするということです。
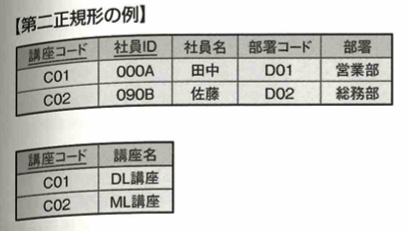
こうすることにより、非キーである講座名が後から変更になった場合、それに対応するテーブルを1行変更するだけデータを改変できます。第1正規形のままだと対象となる全ての講座名を変更する必要があります。
次に第2正規形ですが第3正規形でない例を考えます。主キーの部署コードと非キーの部署について考えます。
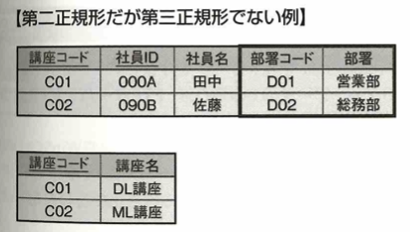
非キーである部署コードが決まると非キーの部署も一意に決まります。このような状態を推移的関数従属と言います。この状態を解消したものが第3正規形です。
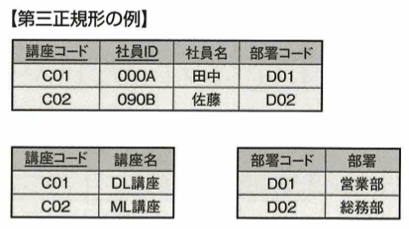
非キー列は主キー列に対してのみ従属し、推移的関数従属は解消されました。
FTPはネットワークを介してデータをやり取りする手順です。FTPサーバとFTPクライアントの間で行われます。データの暗号化が行われていないのでセキュリティ面で問題があります。SCP(Secure Copy Protocol)はファイル転送においてFTPよりセキュリティ面で優れています。他にはSFTPもありますが、通信速度の観点からSCPの方が優れています。HTTPSはTLS(以前はSSL)を用いて暗号化します。
Jupyter NotebookはPythonを実行するためのWebアプリケーションです。Tableauはプログラム言語でなく、データ分析を容易にするBIの一種です。GUI上、つまり画面上で感覚的に操作できます。DBeaverはGUIを介したデータ操作を可能にするツールです。各種データベースに接続しSQLを用いたデータの加工と取り出しを行えます。言語ソフトはバージョン管理ソフトウェア(GitやSubversion)などが大事です。
分散ファイルシステムとはデータを複数台のコンピュータに分散保存しネットワークを介して管理するシステムです。Apache Hadoopはこのようなソフトウェアの1つです。Java言語で開発され、開発元のASFによってオープンソースソフトウェアとして公開されています。MapReduceは分散保存されたデータを収集し、計算処理を施すフレームワークでグーグルが提案しました。Sparkはクラスターコンピューティング向けです。MapReduceの処理速度を向上しています。データをSSDなどではなくメモリに保管することで、高速処理が可能です。Flickerは写真拠有サービスです。
アクセス制御の3要素は、認証・認可・監査です。ににかと覚えます。認可についてアクセス制御リスト(ACL:Access Control List)も大事です。
データの暗号化は日立ソリューションズ社が提供する「秘文」があります。
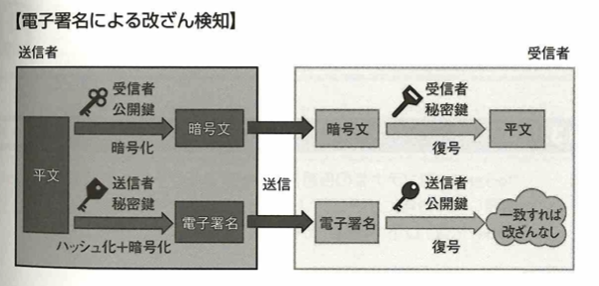
電子署名のところは公開鍵暗号方式とは逆になるので注意です。電子署名以外はすべて受信者の鍵で処理します。電子署名は送信者の鍵です。ハッシュ関数とはデータ長にかかわらず、固定長データを出力する関数です。得られるデータをハッシュ値と言います。アルゴリズムはMD5、SHA-1、SHA-2、SHA-3などがあります。SHA-2やSHA-3の中にも種類があり、ハッシュ値のビット数に応じて名称が変わります。ハッシュ関数の性質は、同じデータからは同じハッシュ値が得られることです。
Dockerはコンテナ型の仮想化を実装するソフトウェアです。オープンソースとして公開されています。動作が軽く、可搬性が高く、疎結合(機能の変更などが他のサービスに影響しない状態)が特徴です。Deeplcallfact Hubというリポジトリ(Dockerのイメージが保管されている場所)からさまざまな定義済みイメージを入手できます。Linux、Ubuntuはオペレーティングシステムの名称です。
フローチャートのルールは、処理の流れは上から下へ、左から右へで、それと逆行するときは矢印をつけます。線が交差しないようにします。2つ以上の線を集めて1つの線にしてもOKです。

AutoMLは自分でプログラムを組まなくても画面を操作して機械学習モデルを構築できるサービスです。例えばPredictionOneやDataRobotなどがあります。
以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『データエンジニアリング力のSQL』の復習です。
RDBMS(Relational Database Management System)はRDBの管理システムです。MySQLはオープンソースのRDBMSです。PostgrereSQLはオープンソースのRDBMSです。カルフォルニア大学バークレー校にて開発されました。SQLiteはサーバとして利用するのではなくアプリケーションに組み込んで使用するRDBMSです。HeidiSQLはGUIを利用して使用します。通常のRDBMSは行単位でデータ保持をし、IBM Integrated Analysis Systemなどがあります。
データを取得するテーブルを指定するのは、FROM テーブル名です。JOINは2つのテーブルを結合して1つのテーブルとして扱います。ORDER BYはSELECT句で取得したカラムに対して昇順や降順といったルールでデータの並び替えを実施する句です。GROUP BYは指定したテーブルをグループに分割する際に利用する句です。HAVING句と併用して、分割したグループに対して集合関数を適用できます。HAVING句は一度集計されたデータをもとに、さらにデータを条件抽出したい場合に用います。PostgreSQLやMYSQLなどのデータベースから取り出したデータはCSV形式でエクスポートできます。
テーブルに含まれる全カラムを取得するには、SELECT * FROM テーブル名です。
重複行を削除するには、DISTINCT カラム名です。

この時に、SELECT文の後に「DISTINCT name」と指定すると次のようなります。
取得したデータの並び替えを行う場合は、ORDER BY カラム名です。
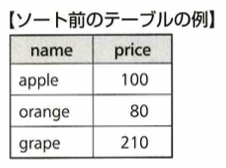
上のデータに対してASCは昇順、DESCは降順を用います。「ORDER BY price ASC」を適用すると次のような結果になります。
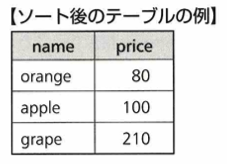
取得したデータに対し、最終的に取得するレコードの数を指定する句がLIMITです。「LIMIT+取得したい行数」という句を追加して使用します。ORDER BY句と併用して。上位◯名などと結果を取得したい場合に有効です。
SQLの記述の順番は、SELECT→FROM→WHERE→GROUP BY→HAVING→ORDER BY→LIMITです。
SQLは複数のテーブル結合が可能です。
LEFT OUTER JOIN(左外部結合)とFULL OUTER JOIN(完全外部結合)、INNER JOIN(内部結合)、RIGHT OUTER JOIN(右外部結合)があります。LEFT ORDER JOINの場合は、結合軸が一致しないレコードはNULLと表示されます。

FULL OUTER JOINの場合は次のようになります。

INNER JOINについては次のようになります。
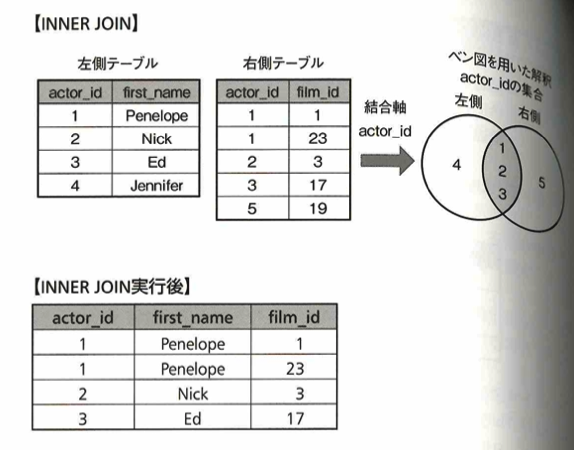
RIGHT OUTER JOINはLEFT OUTER JOINと同様に考えることができます。
NULL値を他の値で置換することは可能です。この際は、INFULL関数やCOALESCE関数を用います。テーブル結合を用いればデータの突き合わせも行うことができます。
カラムのデータ型を変換するには、CAST(カラム名 AS データ型)です。PostgreSQLでは、カラム名::データ型の表現で使用します。
SQLにおけるレコードの無作為抽出は、ORDER BYとRANDOM関数を組み合わせて実現できます。取得件数制限では、LIMIT句を使用します。ORDER BY random()でテーブルのレコードをランダムに並べ替え、その後にLIMITによって指定された数だけレコードを取得します。ただしORDER BYによる何十万もの並び替えはCPUに負荷をかけるので注意です。
SQLでは条件分岐を行うためにCASE式が用意されます。単純CASE式と検索CASE式があります。次の例ではstatusカラムの値を1、2、3にそえぞれ返すように指定しています。

次の検索CASE式では等号=以外の演算も行って値を評価できるので、単純CASE式よりも柔軟性があります。

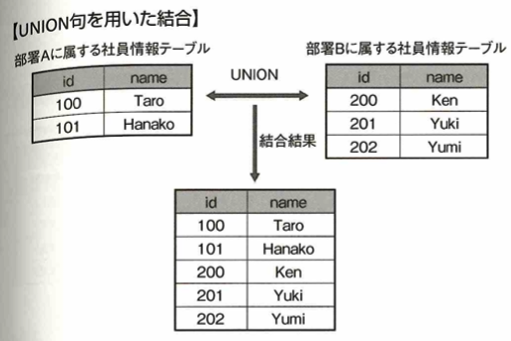
複数のSELECT文で取得したデータを結合する句はUNION句です。
SQLで新しくテーブルを作成する際の基本構文は次の通りです。

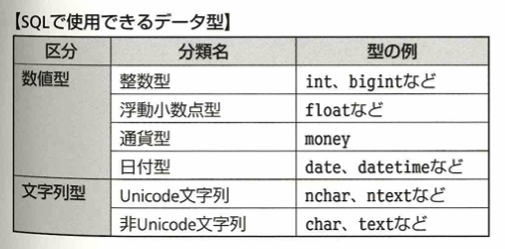
SQLで使用できるデータ型は次のものがあります。
テーブル作成時に指定できるオプションの一例は以下のようなものです。

作成したテーブルにデータを挿入する際の構文は次の通りです。

EXIST句は指定した条件に合致するレコードが存在するか判定できます。
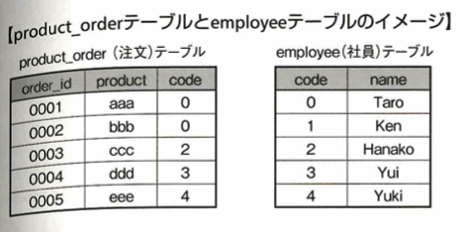
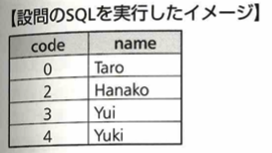
以上の2つのテーブルに対し、SQLを実行すると次のような結果が得られます。つまりそれぞれのテーブル間でcodeという結合軸が一致するかを判断し、一致する場合のみSELECT文を実行します。
CRFEATEは新しくテーブルを作成する際に利用します。
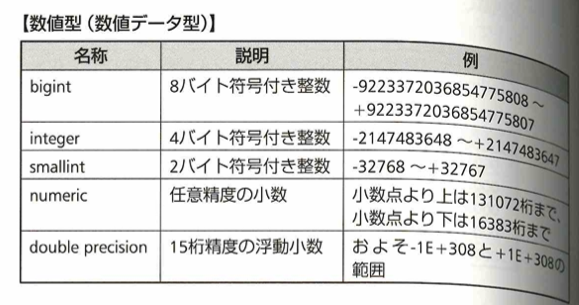
booleanは真偽値を表す論理値データ型です。それ以外は数値型(数値データ型)と言います。次の表にあるnバイト符号付き整数について説明します。符号なし整数→符号付き整数を考えた方がわかりやすいです。まず符号なし整数で2バイト整数の範囲を考えます。2バイト=16ビットなので0〜(2の16乗)−1=65535まで表現できます。そのため符号付き整数の範囲は、-32768~+32767となります。左右の数字が1多いか少ないかは文献によります。
PostgreSQLでは乱数を生成する関数であるRANDOM関数を利用できます。特に生成範囲を指定しない場合は、0以上1未満の不動小数点値を生成します。RANDOM関数の構文は、random()です。RANDOM関数を応用すると、テーブルからレコードをランダムに取得できます。
LIKE演算子は指定した条件が検索文字列に合致した場合にTRUEを返す演算子です。カラム内の各フィールド値に対してパターンマッチを行い、TRUEを返すものだけ取得する際に、WHERE句の中でLIKE演算子を用います。LIKE演算子によるパターンマッチは常に文字列全体で行われます。パターンマッチに用いる文字列には2種類の特殊記号を用いることができます。文字列の検索時にワイルドカード指定を行えます。

SQLではSELECT文で取得したデータに対して集合関数を用いて最大値や最小値を集計できます。
ORDER BY カラム名 DESCは指定したカラム内のデータを降順に並び替えます。 PostgreSQLなどのRDBMSでは中央値はPERCENTIKE_CONT関数引数を0.5とすることで、最頻値はMODE関数を用いることで、それぞれ求めることができます。
次はデータサイエンティスト検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』の該当する章『データエンジニア力』の復習です。
オープンデータはCSV形式が多いです。フルバックアップのためにシステムを停止する必要があります。サーバ構成はクラスタ構成です。HPCクラスタ(スケーラビリティ。拡張性つまり並列処理で効率を上げます。)とHAクラスタ(ハイアベイラビリティ。冗長構成。)があります。クラスタ構成をクラスタリングと言います。サーバ仮想化の中にコンテナ型仮想化があります。DockerエンジンをインストールしてDockerイメージを配布します。
SDKはアプリ開発のためのソフトウェア開発キットです。JDKが例です。APIはアプリ開発のための仕様(インターフェイス)です。ライブラリで提供されます。クローリングはHTMLの収集でスクレイピングはHTMLから特定の情報を収集します。SSHで遠隔コンピュータに接続します。ログ出力はサーバー上のログファイルに蓄積します。Pythonではloggingライブラリを用いて出力します。JSON、XMLは構造化データです。データ分析のためにRDBMS(行指向型DB)→DWHに移します。ここではDWHアプライアンスが使えます。これはカラム指向型(列)DBを採用しています。これは統計処理に適しています。DWHは一台のコンピュータで動かすので分散技術(Hadoop、Spark)を使います。
Hadoopの構成は、マスターサーバ(システムの管理コンピュータ1台)とスレーブサーバ(データ処理を行う複数サーバでMapReduceというMap処理(抽出、分解、振り分け)とReduce処理(集計、出力)を行います)を結ぶHDFS(データを集計しスレーブサーバに書き込みます)で構成されます。これで分散蓄積が可能です。メリットはMapReduceのストレージの大きさで、デメリットは頻繁の更新では処理速度が低下することです。Hadoop2系はMapReduce→YARNに変更されました。
SparkはHadoopより構成が複雑です。MapReduce→RDD(ストレージに書き込まずメモリ上で保管するので処理速度が速いです)を用います。RDDと同様のAPIでDataFrame、DataSetがあります。
HDFSでのカラム指向型DBがHBaseです。これはNoSQLです。これはスケーラビリティが高いです。一般にAPIで操作します。
RDBを操作するにはSQLの言語が使用されます。DDL(データ定義言語)とDML(データ操作言語)があります。Where句のSELECT文を副問い合わせといい、( )で囲います。NULLを規定値に変換する際はCOALESCE関数を用います。マスター(対応表)データの変更履歴を保存することをSCD(スロー・チェンジ・ディメンション)と言います。オラクルはRDBMS製品です。エクセルはCSVファイルをShift-JISで読み込みます。エンタープライズBI→セルフBIになりました。Web上でデータのやり取り規格にREST(WebアプリからXMLやJSON形式で取得。REST APIを用います。処理が速く入力パラメータが少ないサービスに向きます)やSOAP(異なる言語間でのやり取りで用います。XMLベースで定義されます。高機能のため複雑な入力やチェックなどに適します。)があります。
集中リポジトリ(リモートリポジトリ)の管理システムにはSubversionがあります。分散リポジトリ(ローカルリポジトリ→リモートリポジトリに変更を反映)の管理システムにはGitがあります。WebサービスではGitHubでオープンソースです。
コンピュータウイルスは既存のプログラムに寄生し感染します。ワームは単独で感染します。
マッピング処理はある値を別の値と対応づける処理です。表記揺れによるデータ不整合を防止します。システムCPU時間はOSが使用しているCPU時間です。
緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』のデータエンジニアリングの節末問題は類書には見られない問題が多くかなり重宝しそうです。何度も繰り返して盲点をなくしていく学習をしたいところです。
ビジネス力
行動規範
ビジネスマインド
ビジネスにおける分析的でデータドリブンな考え方に基づいて行動するとは次の4つを意味します。
分析対象となるビジネスに関わるステークホルダーの利害や目的と合致
分析目的を満たすための論理構成
論理構成から必要となるデータを想定・準備できている
分析により得られた結果から意思決定する
ビジネスの目的を考え、ビジネスの目的を達成するための課題・仮説を考え、原因・解決策を探るためのデータを準備します。つまり目的、論理、データの3階層を常に意識することが大事です。
KGI(Key Goal Indicator)重要目標達成指標やKPI(Key Performance Indicator)重要業績評価指標の変化を数値目標として定義することは大事です。これらを欠くと次のことが起こり得ます。
目的やゴールを明確に設定しないまま分析してしまう
取得したデータを手当たり次第集計し、疑ったグラフを作ってしまう
最先端の機械学習アルゴリズムを適用し、重箱の隅をつつく分析をしてしまう
課題や仮説の言語化は問題解決スキルの1つです。これらはプロジェクト遂行する上での軸であるとと同時に変化するものです。

課題や仮説を言語化するために問題解決力、論理的思考、メタ認知思考(客観的に見る)、デザイン思考などがあります。
一次情報(データ収集などの情報)、二次情報(他社が書いた本など一次情報を編集した情報)、三次情報(噂話のような出どころ不明な情報)があります。
データ・AI倫理
不正行為を行わない倫理観は大切です。捏造、改竄、盗用これらは、fabrication,falsification,plagiarismの頭文字をとってFFPと言われています。この倫理の問題はデータバイアスによるAIの差別的判断やディープフェイクと言われる技術の危険性があります。データ倫理はデータの倫理、アルゴリズムの倫理、実践の倫理の3つから成っており、ELSI(ethical,legal and social issues)つまり倫理的、法的、社会的課題の研究も盛んになっています。2019年に内閣府から出された人間中心のAI社会原則も、このデータ倫理の問題に対する政府の意思が一部反映されています。
フェイク動画による人権侵害などはあってはなりません。ディープフェイクとは、このようなフェイク動画を深層学習で作り出す技術です。敵対的生成ネットワーク(GAN)の発展による影響が大きいです。それ以外ではオートエンコーダーなどの深層学習技術が使われており、フェイク動画などの作成が行われます。現在ではBotを大量生産し、それがフェイクニュースを流す構造になっています。この要因として生成AIの発展があります。OpenAI社が発表したChatGPTやマイクロソフト社のAzure製品への組み込みなど、大規模言語モデルが実用的になりました。チャットボットが暴言を吐くなど、様々な事例が問題となっています。これはAIの公平性などの考察に大事な考えです。
コンプライアンス
どのような場合の法令に注意すべきか、何がリスクか、倫理的に許されないことは何か?をおさえます。2018年におけるGDPR(general data protection regulation)EU一般データ保護規則では、細かい要件などが定められています。CCPA(california consumer privacy act)カルフォルニア州消費者プライバシー法も2020年から適用開始されました。2023年からはCPRA(california privacy rights act)カルフォルニア州プライバシー権法が施行され消費者の権利が強化されています。日本でも2022年に改正個人情報保護法が施行されました。2023年には改正電気事業法が施行されました。

倫理的思考
MECE
MECE(ミーシー)はもれなく重複なくという意味で、mtutually,exclusive,collectively,exhaustiveつまり、お互いに、重複せず、全体的に、漏れがない頭文字をとったものです。論理的思考の最も基本的な考えです。
構造化能力
分析課題周辺のビジネスの実態や背景知識をイメージし、インプットとアウトプットのイメージ、分析手法やその手順をイメージし、初動としては、事前に準備することは何か?分析課題や当該領域の重要なポイントの整理、進め方の仮案のイメージを持っておけば十分です。
言語化能力
目で見て捉えた事実と、考察から導かれた意味合いの言語化が重要です。
ストーリーライン
一般的な論文構成の流れをおさえます。

ドキュメンテーション
引用についても大事です。
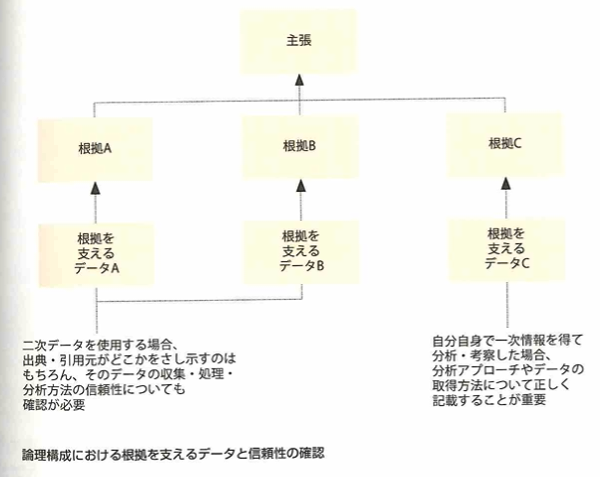
直接引用が短い場合は「」を用いて本文中にその部分を記載します。ながい場合は、出典として転載します。
メッセージをわかりやすく伝えるには、人に理解してもらうためのストーリーラインを持った構成を先に作ることが重要です。これは2つのピラミッド構造が知られています。
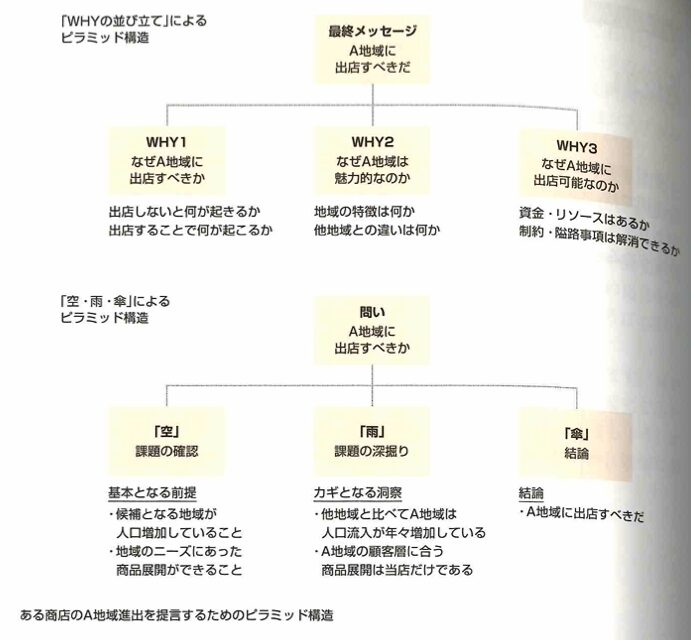
説明能力
ステークホルダーに対して報告を行う必要があります。この際に、分析の途中段階で定期的に関係者からのレビューを実施しておき、どのような論理構成で分析を進めたか、論理構成を可視化し、メンバーに共有しておき、論拠不足・論理破綻の指摘が論理構成のどの点を示しているか理解し、周囲の意見を柔軟に受け入れるマインドセットを持つことが大事です。また傾聴のスキルが必要です。
着想・デザイン
AI活用検討
以下のような活用シーンがあります。

課題の定義
KPI
KGI→KPIの順が大事です。そして収益方程式とは売上=平均客単価×客数となります。以下がKPIツリーの例です。
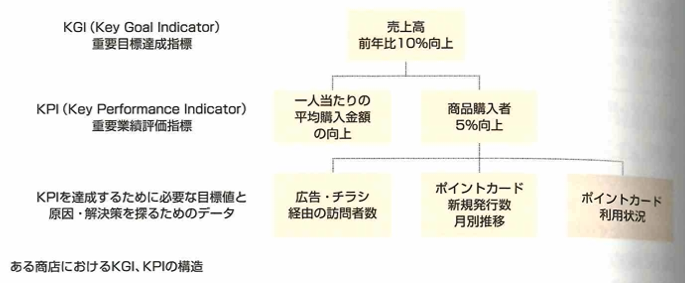
スコーピング
ビジネスとは社会に役に立つ意味のある活動全般と定義されています。スコーピングとは分析対象となる事業領域に複数存在する課題の中で、どれを取り扱うかを絞り込む作業です。事業領域、取り扱う課題領域の例を以下に示します。

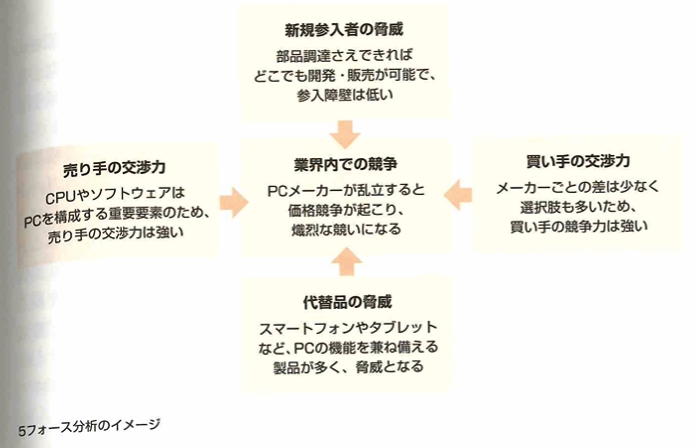
次に基本的な課題の枠組みについて整理します。この時、品質(適切な品質を保証するため品質をより良くするための活動)、価格(適切なコスト管理をするための活動)、納期(適切な納期までの行程を管理するための活動)を用います。また、自社の競争優位性を探るために5フォース分析を行うこともあります。
分析する上でプロジェクトとして把握すべき要素は、分析目的において取り扱うデータ範囲、データ分析に必要となるデータ取得方法、データ分析にかかる時間、データ分析のための統計解析や機械学習モデル、実行環境です。
アプローチ設計
データ入手
アクセスを確保できるということは下記を意味します。問題を探索する上で、どのような仮定を検証すれば良いかを理解でき、仮説の検証に必要なデータがどのようなものかを洗い出すことができ、洗い出したデータが入手・使用可能か検証できることです。
分析アプローチ設計
データサイエンスのプロジェクトでは、まず分析プロジェクトの目的を明確にします。次に目標達成のため、どのような結果がデータ分析の結果から導き出せると良いか仮説を立てます。この際に、プロジェクトのタスク量や人的リソースの見積りもできると良いです。
生成AI活動
ハルシネーションは大規模言語モデルが事実に基づかない、あるいは誤った情報を生成する現象です。

対処法として生成された情報の根拠を追求する姿勢が大事で、他に信頼できる情報ソースや他LLMの出力結果と比較して、一貫性や正確性を検証することは必須です。
データ理解
統計情報への正しい理解
エビデンスベーストとは根拠に基づいたという意味で、個人の勘や思い込みでなく、事実やデータをベースに判断する考え方です。
ビジネス観点での理解
ビジネス観点で仮説を持つこと、課題を発見できることは、データサイエンスをビジネスに適用する第一歩です。データ分析プロジェクトがPoC(PFpresent present Concept)概念実証で終わってしまうのは、仮説と異なる結果をステークホルダーが受け入れず、データ分析は使えないという不名誉な烙印を押されるといったこともあります。
事業への実装
評価・改善の仕組み
モニタリングとは、ビジネスの本来の目的・目標を達成するために、何が起きているのか、今後どのようなアクションをすべきかといった判断につながる評価・改善活動を指します。
契約・権利保護
契約
機密保持契約では二者それぞれ持つ営業や技術に関する情報などをある一定の期間の範囲・用途において、相手側へ開示する範囲、情報の活用、漏洩しないためのルールの取り決めなどを行います。プロジェクト開始前に前もって締結されるものです。販売許諾契約は相手が持つ製品・サービスについて決められた範囲においてその販売の許諾を得るもので、一定の期間で販売された売上の何%かをロイヤリティとして支払ったり、あるいは独占的に販売する権利を持つといった取り決めをします。個人情報の授受に関する契約は2者間でそれぞれの製品・サービスを利用する顧客に関する情報を取得・開示・管理・破棄する取り決めです。業務委託契約は請負契約、委任契約、準委任契約に分類されます。請負契約は、委託社が仕事の完成と引き換えに受諾社に報酬の支払いを約束する契約です。準委任契約は委託社が法律行為でない事務処理を受諾社に委託する契約です。
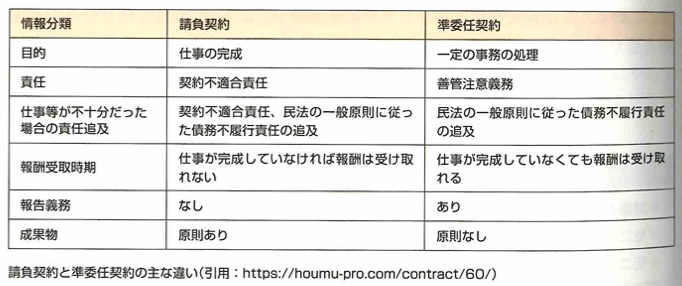
権利保護
大規模言語モデルに秘密情報を入力してしまった結果、意図せずその情報が大規模言語モデルの学習に利用され、外部に流出し企業が謝罪する事態になる可能性があります。そういった意図しない情報漏洩などのリスクから利用者を守るためにガイドラインを理解し遵守することが大事です。
PJマネジメント
プロジェクト発足

リソースマネジメント
下記のような模索を考えます。

スケジュール管理などは、WBS(work breakdown structure)やガントチャート、マインドマップなどを活用してタスクを洗い出し、工程表を作成すると効果的です。
リスクマネジメント
レピュテーションリスク(悪評や風評によって企業価値が下がり、経営に支障をきたす危険性)に注意します。障害報告書や発見時の報告手順などを確認します。5W1Hをもとにします。サービス品質の考え方も大事で、SLA(サービス品質保証)としてまとめ遅延や障害などの対処方法を契約書として記述することも大事です。
以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『ビジネス力のプロジェクト推進』の復習です。
データサイエンティストの役割は、データの分析の結果得られた知見をビジネスに活用することです。つまり仕事内容はデータ分析のみでなく、現場における意思決定をサポートしビジネスに貢献することが求められます。データ分析では、仮説検証に必要なデータ量を確保し、二次データを利用する際は、著作権、ライセンス、利用規約に配慮し、個人情報が含まれるデータのさいは、取り扱いに注意するなどがあります。データ選択では選択バイアスが含まれていないか確認します。5フォース分析は自社が晒されている脅威を5つの項目に分類し、自社が置かれている競争環境を分析するフレームワークです。業界への新規参入企業の存在、代替製品の存在、売り手の交渉力、買い手の交渉力、競合他社の存在です。AIDMA(アイドマ)は顧客購買モデルで、Attention、Interest、Desire、Memory、Actionの頭文字です。つまり消費者が購入決定に至るまでのプロセスを5つに分類して消費者の購入のモチベーションがどこにあるかを探ります。CVCAは顧客価値連鎖分析です。Customer Value Chain Analysisです。各ステークホルダー間の商品、金銭、情報の流れを可視化します。
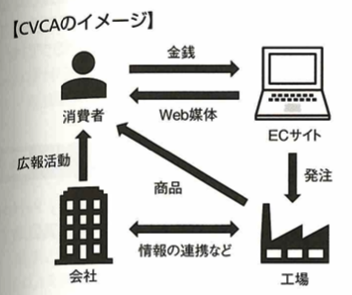
RFM分析は自社の顧客の特徴を深く理解するものです。顧客をRecency、Frequency、Monetary(購入金額)で考えます。
MECE(ミーシー)とはMutually、Exclusive、Collectively、Exhaustiveの略で漏れなく、重複なくという意味です。AISAS(アイサス)は電通が提唱し、AIDMAのモデルにインターネットの購買行動を追加した考えです。つまり、Attention、Interest、Search、Action、Shareの5つに分類します。
OKRは目標と主な結果です。SMARTは目標を達成するための指標です。Specific、Measurable、Achievable、Related、time-boundの略です。CSFは主要な成功要因です。最終目標のKGIを達成するために最も大きな影響を及ぼす要因を指します。CSFはSWOT分析により設定されます。
入手したデータを理解するためデータサイエンティストは、生データの中身を直接確認し、外れ値や欠損値がないことを確認し、データをグラフ化し全体的な特徴を把握し、基礎統計量(平均、標準偏差など)を算出し、全体的な傾向を把握します。レポート分析にはBIツールのレポート編集機能を用いると便利です。ビジネスにおいて論理とデータの重要性を認識し、分析的なデータドリブンな考え方に基づき行動できることがデータサイエンティストに求められる素質です。データドリブンとは、過去の経験や勘のみに頼るのでなく、データ分析結果を元にビジネス上の意思決定を行うことです。
請負契約と準委任契約の違いについてまとめます。
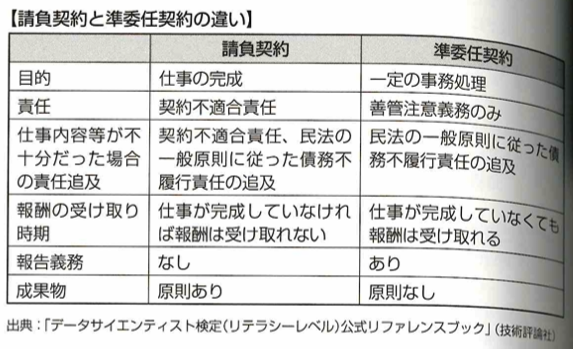
以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『ビジネス力の法律・倫理』の復習です。
個人情報において、個人識別番号(DNA、声紋、マイナンバー、免許証番号など)も含みます。つまり他の情報と容易に照合できるものです。そのため会社の財務諸表や自治体の人口などは団体情報として扱われるので個人情報ではありません。匿名加工情報とは、特定の個人を識別することができないように個人情報を加工し、復元できないようにした情報です。本人の同意を得ることなくデータを事業所間で共有できます。個人識別符号を削除しただけでは、匿名加工情報に関する全ての加工措置を行ったことにはなりません。個人識別符号とはその情報だけでも特定の個人を識別できる文字、番号、記号、符号などです。個人識別符号も個人情報とみなされます。匿名加工情報は個人情報を加工し、復元できないようにしていて、個人識別符号はそれだけで個人を特定できるものです。仮名加工情報は、他の情報と照合しない限り、特定の個人を識別できないように個人情報を加工したものです。つまり仮名加工情報の加工要件は、匿名加工情報に比べて緩和されています。仮名加工情報を扱う際、削除情報などの安全管理措置の対応義務が生じますが、漏洩などが生じた場合にその旨を個人情報保護委員会に報告する義務はありません。仮名加工情報は、対照表と照合すれば本人がわかる程度に加工された情報のため、個人情報に該当する場合としない場合があります。匿名加工情報は復元できませんが、仮名加工情報は照合すれば復元できるのが違いです。
オプトアウトは一定の条件を満たす場合に、本人の許可がなくても第三者に個人情報を提供できる制度です。オプトインは事前に本人の許可を得ることです。認定個人情報保護団体とは事業者の個人情報を適切な取扱いの確保を目的とし、個人情報保護法で定められた民間団体です。個人情報を有する国内全ての事業者が個人情報保護法における規制対象になりました。
GDPRの前身はEUデータ保護指令です。GDPRによるデータ保護対象として、cookieなどのデジタル情報が該当する可能性があります。自然人の基本的な権利及び、自由、並びに、特に、自然人の個人データの保護の権利を保護します。CCPAはカルフォルニア州消費者プライバシー法で、米国の個人情報保護法です。CPRAはCCPAの改正案で、カルフォルニア州プライバシー権利法です。GPDRは年金積立金データ管理を指す用語です。
個人情報取扱事業者は利用目的の達成に必要な範囲を超えて個人情報を取り扱ってはなりません。利用する際は通知・公表の義務があります。本人の同意を得ずに第三者に個人データを提供してはなりません。本人からの要望で削除依頼が来たら応じなければなりません。苦情なども迅速に対処します。
次はデータサイエンティスト検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』の該当する章『ビジネス力』の復習です。
目的を満たす論理(目的、仮説、準備)→分析→意思決定
捏造は存在しないものを生み出すことです。MECEは漏れなく重複なく。言語化するのは客観的事実と意味合いです。ストーリーラインはWHYの並べ立てと空・雨・傘です。収益方程式=平均顧客単価×客数です。KPIツリーでKGI→KPI→KPIを達成するためのデータなどを考えます。スコーピングでプロジェクトで扱う範囲を決めます。事業領域の中に取り扱う課題領域があります。タスク管理はRedmine、TrelloでチャットツールはSlack、Chatworkがあります。
数理・データサイエンス・AI(リテラシーレベル)モデルカリキュラム
数理・データサイエンス・AI(リテラシーレベル)モデルカリキュラム
人間中心の適切な判断ができ、活用することが大事です。リテラシー教育として全ての大学、高専生がモデルカリキュラムを検討します。学習項目は、社会におけるデータ・AI利活動、データリテラシー、データ・AI利活用における留意事項です。
社会におけるデータ。AI利活用(導入)で学ぶこと

社会におけるデータ・AI利活用(導入)で学ぶスキル/知識
データサイエンスで、データ可視化、モデルか、モデル利活用、非構造化データ処理、生成、オペレーションズリサーチを学ぶことで、データ・AI利活用のための技術を知るとともに、AIを活用した新しいビジネス/サービスは複数の技術が組み合わされて実現していることを理解します。データエンジニアリングでは、データの向上を通して、構造化データや非構造化データ(文章、画像/動画、音声/音楽など)の特徴を理解し、社会で活用されているデータについて学びます。また、生成AIを学ぶことで、適切なプロンプトの必要性について理解します。ビジネスについて、行動規範や着想・デザイン、課題の定義、アプローチ設計を通して、データやAIを活用したビジネス/サービスの事例をしり、データ・AI活用領域の広がりを理解します。
社会におけるデータ・AI利活用(導入)の重要キーワード解説
Society5.0とは、サーバー空間とフィジカル空間を行動に融合させたシステムにより、経済発展と社会的課題の解決を両立する、人間中心の社会を目指します。society1.0,2.0,3.0,4.0はそれぞれ、狩猟社会、農耕社会、工業社会、情報社会になります。データ・AIの活動領域は、企業における事業活動がバリューチェーンに当てはめて考えることが大事です。

生成AIの活用により、文章や画像、音声などを生成できます。生成AIの応用領域として、対話やコンテンツ生成、翻訳・要約・執筆支援、コーティング支援などがあります。プロンプトエンジニアリングも大事です。
データリテラシー(基礎)で学ぶこと

データリテラシー(基礎)で学ぶスキル/知識
データサイエンスでは、数学的理解や科学的解析の基礎、データの理解・検証、データ準備を学ぶことで、データの特徴を読み解き、起きている事象の背景や意味合いを理解するスキルを身につけます。また、比較対象を正しく設定し、数字を比べるスキルを身につけます。データ可視化を学ぶことで、不適切に作成されたグラフ/数字に騙されず、適切な可視化手法を選択し、他者にデータを説明するスキルを身につけます。データエンジニアリングでは、データ加工や、データ共有を学ぶことで、スプレッドシートやBIツールなどを使って、小規模データを集計・加工するスキルを身につけます。ビジネスでは、行動規範や、論理的思考、データ理解を学ぶことで、データを読みとく上でドメイン知識が重要であることや、データの発生現場を確認することの重要性を理解します。
データリテラシー(基礎)の重要キーワード解説
データの比較については、そのデータに関するドメイン知識が必要になります。
データ・AI利活用における留意事項(心得)で学ぶこと
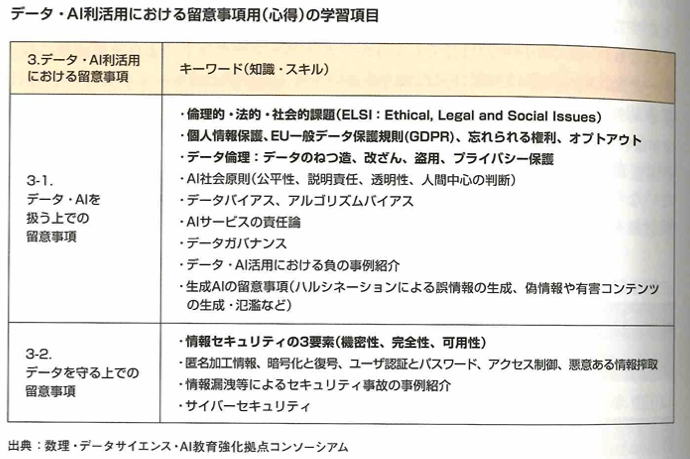
データ・AI利活用における留意事項(心得)で学ぶスキル/知識
データサイエンスでは、モデル化、生成を通して、データバイアスやアルゴリズムバイアス、ハルシネーションについて学び、データ駆動型社会におけるリスク・脅威を理解します。データエンジニアリングでは、ITセキュリティについて学ぶことで、情報セキュリティ対策を検討する際のポイント(セキュリティの33要素:機密性、完全性、可用性)を理解します。また、マルウェアなどによる深刻リスク(消失・漏洩・サービスの停止)を学ぶことで、個人のデータを守るために留意すべき事項を理解します。ビジネスでは、行動規範、契約・権利保護を学ぶことで、データの捏造、改ざん、盗用を行わないなど、データ・AIを利活用する際に求められるモラルや倫理について理解します。また、個人情報保護法やEU一般データ保護規制(GDP)など、データを取り巻く国際的な動きを理解します。アプローチ設計では、生成AIのハルシネーションについて学びます。
データ・AI利活用における留意事項(心得)の重要キーワード解説
基本理念として、人間の尊厳が尊重される社会、多様な背景を持つ人々が多様な幸せを追求できる社会、持続性ある社会の3つが示されています。

生成AIの留意事項としては、ELSI(エルシー)について考えることが大事です。つまり倫理的、法的、社会的課題の英語訳、ethical,legal and social issuesの頭文字をとったエルシーについて考えます。
数理・データサイエンス・AI(リテラシーレベル)を詳しく学ぶ
webサイトは、数理・データサイエンス・AI教育強化拠点コンソーシアムのホームページが良いです。書籍については、「データサイエンス入門シリーズ(講談社)」がDS検定の試験範囲となる導入、基礎、心得について学ぶことができます。

以下、黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の該当する章『モデルカリキュラム』の復習です。
Society5.0は内閣府による第5期科学技術基本計画のキャッチフレーズです。現実空間と仮想空間を融合します。1.0〜4.0は狩猟社会、農耕社会、工業社会、情報社会です。ビッグデータをAIにより解析し現実空間にフィードバックし新たな価値を生み出す社会をデータ駆動型社会と言います。CPSとはIoTをコアとして現実社会と仮想空間が相互関連し、より高度な社会を実現していく仕組みです。
構造化データは行と列など、何らかの構造が定義されているエクセルやRDBなどのデータです。JSON(JavaScriptオブジェクトに似た構文で、XMLより簡潔に記述でき人間が記述しやすいデータで現在の主流です)やXML(タグで囲まれたフォーマットなので容量が大きくなりますが表現力が豊かです)も構造化データです。ただし文献によっては半構造化データと見做されます。


非構造化データはデータ構造が定義されていないことです。画像、音声、動画、文章などです。情報が抽出しにくいです。
高度情報通信ネットワーク社会推進戦略本部ではオープンデータを、営利非営利問わず二次利用可能なルールが適用され、機械判別ができ、無償で利用できるものとしています。ただしこれは1機関のものです。e-Statは日本政府の各府省が公表するデータが利用可能なサイトで、総務省が管理しています。RESASは産業構造や人口動態などに関するデータを地図上に可視化できるサイトで、内閣官房と経済産業省により運営されます。官公庁以外では、MNIST(オープンデータセット)があり、アメリカ商務省が管理しています。青空文庫というサイトで提供されるテキストデータもオープンデータです。著作権が消滅した文芸作品(夏目漱石、コナンドイル、アインシュタインなどもあります)などを公開しています。

インダストリー4.0(第4次産業革命)はドイツ連邦政府が打ち出したコンセプトです。2025年までに取り組むべきデジタル戦略2025を発表しました。ドイツのスポーツ用品企業アディダスのスピードファクトリーなどが有名例です。
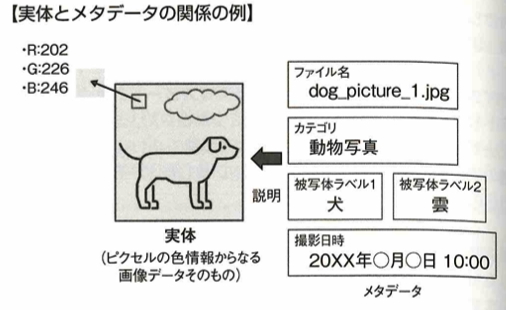
メタデータとはデータを説明する情報です。検索性の向上、さまざまな角度からデータの性質を捉えられる、セキュリティを担保できるメリットがあります。
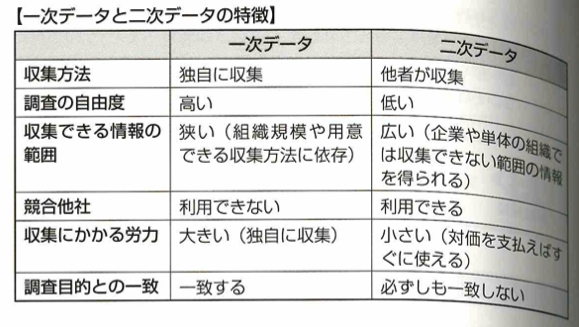
一次データは独自に収集したデータです。アンケート調査やWebクローニングでの収集が必要で手間がかかります。二次データは公開/販売されているような自ら収集したものでないデータです。ただし自分達の調査目的にデータが合致しているとは限りません。e-Statで公開されているのは二次データです。そのためオープンデータは二次データになります。
機械学習の活用領域は以下です。人間が抱える課題を自律的に定義し、その課題を解決するための手段を提示することは困難です。

予測データ分析に期待が寄せられます。またシェアリングエコノミー(ネットを介して個人間でモノや場所、技能などを貸し借りするサービス)、レコメンデーションなどにもAIが用いられます。
ビッグデータによりデータ処理の高速化(GPGPUによる)、IoTによる現実空間の情報の収集、ネット普及によるデータ量の増加があります。パターン認識は1960年頃から発足し今も注目されています。第3次AIブームを後押ししているのはサポートベクターマシンでなく、深層学習です。ロボットは自動作業を行う機械全体を指す用語です。
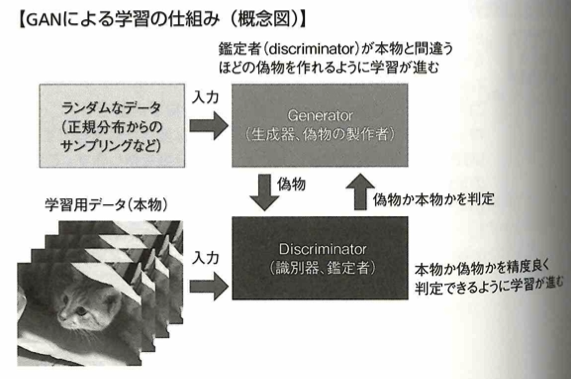
VAEはオートエンコーダというネットワークを確率モデル化し、未知のデータを確率的に生成できます。変分自己符号化器と呼ばれます。GANはDCGANへと発展し、CNN(畳み込みニューラルネットワーク)が採用され、より自然な画像生成に成功しています。
強化学習において行動の主体をエージェントと言います。エージェントの行動によって何らかの影響を受けるものを環境と言います。行動を行うと環境状態が変化します。ある環境状態から別の状態へと変化することを状態の遷移と言います。マルコフ性によって状態が決定することを、マルコフ決定過程(MDP:Markov Decision Process)と言います。エルゴード性は物理学における力学系の運動の長時間平均と位相空間における平均が一致する性質です。移動不変性はCNNにおいて局所領域からフィルタを通して検出する際、物体の位置のズレに頑健になる性質です。
GDPRの17条において、忘れられる権利があります。これは過去の個人についての情報を削除してもらう権利で、個人を救うための権利です。Hugging Faceとは、AIと機械学習のコミュニティやツールを提供する企業およびプラットフォームの名前です。RAG(Retrieval-Augmented Generation)とは、検索拡張生成の略で、大規模言語モデル(LLM)に外部情報を取り入れて回答の精度を高める技術です。
次はデータサイエンティスト検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』の該当する章『データとAIの利活用』の復習です。
Society5.0は超スマート社会です。2つの空間を1つのシステムとみなすことをCPS(サイバーフィジカルシステム)と言います。仮想化技術はSociety5.0の重要技術ではありません。少子化による経済縮小はSociety5.0の社会問題解消ではありません。apple to appleは同一性データ比較です。人間中心のAI社会原則は人間の尊厳+多様性+持続性で世界的に適用されます。E(倫理的)L(法的)SI(社会的課題)です。
DS検定は合格率は高いですが、しっかりと学習しないといけない試験です。僕は3月に受験しますので、『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』と『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』とDS検定の教科書である緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書 第2版』を駆使して、お互いがんばりましょう!



.jpg&description=2025年3月14日にデータサイエンティスト検定(リテラシーレベル)を受験して8割を超えることができました。また4月23日に合格発表があり無事に合格できましたので、ここまでの学習法などをシェアします。){kind=link}