
2026年4月22日にPython3エンジニア認定データ分析試験を受験して925点で合格できました!
Pythonは本記事を書いている段階(2026年4月)で業務で使用したことはございません。そのため未経験でも9割を超える得点を出すことは学習方法を守れば可能である可能性があります!
本記事では公式教材『Pythonによるあたらしいデータ分析の教科書 第3版 (AI & TECHNOLOGY) 』をベースにした得点に直結する分野から学習するインプット→おすすめする模擬試験の学習順序と本試験での時間配分などについて、僕自身の経験からアドバイスできればと思います。
電卓の使用は禁止です。また僕が受験した時は、メモ用紙は配布されませんでした。僕以外の方でもメモ用紙が配布されなかったという報告がありますので、裏を返せば複雑な計算は出ないという認識でいればOKです。
試験時間は60分で択一式の問題で40問中28問正解すれば合格です!
.jpg)
インプット


NumPy、pandas、Matplotlib、scikit-learn(27問)
これらはすべてサードパーティです。
NumPy(ナンパイ)
NumPyは配列や行列を扱うためのPythonのサードパーティ製パッケージです。内部はC言語で実装されています。配列型はndarrayで行列型はmatrixです。ちなみにpandasでは1次元がSeries、2次元がDataFrameです。オブジェクトの型はtype関数、配列要素のデータ型はdtype関数です。また、NumPyは数字の演算では便利ですが通常のPythonのリストの使用とは異なる演算を行いますので要注意です。

"100"は数字っぽいですが文字列です。
[1,2,NaN]はfloat型です。
["1","2",NaN]はobject扱いです。
[1,"2",3]はobject型です。
["1","2","3"]はobject型です。
→pandasの世界ではobjectです。ただし新型ではstringsです。
["",np.nan]はobject型です。
df["col"]でNaNがあるときfloat寄りです。
つまり全部同じ計算ルールで扱えるならばint,float型ですが、扱えない場合はobjectになります。
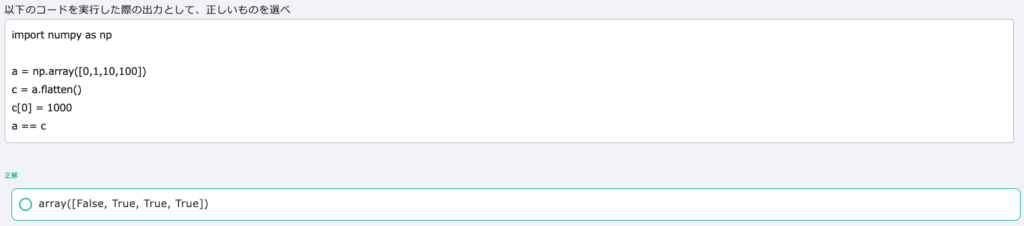
配列の形状はshapeメソッドを使います。配列の形状を変換するのはreshapeメソッドです。多次元配列を1次元に変換するのは参照(浅いコピーつまりデータは複製されない)を返すravelメソッドとコピー(深いコピーつまりデータが複製される)を返すflattenメソッドがあります。通常のリストはコピーを渡しますが、Numpyのでは参照が渡されます。

array関数は数列を表示させます。print関数を使うとarray表記がなくなり要素がスペース区切りで出力されます。astypeメソッドでnp.int16の整数からnp.float16に変換できます。np.linspace()は等間隔の数列を作ります。[0,1,2]に対してnp.diff()を用いると、[1,1]になります。
[7,8,9]にshapeメソッドを適用すると、(3,)です。これは一次元配列という意味です。断じて(3,1)ではありません。
b[0:1, [1,2]]はbの0番目(これは「0行目から1行目の前まで」というスライス指定です)の行、そして列は1列と2列を抽出します。これらを満たす要素を抽出します。b[0]とした場合は行方向の配列(1行目の配列)が取得されます。
numpy.arrange()は指定された開始と終了の1つ手前まで指定された等間隔で数字を出力します。例えばarrange(3)=[0,1,2]です。行において、-1:と書かれたら、上から、-2,-1と考えて、結局最終行だけを取り出します。列において、[1,2]と書かれたら1列と2列を取り出します。Linuxではint64、Windows(Jupyter Notebook)ではint32が出ます。
zeros,onesは出力は0.や1.に注意です。また、np.ones()において、()において(2)とあれば要素2の1次元配列で、(2,2)ならば要素が全て1.0の2行2列行列となります。
ちなみに上のようなfloat型か?の例で、後述するダミー変数関連ではpandas(ダミー変数)ではint型、scikit-learnではfloat型(ワンホットエンコーディング)です。
| 特徴 | pd.get_dummies | OneHotEncoder |
| 主な用途 | データ分析・探索的データ解析 | 機械学習パイプラインへの組み込み |
| 状態の保持 | 行わない(テストデータに同じ変換を適用するのが難しい) | 行う(学習時のカテゴリ情報を保持して変換可能) |
| 出力 | DataFrame | NumPy配列 (または疎行列) |
eye(5)で単位行列I5を作ります。対角成分は1でなくて1.0です。

np.eはネイピア数です。full((1,5),np.e)は1行5列の行列で各成分がeです。full(3,np.e)は(e,e,e)となります。T.で転置をします。linspace(0,1,5は0から1までを等間隔に区切り、5つ並べたものです。hstack関数で関数内を接続します。

答えは3ですがなぜかは以下です。
no.nanは数字ではないのですが文字列はfloat型になります。np.diffは階差を作ります。
concatenateは何も指定しないと横に数が並びます。axis=1は縦方向に連結します。hstackを用いても同様の結果(列方向に連結)が得られます。vstackで行方向に連結させます。hsplitは列方向に分割します。行方向ではvsplitです。np.newaxisは次元を増やすものです。例えば、(3,)型の場合は、[:,np.newaxis]は(3,1)型で[np.newaxis,:]は(1,3)型になります。
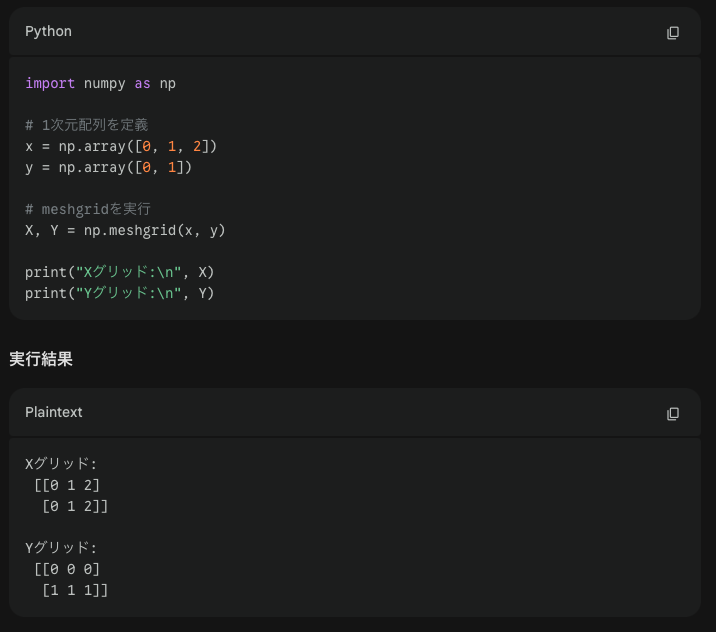
meshgridは行列と列の値に注意です。第1の戻り値xxに第1引数のmを行方向に第2引数nの配列の長さだけコピーされます。第2戻り値yyに第2引数nを列方向に第1引数mの配列の長さだけコピーされます。
例えば以下が具体例です。戻り値はX座標用の行列とY座標用の行列の2つです。

0で割るとinfが出力されます。
A*Bは位置ごとに掛けるだけです。これはアダマール積で、np.maltiply(a,b)とも書けます。しかしブロードキャスト(反対派ユニバーサルファンクション)を考える際は要注意です。np.dot(A,B)は内積のことですが、A*Bが掛けるだけだったことに対して、dot(A,B)=A@B=np.matmul(a,b)は掛けた後に足し算をします。通常の行列の積ですが、ブロードキャストを考える場合は要注意です。(3,2)行列と3要素の配列(行列とみたら駄目です。混乱します。配列と見ましょう!)のドット積は(1,2)型の配列になります。要するに配列になります。逆に@積を考えるとValueErrorとなります。
sum関数を使った場合はint64(2)などとなります。np.allclose(b,c,atol=10.0)はbとcの配列で誤差が10という意味です。
NumPyのスライスは「ビュー(参照)」で、Pythonの標準リストはコピーを返します。
| 特徴 | pd.get_dummies | OneHotEncoder |
| 主な用途 | データ分析・探索的データ解析 | 機械学習パイプラインへの組み込み |
| 状態の保持 | 行わない(テストデータに同じ変換を適用するのが難しい) | 行う(学習時のカテゴリ情報を保持して変換可能) |
| 出力 | DataFrame | NumPy配列 (または疎行列) |
Random Generator(PCG64を使用)はLegacy Generatorより高速です。乱数でサイズ指定がないと、数字のみが出力されます。つまり、(0.0,1.0)行列つまりスカラー(小数値)が出力されます。正規乱数の引数は(平均、標準偏差、出力数)です。配列の形状が(2,10)で各要素の平均2、標準偏差5の正規分布に従う乱数を作成するコマンドは、np.random.normal(2,5,size=(2,10))です。
ちなみにsizeと書いたら選択肢でNGとなるものはPythonの標準リスト(len()です)、後述するpandasではdf.sizeはダメです。例えば行数を知りたいならlen(df)やdf.shape[0]とすると正解です。またread_csvやheadなどの主要メソッドにはsizeという引数はほぼありません。df/head(size=5)はバツでdf.head(5)は正解です。
| プロパティ/関数 | 取得できるもの | 計算式 |
len(df) | 行数 | データの高さ(何件あるか) |
df.shape[0] | 行数 | データの高さ(shapeタプルの0番目) |
df.size | 全要素数 | 行数 × 列数(マスの総数) |
pandas
pandasでは1次元がSeries、2次元がDataFrameです。pandasのDataFrame構造はR言語のデータフレームからインスパイアされたものです。Seriesの場合は[1,2,3,4]という入力に対して、出力は0番目が1,…3番目が4という対応表が出力され(つまりインデックス名、カラム名が共に自動で数字が0から割り当てらています)、dtype(今回はint64)も出力されます。DataFrameの場合は行と列の名前がともに0,1,2,…となります。headメソッドは先頭の5行を出力します。
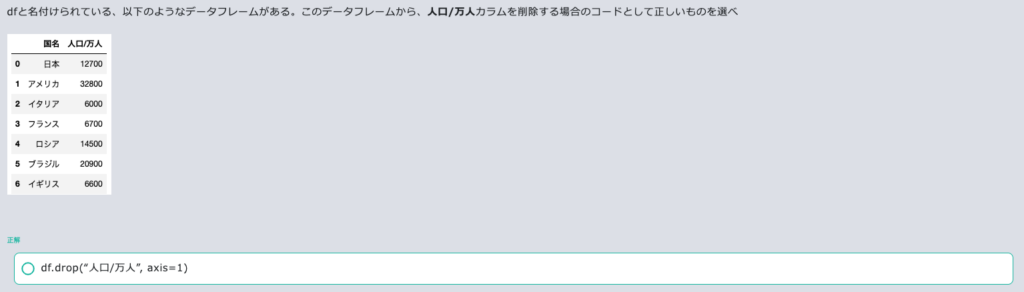
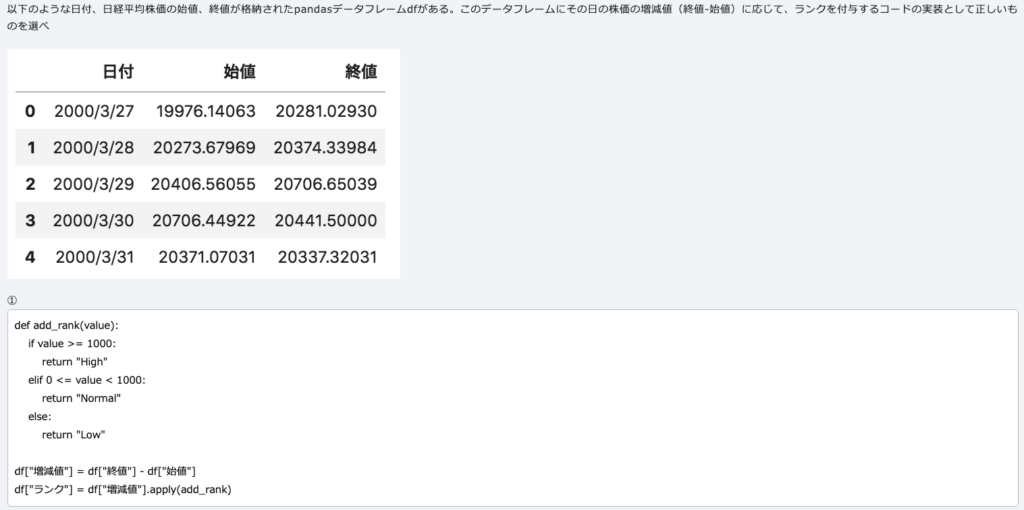
indexは行、columnsは列です。locは名前で指定し、ilocは番号で指定します。抽出はqueryメソッドを使うこともできます。sort_valuesメソッドで並べ替えを行えます。dropメソッドで不要なカラムを削除できます。3行目を取り出すときは、df[df.index==2]とすれば良いです。
CSV、EXCEL、HTMLと読み込み書き込みができます。pd.read_csv()は文字コードの判別はしないので文字コードがUTF-8以外は引数encodingで指定する必要があります。pickleモジュールで、バイナリデータを使えます。直列化したファイルを読み取るとき、df.read_pickle()とdf.to_pickle()を用います。

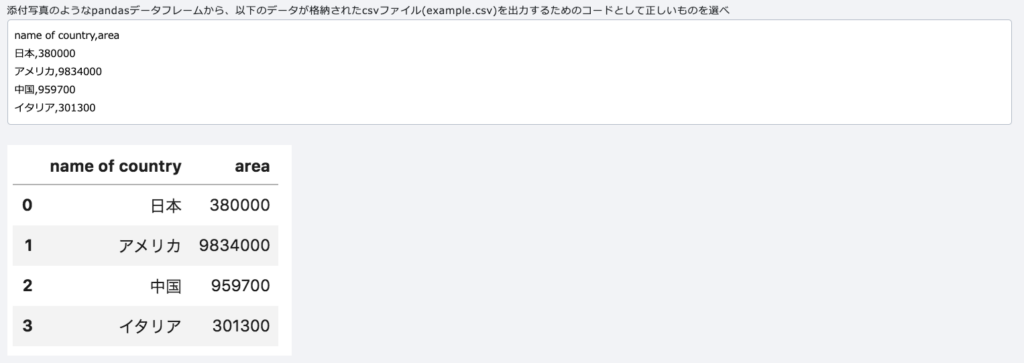
index=False を指定することで、インデックス番号を出力せずにCSVを作成できます。もしTrueなら、0,1,2,…などもデータとして一緒に出てきてしまいます。
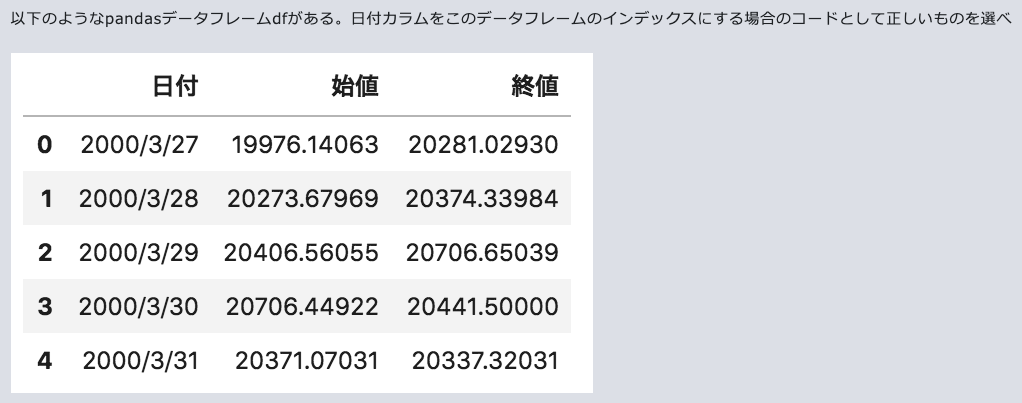
カラムをインデックスに変換するには、set_index()を用います。
random.seed()で指定すると、何回実行しても同じ結果になります。np.random.randint(1,31,365)は365行です。生成する数字は1〜30(31の手前まで)という意味です。Mとはmonthの意味です。pd.date_range()で生成する日付は引数endで指定した終了日自身も含みます。_=df[C]<80などは条件に満たない列はカットするという意味です。もし「月曜日から日曜日」までの週単位の合計を求めたい場合は、freq='W-SUN'(日曜日締め)を使用するのが一般的です。groupbyメソッドでサマライズを行えます。freq=MEで月毎(毎月末)のデータにグルーピングします。そしてmean()で平均値を取ります。resampleメソッドで平均値を出力できます。resample(○)に入れる記号は以下です。
| 記号 | 意味 |
| 'D' | 日次 (Daily) |
| 'W' | 週次 (Weekly) |
| 'M' | 月次 (Monthly) |
| 'H' | 時次 (Hourly) |
| 'min' | 分次 (Minutely) |
欠損値はNaNと表示されるデータが入っていない項目です。削除はdropna、補完はfillnaでメソッドについて、ffillは1つ前方の値で補完、bfillは1つ後方の値で補完で、判定はisnullで欠損値かを判定します。df.meanは平均値で補完、df.medianは中央値で補完します。ただしmodeメソッドでは先頭行も指定します。その際にiloc[0.:]と0から開始することに注意です。"nan"や"<nan>"は文字列として扱われます。
欠損値の対処法ではOne-hotエンコーディングを行ってはいけません。
NumPyやPandasにはquartileという名前のメソッドは存在しないからquartileメソッドは第3四分位数を取得できません。代わりに、一般的にquantile() メソッドを使用します。第3四分位数(75パーセンタイル)を取得したい場合、quantile(0.75) を指定します。

基本統計量をまとめて取得したいときは、describeメソッドを使います。相関係数はdescribeメソッドでなくcorrメソッドで取得します。DataFrameをNumpy配列に変換するときはvalue属性を利用しますが、インデックス名、カラム名は保持されません。axis=0は列方向(縦方向)の連結で、axis=1は行方向(横方向)の連結です。結合の際は[]の記号を忘れずに。
pd.date_range(start=”2020-01-01”, end=”2020-1-31”)と書かれたら2020/1/1~2020/1/31までのデータを見ています。
| 引数 | 動作 | 結合のイメージ |
| axis=0 | 行方向(デフォルト) | 縦に積み上げる(indexが増える) |
| axis=1 | 列方向 | 横に並べる(columnsが増える) |

inner→共通だけ残ります
left→左を全部残します
right→右を全部残します
outer→両方全部(和集合)です
基本情報技術者試験などでも出てくるSQLの知識と同じです。
.jpg)
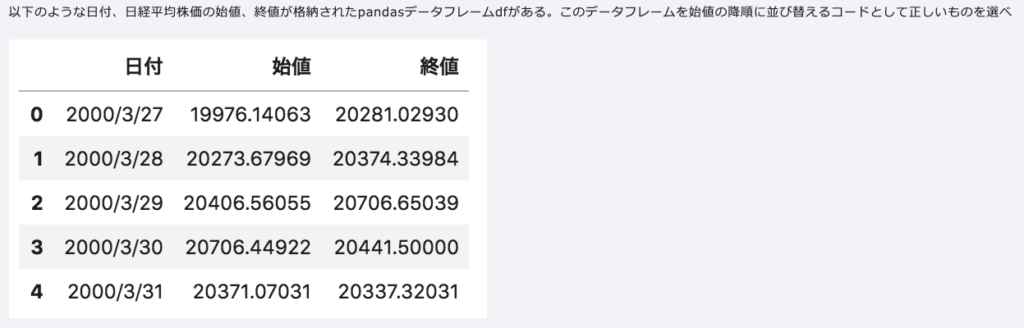
pandasのsort_valuesメソッドを用いています。
read_htmlメソッドを使うと直接DataFrameに取り込めます。table要素が複数ある場合も、すべてのテーブルをリスト形式で取得します。
stdメソッドは不偏分散の正の平方根である標準偏差を出力します。ここで標本分散から出される標準偏差を求めたい場合は、ddof=0を指定します。
values属性を用いるとpandasのDataFrameをNumPyの配列(ndarray)に変換します。
最頻値はdf.loc[:,"部活”].mode()と記述します。
pd.plotting.scatter_matrix()が正しいです。
機械学習モデルが理解しやすいように文字列のデータを数値(0/1)に変換するのが pd.get_dummies の主な役割です。ここでは3行3列行列が作られています。
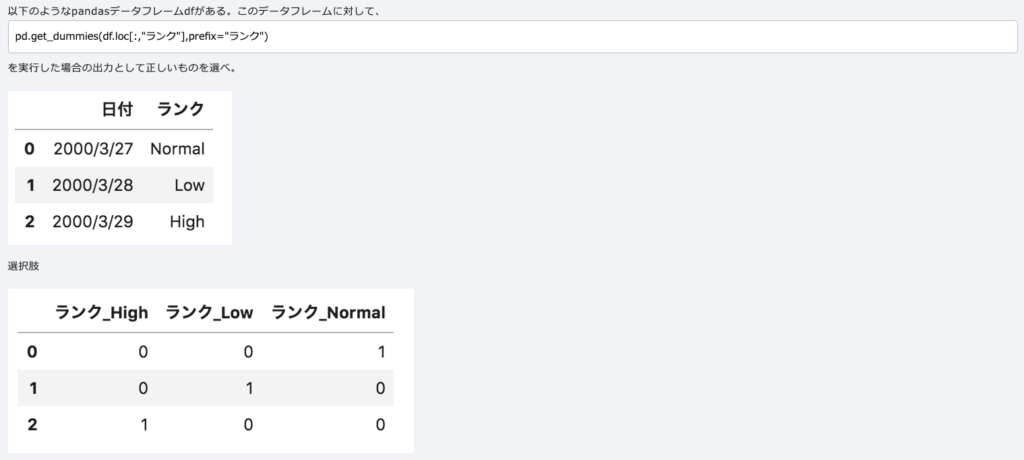
| 特徴 | pd.get_dummies | OneHotEncoder |
| 主な用途 | データ分析・探索的データ解析 | 機械学習パイプラインへの組み込み |
| 状態の保持 | 行わない(テストデータに同じ変換を適用するのが難しい) | 行う(学習時のカテゴリ情報を保持して変換可能) |
| 出力 | DataFrame | NumPy配列 (または疎行列) |
Matplotlib
Mathplotlibは2次元のグラフを書くライブラリです。JupyterLabと相性が良くNotebook上でコードを実行すると結果のグラフが表示されます。コードには、pyplotインタフェースとオブジェクト指向インタフェースがあります。試験ではオブジェクト指向インタフェース(描画オブジェクトに対してサブプロットを追加して、サブプロットに対してグラフを描画します。1つのfigureオブジェクトに対して複数のサブプロットを指定できます)が大事です。
オブジェクト指向インタフェース→plt.subplots()
pyplotインタフェース→オブジェクトを介さず、matplotlib.pyplotモジュールに対して各種関数を実行します。
描画オブジェクトについて、figという描画オブジェクトの中にaxesというサブプロットの変数を入れます。ここでsubplots(2)とすると2つのグラフ(2行1列のサブプロット)ができます。subplots(2,2)とすると、(2,2)型の合計4つの座標平面が生まれます。位置関係は横(nrowsで2行1列)、縦(ncolsで1行2列)です。plt.subplots(6,ncols=2)とすると12個のサブプロットが6行2列で配置されます。
sizeという引数はありません。またplot()メソッドではグラフの枠線の色を指定できません。グラフの周囲を囲む枠(フレーム)の色を直接 plot() の引数で変えることはできません。しかし、「グラフの線(データ)」の色なら自由に変えられます。
あらかじめ用意されている設定を適用する関数は、matplotlib.style.use()です。
ggplot(グラフのスタイルを決定できます)でマス目の装飾が加わります。suptitleで主題、sub_titleで副題です。legendメソッドで凡例(グラフのタイトルでなく線の意味する説明)を表示することについて、ラベルは、label=で名前を指定して、そのあとに位置をlocで指定(10種類)します。位置の指定がlengendメソッドのことです。savefigでグラフの画像などの保存ができます。円グラフはpieメソッドで箱ひげ図はboxplotメソッドです。savefigで出力ができます。
折れ線グラフ
折れ線グラフはplotメソッドです。
棒グラフ
棒グラフのbarメソッドにおいてtick_labelを用いると目盛りに任意のラベルが指定できます。横向きの棒グラフはbarhメソッドです。棒グラフはdf.plot.bar()とすると書けます。ここで、転置Tを入れたdf.T.plot.bar()とすると、X軸にarea、Y軸にBookなどとなります。つまり見たいものが逆転します。
積み上げ棒グラフの難易度は高いです!積み上げ棒グラフではzipを使います。y_1はbarメソッドの引数にはありません。
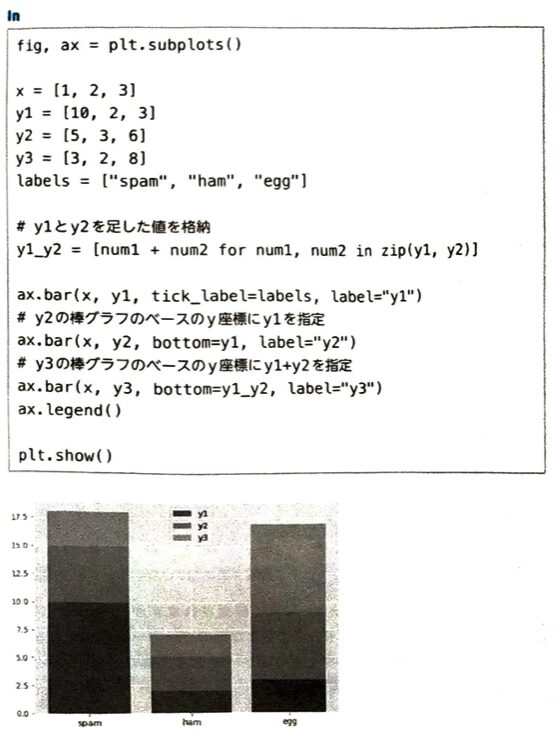
ただしax.hist()に引数stackedでTrueを指定すると積み上げ棒グラフになります。
またax.hist()を2回呼び出すと、2つのヒストグラムが重なって表示されます。横に並べて表示するには、ax.hist((x_0,X_1))のように1回の呼び出しで複数のデータを指定します。
text(x, y, s) の第一、第二引数に指定する座標は、デフォルトではテキストの「左下」の角を基準点(アンカー)として描画されます。線の幅は、plotメソッドの引数で指定できます。フォントの指定は引数がfamilyです。フォントは辞書でも使えます。引数でfontdictがあります。引数でcolorを考えると色を変えることができます。aqua,#000FF,(0.1,0.2,0.5,0.3)など文字列、16進数のRGB指定、0~1の範囲のRGBA指定です。edgecolor引数は枠線の色を指定するためのものです。family引数でフォントの種類が指定できます。フォントのスタイルを辞書で定義できます。このときはfontdict={}と表記し、中括弧内に字体、サイズなどを指定します。textメソッドでtext(0.3,0.6,'TEXT',size=50)だと指定された場所にTEXTという文字を50サイズで書くという意味です。グラフのスタイルは28種類から選べます。
plotメソッドはデータをグラフにプロットするのが役割です。グラフの枠線の色を指定することができるのはfigure()メソッドです。plt.figure(edgecolor="red")と指定すると枠線の色を指定できます。
散布図(scatterメソッド)では、デフォルトではそれぞれのマーカーは丸で描画されますが、marker引数にマーカーの形を指定することにより、様々な形のマーカーを使用することができます。その形の種類は10種類となります。また散布図で指定することができるマーカーの種類は30種以上あります。
ヒストグラムはhistメソッドです。binsとは、階級の数で、print(bins)で階級値+1個のデータが出力されます。patchesには描画に必要な情報が入っています。enumerate関数で番号(i)度数(num)が2次元データとして入ります。2fは小数点以下2桁という意味です。デフォルトの数は10です。orientation=horizontalで横向きのヒストグラムを描画できます。棒グラフと異なり、ヒストグラムは複数の値を指定すると自動的に横に並べて表示してくれます。stacked=Trueとすると積み上げたヒストグラムが表示されます。
箱ひげ図
箱ひげ図はboxplotメソッドで、vert=Falseとすると横向きの箱ひげ図を描画できます。
円グラフ
pieメソッドの引数は、X=[10,3,1]は各要素の大きさの指定です。開始位置はデフォルトでは3時位置ですが、startangle=90とは、90°回転した位置です。この場合は12時位置から開始です。これは正の向きという意味です。counterclockは、円グラフが進む方向がどうか?についての記述です。デフォルト指定では正の向きとなります。autopct引数は、値を%表示させるための設定です。autopct='%1.2f%%'は、書式化演算子で%を使い、最小フィールド幅(最小の桁数)を1にし、精度(小数点以下の桁数)を2fつまり小数第二位まで表示し、書式化演算子をし、%文字を1個表示させる設定になります。ax.axis('equal')でアスペクト比が保持されます。円グラフの一部の値を目立たせるためにexplode引数に値を指定して要素を書き出して表示させることができます。例えば、explode=[0,0.1,0,0]の時、二番目のインデックスを0.1浮かせます。
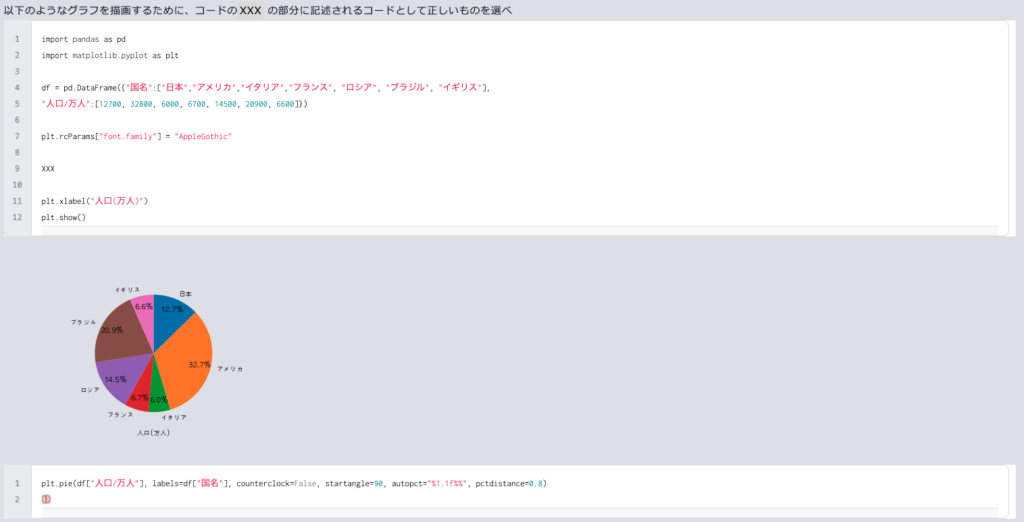
pctdistance=0.8とは、ラベルの位置です。つまりパーセンテージの文字を円の中心から80%の距離(円の内側)に配置しています。
この問題はかなり難しいです。正直何を言っているのか不明でしたので色々と調べました。

近似曲線の描写は最難関です。
角度は弧度法です。
padasのオブジェクトからのグラフ描画も可能です。DataFrameに対して、折れ線グラフはplotメソッド、棒グラフはplot.barメソッドです。
scikit-learn
これは機械学習の前処理です。欠損値の対応、カテゴリ変数のエンコーディング、特徴量の正規化などを行います。fitメソッドで学習→transformメソッドで変換します。fit_transformメソッドで一度に実行できます。
テストデータに対して fit_transform を使ってはいけません! テストデータで fit(学習)をしてしまうと、テストデータの情報がモデルに漏れてしまい、正しい評価ができなくなります(これを「データリーク」と呼びます)。
後に登場するtrain_test_split関数は回帰などで用いるため使用用途が異なります。
fit_transformはメソッドで、train_test_splitは関数です。
scikit-learnはGPUで動かすためのサポートがありません。欠損値の補完はpandasのDataFrameのfillnaメソッドやscikit-learnのimputeモジュールのSimpeImputerクラスを使用します。返り値はNumPy配列です。

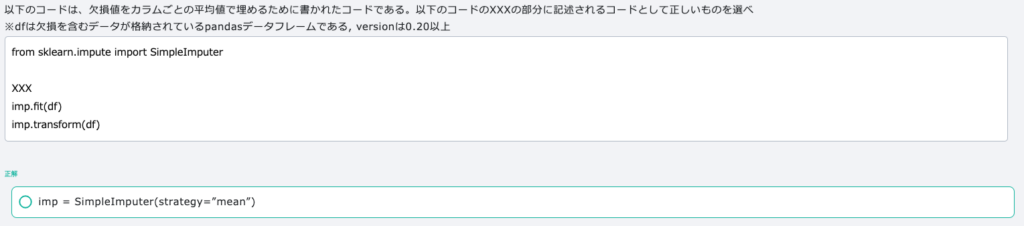
カテゴリ変数を数値に変換する方法は、カテゴリ変数のエンコーディング、One-hotエンコーディングがあります。カテゴリ変数のエンコーディングは、preprocessingモジュールのLabelEncoderクラスを使用します。元の値はle.classes_で確認します。One-hotエンコーディングを行うには、preprocessingモジュールのOneHotEncoderのクラスを用います。pandasの場合は、get_dummies関数を用います。右端に1,2,3,4,5という列が並びます。左側は0と1で構成される疎行列で占められています。疎行列はたくさんの0.0と少しの1.0の行列です。疎行列は0を無視することでメモリなどを削減できます。K種類の値がある場合はK列に展開されます。
| 特徴 | pd.get_dummies | OneHotEncoder |
| 主な用途 | データ分析・探索的データ解析 | 機械学習パイプラインへの組み込み |
| 状態の保持 | 行わない(テストデータに同じ変換を適用するのが難しい) | 行う(学習時のカテゴリ情報を保持して変換可能) |
| 出力 | DataFrame | NumPy配列 (または疎行列) |
特徴量の正規化は、尺度を揃えることで、分散正規化と最小最大正規化があります。分散正規化はpreprocessingモジュールのStandardScalerクラスを用います。fitメソッドで平均や標準偏差を求めてtransformメソッドにDataFrameを指定して分散正規化を行います。結果はNumpy配列です。最小最大正規化は、特徴量の最小値と最大値が0、1を取るように正規化することです。数式では、(x-x_min)/(x_max-x_min)です。

| やりたいこと | Pandas (データ整形) | scikit-learn (機械学習用変換) |
| 欠損値の穴埋め | df.fillna() | SimpleImputer |
| カテゴリ変数の変換 | pd.get_dummies() | OneHotEncoder |
| 数値の正規化 | 数式を書いて計算 (例: (x-mean)/std) | StandardScaler, MinMaxScaler |
回帰モデルを定量的に評価する指標は平均二乗誤差(MSE)、平均絶対誤差(MAE)、決定係数などがあります。F値は分類モデルを評価する指標です。
分類は既知のデータを教師として利用します。分類はクラスを予測します。分類モデル構築の流れは、データセットの分割→学習→予測→モデルの評価です。fitメソッドは学習、predictメソッドは予測です。学習データとテストデータに分けるためにModel_selectionモジュールのtrain_test_split関数を使用します。1番目の引数は説明変数(特徴量)、2番目の引数は目的変数を指定します。test_size=0.3ならばテストデータ:学習データ=3:7です。
サポートベクターマシンでデータを高次元に写して考えますが、実際は高次元の空間に写すのではなくデータ間の近さを定量化するカーネル(高次元空間のデータ間の内積を計算する関数に相当します。例えば動径基底関数rbfにより非線形な決定境界を使った分類も可能です)を導入します。Cの値が小さいとマージンは広く、大きいほどマージンが狭いです。le6=10^6のことです。回帰や外れ値検出にも使えるアルゴリズムです。
サポートベクターマシン関連のプログラムは本書で最難関の1つです。
決定木でエッジとは枝のことです。情報利得=親ノードの不純度ー子ノードの不純度です。不純度=どれだけクラスが混在しているかの指標です。ジニ不純度、エントロピー、分類誤差がありますが、scikit_learnではジニ不純度が一般的です。これは各ノードに間違ったクラスが振り分けられてしまう確率です。
例えばあるノードにクラス0が割り振られる確率が0.6で、クラス1が振り分けられる確率が0.4とします。このときジニ不純度=0.6・0.4+0.4・0.6=1-(0.6^2+0.4^2)です。クラスがC個のときも一般化可能です。
情報利得(決定木の不純度の指標にはなりません)が正ならば木を分割した方が良いことがわかります。情報利得の大きい順に特徴量が使用され、木が作られます。treeモジュールのDecisionTreeClassifierクラスを使用します。export_graphviz関数を用いてdot形式のデータを出力します。estimator=決定木のことです。ランダムフォレストはアンサンブル学習の1つです。ensembleモジュールのRandomForestClassifierクラスを使用します。train_test_split(X,y,test_size=0.3,random_state=123)とは説明変数X、目的変数y、テストデータの割合、コードの再現性確保を順に行っています。cvは交差検証の分割数です。X(説明変数)が先、y(目的変数)が後です。ランダムフォレストは、他の機械学習のアルゴリズムと比較すると、欠損値の穴埋めや標準化などのデータの前処理を必要としないアルゴリズムです。
GridSearchCVはハイパーパラメータ(決定木の深さ)の最適化です。ハイパーパラメータは木の深さ、ランダムフォレストに含まれる決定木の個数などです。探索するほど精度が良くなることはありません。また、欠損値を補完する方法やデータセットの分割比率はハイパーパラメータではありません。また。最適化が直接モデルの学習時間の短縮や計算コストの削減にはつながりません。グリッドサーチとランダムサーチがありますが、グリッドサーチはハイパーパラメータの候補を指定してそれぞれのハイパーパラメータで学習を行い、テストデータセットに対する予測が最も良い値を選択する方法です。木の深さはbest_params_で確認できます。最適なモデルはbest_estimator_で確認できます。
次元削減は特徴量を抽出することを目的とする教師なし学習です。主成分分析は、高次元データに対して分散が大きくなる方向を探して、元の次元と同じかそれより低い次元にデータを変換する手法です。decompositionモジュールのPCAクラスを使用します。「スクリプトBでは、もとのデータを新たな1次元のデータに変換し、次元削減している」という記述は、n_components=2 となっているため、誤りです。pca.fit_transform(df)を使用します。
モデルの評価はカテゴリの分類精度、予測確率の正確さで説明されます。適合率(Aと予測して実際にAだったものの割合)や再現率やF値や正解率は分類モデルの評価指標です。以下の内容の出力にはscikit-learnのmetricsモジュールのclassification_report関数が便利です。


適合率は陽性だと予測した結果にノイズがないことを重視します。再現率は真に陽性であるケースを見逃さないことを重視します。
| 指標 | 注目する対象 | 何を見るか |
| 感度 (Sensitivity / Recall) | 陽性のデータ | 「取りこぼしがないか?」(FNを減らしたい) |
| 特異度 (Specificity) | 陰性のデータ | 「誤報がないか?」(FPを減らしたい) |
データを10分割した場合、9つの集合を学習データセットに残りの1つの集合をテストデータセットに使用する処理を10回繰り返します。この処理を10分割交差検証を言います。ただし予測ラベルの割合が不均一になる問題があります。それは層化k分割交差検証法で対処できます。
均一k分割交差検証法は通常の交差検証法の意味です。
| 特徴 | 均一k分割交差検証 | 層化k分割交差検証 |
|---|---|---|
| 分割方法 | ランダム分割 | クラス比率を維持 |
| クラス分布 | フォールド間で偏る可能性あり | すべてのフォールドで均一 |
| 適したデータ | 均衡データ (Balanced) | 不均衡データ (Imbalanced) |
| 信頼性 | 偏ったデータでは低い | 高い |
model_selectionモジュールのcross_val_score関数を使用します。ROC曲線からAUCを算出します。ROC曲線は、横軸と縦軸にそれぞれ偽陽性率、真陽性率を考えて考えます。
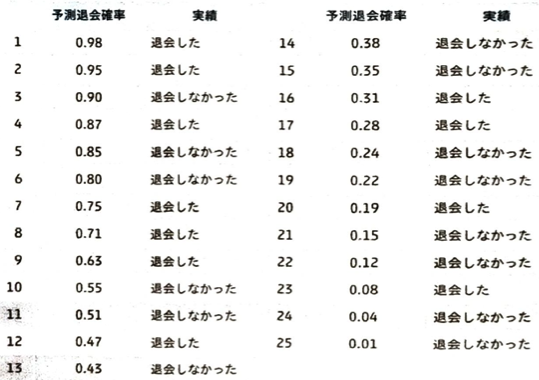
各ユーザに対して予測退会確率(退会を陽性と考えます)を高い順に並べて、1人目から25人目までその時点でのROC曲線の点をプロットします。例えば1人目では偽陽性率は0/14で真陽性率は1/11です。この11人とは25人目のデータを見た際に、合計で11名が退会したことから導き出しています。2人目時点では累計で偽陽性率、真陽性率はそれぞれ、0/14,2/11です。これを25人目まで繰り返します。出力の際は分子の数字の列をNumpy配列に変換して考えています。
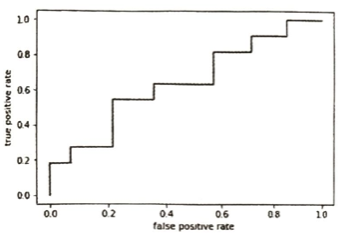
上の図ではAUCの値はこの折れ線とx軸とで囲まれる図形の面積で算出します。1に近いほど確率が相対的に高いサンプルが正例、相対的に低いサンプルが負例になる傾向が高まります。つまり左上に膨らむほど良い性能です。つまりこの時にクラスを分類する能力が優れていると判断できます。0.5に近いほどランダムにデータが混じっていることに対応します。ROC曲線のプロットする点は、metricsモジュールのroc_curve関数により計算できます。AUCはmetricsモジュールのroc_auc_score関数を用いて計算できます。引数には、クラスラベル、確率をそれぞれ指定します。
分割型の階層型クラスタリング(データ数が多いと表示が困難のため、一部だけ取り出して可視化するなどの工夫が必要です。)は順次クラスタを分割していきます。凝集型(clusterモジュールのAgglomerativeClusteringクラスを使用します。)と比べて計算量が多いです。デンドログラムはSciPyライブラリのcluster.hierarchy.dendrogram関数でプロットできます。また、scikit-learnのAgglomerativeClusteringクラスでは引数n_clustersを使ってクラスタ数を指定可能です。
デンドログラム関連の話題もこの試験での最難関の1つです。
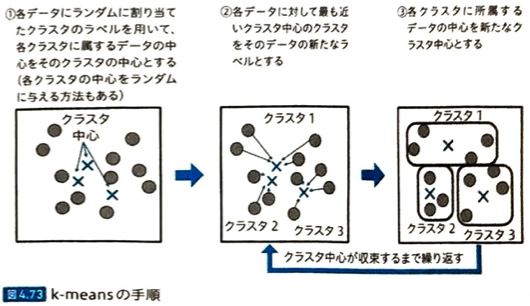
k-meansでは異なるクラスラベルで件数が完全に同じになるように分割されるわけではありません。またクラスタリングとして適当でないものはk-近傍法(k分割交差検証法のこと)です。


数学・統計分野(6問)
確率関数のことを確率質量関数とも言います。PythonではSciPyやSymPyを使うと積分計算ができます。教師あり学習も教師学習の方も説明変数(特徴量)があります。回帰は連続値です。DBSCAN法はクラスタリングアルゴリズム(密度準拠)で特徴量ベクトル間の距離に着目した方法です。シグモイド関数は(0,0.5)を基点とします。関数はf(x)=1/(1+e^(-x))です。ニューラルネットワークの活性化関数として使われる関数であり、この関数の出力は0より大きく1より小さいです。tanhはニューラルネットワークで利用されます。スタージェスの公式はデータ数をNとするとき、階級数を1+log2(N)とします、IQR(四分位範囲)の1.5倍を考え、第1四分位数より下、もしくは第3四分位数より上にIQR(四分位範囲)の1.5倍以上離れているデータを外れ値として扱う流儀もあります。スピアマンの順位相関係数は、1-(6Σ(d_i)^2)/(n(n^2-1))です。情報量(ビット)=-log2(p)です。ブートストラップデータとは、ランダムに復元抽出されたサンプルと特徴量のデータのことです。
勾配ブースティングは複数の弱い学習器を逐次的に学習させそれらを組み合わせて強い学習器を生成する方法です。ニューラルネットワークとは異なるタイプの機械学習アルゴリズムです。LightGBMはMicrosoftによって開発された勾配ブースティングフレームワークです。XGBoost(特定の企業が「自社製品」として開発したものではなく、研究者である陳天奇(Tianqi Chen)氏を中心としたオープンソース・コミュニティによって開発されました。)も同じく勾配ブースティングを備えています。CatBoostはYandexによって開発された勾配ブースティングライブラリです。カテゴリカルデータに強いです。
Pythonの基礎(3問)
Pythonは動的スクリプト言語です。Webアプリなどのフロントエンドや速度向上などの低レイヤー処理などには適さないです。得意なのはサーバー系ツール、Webシステムの構築、IOTデバイスの操作、3Dグラフィックスです。
RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられます。
PEP8は複数のモジュールをインポートするときは1行ずつインポートして書くべきと書かれています。PEP8に違反しているかは、import sys, os を実行します。このようにチェックするツールとしてpycondestyleがあります。flake8はPEP8違反のチェックの他、論理的なチェックも可能です。PEP8の違反チェックはできるが論理的なチェックができないのはpycodestyleです。flake8と同様の機能を言語Rustで実装し直したRuffというツールもあります。ruff check--fix とすると可能な場合には自動でコードを修正してくれます。
対話モードでのプロンプトは>>> , … です。対話モード終了はquitです。メソッドは()で関数は(〇)タイプです。
| 特徴 | 関数 (Function) | メソッド (Method) |
| 所属先 | 独立している | オブジェクト(クラス)に所属 |
| 呼び出し方 | func(x) | obj.method(x) |
| 特徴 | 汎用的な処理を行う | そのオブジェクト専用の処理を行う |
| 直前のドット | ない | ある |
例外処理はexceptです。例えばIPythonでの対話モードでは他にも次のような機能もあります。%はマジックコマンドで!はシェルコマンドです。
リスト表記は[]でセット表記と辞書表記は{}です。ジェネレータ式は()です。大量のデータを処理する場合に一度に大量のメモリを確保しないため負荷を軽減できます。next(g)で順番通りに取り出します。ジェネレータ式は、式 for 要素 in インテラブルです。例えばnamesはインテラブルです。
| 特徴 | リスト (List) | タプル (Tuple) |
| 記法 | [] (角括弧) | () (丸括弧) |
| 変更の可否 | ミュータブル(変更可能) | イミュータブル(変更不可) |
| 用途 | データの追加・削除を行うもの | 変更されたくない固定データ |
| 処理速度 | 比較的遅い | 比較的速い |
| 辞書のキー | 不可 | 可能(ここが重要!) |
| コード | 作成されるデータ型 | 備考 |
a = {} | dict (辞書) | 空の辞書 |
b = {'key': 'val'} | dict (辞書) | 要素ありの辞書 |
c = {1, 2, 3} | set (セット) | 要素ありのセット |
d = set() | set (セット) | 空のセット(重要!) |
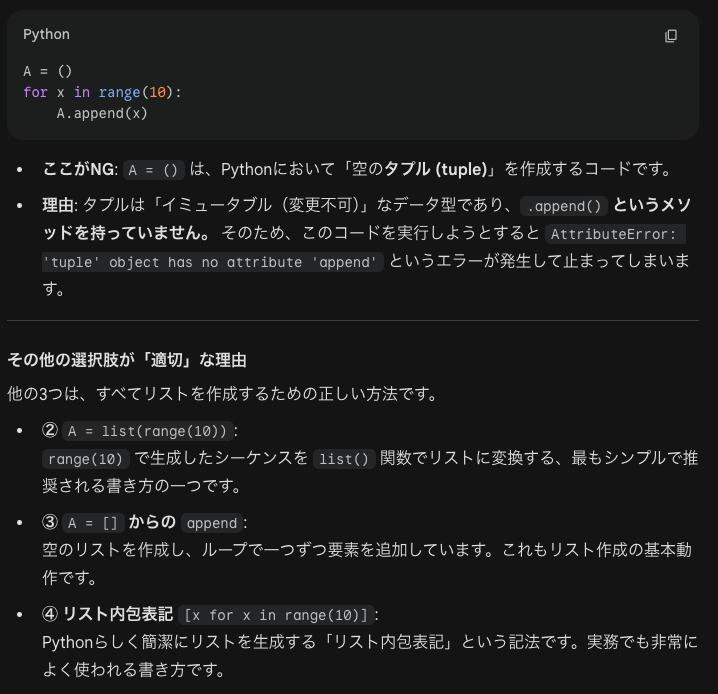
次に盲点問題を1つ見ておきましょう。
| 対象データ | len() が返すもの | 例 |
| リスト / タプル | 要素の数 | len([1, 2, 3]) → 3 |
| 文字列 | 文字数 | len("Python") → 6 |
| 辞書 (dict) | キーと値のペアの数 | len({"a": 1, "b": 2}) → 2 |
| Pandas DataFrame | 行数 | len(df) → DataFrameのデータの行数 |

ファイル出力はopen関数を用いますがファイルの閉じ忘れを防止するためwith文を使うことをお勧めします。f.closedにて、閉じられていたらTrueが返ってきます。f.read()をすると中身を読めます。
title()にするとHello Worldのように先頭が大文字になります。split(a b c)=["a","b","c"]と文字列を空白文字で分割します。strip( a b c )="a b c"と左右の空白文字を削除します。s=stu.jpgなどとしたときに、s.endswith("a","b","c")はa,b,cの末尾がjpgとなっているかチェックします。1つでもOKならTrueです。s.removeprefix(stu.jpg)='.jpg'です。s.removeprefix(test)='stu.jpg'です。stus.removesuffix(".jpg")='stu'です。s.removesuffix(test)='stu.jpg'です。”1234".indigit()=Trueです。これは文字列が数値の文字列かをチェックするためのものです。"-".join(["a","b","c"])='a-b-c'です。
f-stringにおいて末尾に=をつけると式と値をつなげた形になります。たとえば"name='takanory'はlang='python'が好きです"となります。通常はf"{name}は{lang}が好きです。や、f"{name.title()}は{lang.upper()}が好きです。などと書かれます。
正規表現のreモジュールについて考えます。IGNORECSEは大文字小文字を区別しないと言う意味です。g?ときたら、gが0個か1個です。(saya|ro)?ときたら、sayaかroが0個か1個が入ります。注意点として正規表現でABCみたいな場合で、DABCという文字列が正規表現にヒットするか?と聞かれたら、Dを抜かしてABCがヒットしているかを判断すれば良いです。反対にABCDとなっている場合、ABCがヒットしていれば全体としてもヒットしているとみなされます。

loggingモジュールはバッチ処理などの途中経過の出力をします。エラーのレベルはWARNINGをデフォルトとして、DEBUG,INFO,WARNING,ERROR,CRITICALです。デフォルトではWARNINGレベル以上を出力します。重要度は10~50まで10段階であります。
datetimeモジュール(from datetime import datetime, dateです)のisoformat()は日時をISO8601形式の文字列に変換するメソッドです。任意の書式に変換するにはstrftime()を使うか、f-stringsを使います。反対に文字列を日時に変換するのはstrptime()です。timedeltaは日時の差を考えるものです。Pathクラスを使ってパスを作るには/演算子を使います。
pickleモジュールはデータを再利用するために凍結(直列化やシリアライズ)・変換+保存を一度に行う仕組みです。オブジェクトをpklファイルとして保存するために使用するモジュールで、構築した予測モデルを保存する場合などに使用されます。バッファに溜めてからは行いません。pickle.dumps(d)=直列化した情報を確認します。p.exist()で存在するか確認します。read_pickle関数を使ってpickle形式に直列化されたデータを読み込むことができます。
JupyterLab(1問)読み方はジュパイターラブ
Jupyter Notebookはオープンソースで開発されているデータ分析、可視化、機械学習などに広く利用されているWebアプリケーションです。テキストエディターのVisual Studio CodeでもNotebookの編集が可能です。Jupyter Notebook(ipython)はファイルを保存するとその拡張子は.ipynbとなります。Notebookのファイル本体はJSON形式で記述されますが他の形式でのダウンロードも可能です。プログラム・実行結果・ドキュメントを1つのファイルにまとめることができます。Tabによる補完機能も拡張機能なしで使えます。
%は1行、%%はセル全体のプログラムの実行時間を複数回試行して計測を行うコマンドです。これら%や%%から始まるコマンドをマジックコマンドと言います。%timeitはセルに書かれた一行のプログラムに対して実行時間を、複数回施行して計測するコマンドです。%%timeitは1つのセルに対して実行時間を、複数回施行して計測するコマンドです。%lsmagicはマジックコマンドの一覧を表示するコマンドです。%matplotlib tk はコードセル直下にグラフを出力するためのコマンドではありません。
シェルコマンド(!から始まるコマンド)で(!pip list)はOSコマンドを指定して実行できます。アプリケーション⊃シェル⊃カーネル⊃ハードウェアとすると、OSはシェルから考えます。Notebookの形式はJSON形式です。リポジトリはGitHubです。デフォルトでは8888番ポートです。一番上のセルはMarkdown形式のセルです。JupyterLabを終了する際は、FileメニューからShut Downを選択します。
データ分析エンジニアの役割(2問)
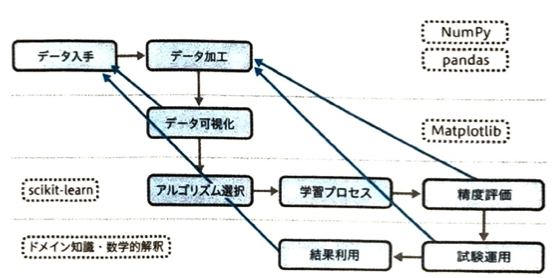
データサイエンティストは数学、情報工学、対象分野が必要です。データ分析エンジニアは、データハンドリング、データの可視化、プログラミング、インフラレレイヤーが必須です。付加的に必要なのは機械学習、数学、対象分野の専門知識です。データハンドリングは機械学習モデルの学習プロセスは含まれません。
Javaはデータ分析に関するライブラリが少ないです。Excelの利点はGUIの操作が可能な点です。
実行環境構築(1問)
Python公式版をインストールしvenuによる仮想環境の作成とpipコマンドでのパッケージ管理を行います。Windowsは32-bit,64-bit版があります。macOSは64bitです。venu(vエンブと呼びます)はPythonをインストールすると標準で使用できます。Pythonでは1つの環境には1つのバージョンしかインストールできません。
プロジェクトごとに仮想環境を作成すれば、それぞれのプロジェクトで必要となるパッケージをバージョン指定してインストールできます。
WindowsではSet-Excutionpolicyコマンドを実行します。仮想環境を抜ける場合は、deactivateコマンドを実行します。macOSの場合はvenuを指定して仮想環境を作成します。仮想環境を抜ける方法はdeactivateコマンドを実行します。
pipについて、installについては、Uは更新を意味します。uninstallについては、yは確認スキップを意味します。pipコマンドはPythonパッケージのインストールなどを行うユーティリティで、パッケージをインストールするにはpip installコマンドを使用します。listについては、oはoutdatedつまり最新版でないパッケージのみです。freezeはrはrequirementつまり用件と言う意味です。これはpip listと同じくインストールされているパッケージの一覧を表示します。出力情報をファイルに保存して共有でき複数の環境でパッケージのバージョンを統一できます。
Anacondaはvenuやpipとは異なります。
Anaconda環境でpipも使用できますが、稀にcondaコマンドで構築された環境が壊されてしまう可能性があります。そのためAnacondaを利用する場合は基本的にcondaコマンドでパッケージを管理することをおすすめします。
venuではPython自体の管理はできません。venuは1つの仮想環境内に同じパッケージの複数バージョンをインストールすることはできません。
模擬試験などを用いた学習順序
模擬試験を行ってきて公式っぽいことを発見しました!それは迷ったら選択肢の記述がシンプルなものが正解ということです。
指定教材『Pythonによるあたらしいデータ分析の教科書 第3版 (AI & TECHNOLOGY) 』を1度流し読みをしてPRIME STUDY模試は第1回に挑んで23/40でした。あと4問で合格ラインでしたので悪くない結果でした。第1回の解説動画を見て復習した後に第2回の模試を解いたら30/40でした。また第3回の模試も30/40でしたが模範解答が一部間違いがあるようなので31/40となりました。
この後にもう一度、指定教材『Pythonによるあたらしいデータ分析の教科書 第3版 (AI & TECHNOLOGY) 』を読み直しました。つまりこの時点で2周目を行っています。ただし第2章は僕にとってはまだ複雑に感じる内容であり、出題数も4問しかないので、第2章はまだ2周目を行いません。次の模試を行って少し知識が定着してきたと感じた時に、第2章も2周目を行います。
PyQの模試を受験しました。結果は24/40で合格ラインまで4問足りませんでした。難易度的に細かいところを突かれる出題でした。僕が経験した模擬試験の中では最も難しく感じました。
1日後にディープロの模試(1回目)を受けました。結果は26/40であと1問正解できれば合格ラインでした。この問題も今までの模試では出題されていない問題が出ていました。ディープロ模試はストックされている問題から40問ランダムに出題されるので何回か模試をこなして未知問題を無くそうと思いました。第2回のディープロ模試で33/40でした。合格者の情報によるとこのディープロ模試は問題の質が良いそうです。
試験前日の日に2周目で後回しにしていた第2章のところも2周目を終えました。ディープロの第3回模試は30/40でした。第4回目の結果は29/40でした。また試験日の試験直前まで、この記事の内容や公式教材『Pythonによるあたらしいデータ分析の教科書 第3版 (AI & TECHNOLOGY) 』を見直しました。
模擬試験の難易度はディープロ模試<PRIME STUDY模試<PyQ模試だと感じました。
試験結果

925点つまり3問間違えてしまいましたが合格することができました!
どれくらいで解き終わりましたか?
17分です。残りの時間を全て見直しに使いました。
PRIME STUDYさんが公開されている動画が学習の序盤と終盤に役立ちました。ありがとうございました。また公式教材の書籍の内容でエッセンス部分をしっかりと理解すればOKだと確信しました!
| CDA模試と本番の得点 | 正解数 |
| PRIME STUDY 第1回 | 23 |
| PRIME STUDY 第2回 | 30 |
| PRIME STUDY 第3回 | 31 |
| PyQ模試 | 24 |
| ディープロ模試 第1回 | 26 |
| ディープロ模試 第2回 | 33 |
| ディープロ模試 第3回 | 30 |
| ディープロ模試 第4回 | 29 |
| 本試験 | 37 |
このように、模擬試験の方が難しく感じました。裏を返せば模擬試験の内容をしっかりと消化できていれば9割程度を取れる試験だと感じました。本試験は解いていて学びになる良い問題が多いなと感じました。次回はPython3エンジニア認定データ分析実践試験を受けようと思います!

{kind=link}