
2026年5月2日にデータサイエンス発展を受験して合格しました。本記事では下記の指定教材を用いて、どのように学習すれば合格を目指せるのか?を軸に記事を書きたいと思います。また、実際に受験してみて意外な検定が絡んでくることにも追記します。
ちなみに学習期間はPython3エンジニア認定データ分析試験に合格した日(2026年4月22日)から開始したので10日で合格できたことになります。
10日と聞くと短いと思うかも知れませんが、下記に紹介する公式教材でしっかり学習すれば十分に可能です!
DS発展は論理・AI、数理、情報、統計・可視化の4つの領域から出題されます。単独の4分野に加えて、数理と情報、数理と統計・可視化、情報と統計・可視化の3つの融合分野を合わせた合計7問の大問の構成で各大問から4問出題されるため、合計28問の問題を60分間で解いて6割以上つまり17問以上の正解で合格です。指定教材『データサイエンス発展演習』によると前書きの説明の内容から統計検定2級と統計検定準1級の間の難易度となります。
指定教材によると、まずはこの教材の1分野単独問題の例題の第6章→2分野複合問題の例題の第7章をはじめてからインプット内容である第2章〜第5章を学習することを勧めています。最後に第8章の模擬試験を行い完成となります。また付録にてPythonのライブラリについての説明もあり、試験内容的に読んでおくことは必須要件だと思われます。このライブラリはPython3エンジニア認定データ分析試験と範囲が被っていますので、余力のある方はこのデータ分析試験の受験もお勧めします。
本書にてコラムで扱う問題は成績上位を狙う受験生を想定したものですので、試験範囲に含まれます。



論理・AIに関する基礎的な事項
.jpg)
3VとはVolume、Velocity、Varietyです。それに加えてVeracity(正確性)とValueを加えて、4Vや5Vということもあります。ICTによる変化を第4次産業革命といい、サイバー空間とフィジカル空間との融合をSociety5.0といいます。AI時代に対応できる公共政策や法案を提案できる人材が必要です。EBPMはBig Data/AIを用いた政策立案です。例えばサイバーエージェントでは広告のキャッチコピーにChatGPTを用いてます。
ムーアの法則とは半導体の集積密度が2年で2倍になることです。
第1次AIブームはトイ・プロブレム、第2次AIブームはエキスパートシステム、第3次AIブームは機械学習です。RNNは時系列データや順序が重視されるケースのデータの処理に適したニューラルネットワークで自然言語処理や音声認識に広く活用されています。画像の生成AIには拡散モデルに基づくモデルの性能が高いです。
アノテーションは取得したままの状態のデータに追加情報やラベルを付けることです。総務省の情報通信白書によると、ビッグデータは生成する主体(政府・企業・個人)に着目すると、オープンデータ、産業データ、パーソナルデータに分類できます。
人間は直感的な速い思考と熟考する遅い思考を使い分けて思考します。
データを基点とした考え方により社会実態に即した意思決定ができるようになります。これをデータ駆動型社会といいます。
1次データは競合が高いです。2次データは競合が低いですが範囲が膨大です。
最適化の連続や離散の判断は、関数が微分できるか否かで考えます。
販売分野でのダイナミックプライシングとは、需要や供給の変動に応じて価格をリアルタイムで調整する手法です、決定木ベースのアルゴリズムなどを用います。最適価格の決定(価格感度分析)ではコンジョイント分析やPSM(PSM分析(Price Sensitivity Meter)は、4つの価格(高い、安い、高すぎて買えない、安すぎて品質不安)に関するアンケート調査から、消費者心理に基づく適正価格帯を導き出す手法です。)などが用いられます。発見において、バスケット分析とは、同時あるいは順次に購入される商品の組やサービスの組を見つけることです。強調フィルタリングは顧客〜商品の対のデータからレコメンデーションすることです。企業は個人のデータをほとんど使用せずにマーケティングを行うことが可能になったのではなく、企業は適切な同意を得た上で、プライバシーを尊重しつつ個人データを活用しています。
予測=教師あり学習です。データサイエンスの予測における目的変数yは将来の値である必要はなく、欠けている値でも良いです。
データの同化とは、シミュレーションデータと実際のデータの融合のことです。
日本の将来人口の予測では、高位推計、中位推計、低位推計が発表されています。
地図上のデータはベクタデータ(地点、線、多角形として表現され正確な位置情報と共に属性情報を保つことができます)とラスタデータ(地表を等間隔のピクセルで表現し各ピクセルに特定の値を割り当て情報を表現します)があります。ベクタデータ(JSON系で保存)はプログラム言語が必要であったり実行に時間がかかります。ラスタデータはメッシュ統計(csv保存)などに利用されます。

| 特徴 | ラスタデータ (Raster) | ベクタデータ (Vector) |
| 表現方法 | 格子状のグリッド(画素/ピクセル) | 座標(点・線・面)による幾何学的な表現 |
| 最小単位 | 画素(ピクセル) | 点(ノード/頂点) |
| 拡大 | 拡大するとぼやける(ジャギーが出る) | 拡大しても劣化しない(数式で描画) |
| 適したデータ | 連続的な変化(写真、衛星画像、温度分布) | 個別の事象(道路、境界線、POIの地点) |
| データ容量 | 解像度が高いと非常に大きくなる | 比較的軽量(座標情報のみのため) |
POI(Point of Interest)は、地図や地理情報システム(GIS)において、レストラン、観光スポット、駅、避難所など、ユーザーが関心を持つ「特定の場所・地点」を指します。

データサイエンスのサイクルにはPPDACサイクルがあります。Problem→Plan→Data→Analysis→Conclusionの順で行います。
Airbnbとは民泊のことです。
ELSI(Ethical,Legal,and Social Issues)は倫理的・法的・社会的な課題です。GDPRは2018年5月25日に施行されました。17条が忘れられる権利です。インフォームドコンセントは個人が自分の個人情報の使用に関して十分な情報を持っていて、その使用に同意することです。
手続きはオプトイン設計です。
知的財産権=著作権、特許権、商標権、意匠権です。
技術の提供者はAccountabilityとTrust(過去の類似性を示して妥当性や公平性を納得してもらうこと)を行うべきです。
データサイエンスや製品開発においては、「アルゴリズムは特許(または秘密管理)」「プログラムは著作権」「マニュアルは著作権(および商標)」と、守るべき対象に応じて戦略を使い分けることが非常に重要です。
| 対象物 | 著作権(表現を保護) | 特許権(発明を保護) | 備考・補足 |
| 生データ (Raw Data) | 基本的に× | × | 事実は誰のものでもないため保護されない。 |
| データベース | ○(選択・構成に創作性がある場合) | × | データの並べ方や分類に工夫があれば保護される。 |
| アルゴリズム(考え方) | × | ×(アイデアのみでは対象外) | 手順そのものは保護されない。 |
| ソースコード | ○(プログラムの著作物) | ○(技術的発明であれば可) | プログラムとしての表現と、技術的発明の両面を持つ。 |
| 取り扱い説明書(文書) | ○(文学的著作物) | ×(文書自体は発明ではない) | 文章や図版は「著作物」として強く保護される。 |
人間中心のAI社会原則は、3つの基本理念(人間の尊厳が尊重される社会、多様な背景を持つ人々が多様な幸せを追求できる社会、持続性のある社会)です。

また7つの基本原則(人間中心の原則、教育・リテラシーの原則、プライバシー保護の原則、セキュリティ確保の原則、公正競争確保の原則、公平性、説明責任及び透明性の原則、イノベーションの原則)があります。

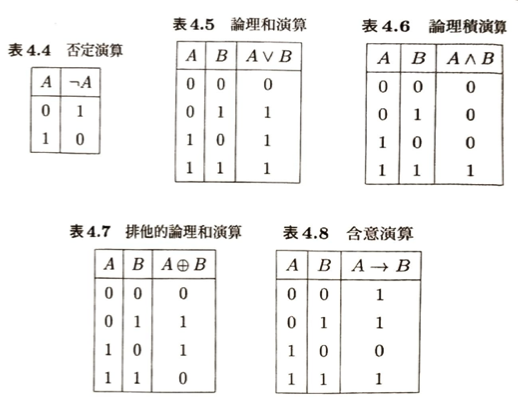
なりすましの発信行為によって完全性が損なわれます。デジタル署名やハッシュ関数は完全性を実現します。ランサムウェアによってファイルにアクセスできなくなり身代金を要求されたとき、可用性が損なわれています。
公開鍵暗号を信頼するには、Aのみが秘密鍵を知っていることが前提で、その仕組みは認証局の公開鍵認証基盤の提供です。公開鍵暗号は電子署名にも用いることができます。
.jpg)
2022年4月に改正個人情報保護法が施行されました。下記のような状態での漏洩の事態の際は個人情報保護委員会への報告および本人への通知が義務付けされました。

どのように機能し、そのように判断するかのプロセスを理解するのは透明性です。
共通鍵暗号のことを対称暗号ともいいます。公開鍵暗号は非対称暗号です。リサンプリング(個人を特定できないようにすることの1つ)とは、手元のデータから一部のみを取り出して(一部と明言した上で)利用に供することです。トップコーディングは、例えば80歳以上は実際の年齢を80歳以上とするなどです。リコーディング(グルーピング)は階級で大きくくくることです。ミクロアグリゲーションとは、ある特性値において各個人の値をそのグループの平均値や中央値で置き換えることです。PRAMとはある確率に従ってカテゴリーを入れ替えることです。
Open Knowledge Foundationとはオープンデータの可能性を最大限に引き出すことを目的とした国際的な非営利組織です。オープンデータの公開性の評価のために5スターオープンデータがあります。例えば、PDF<Excel<csv<RDF<LOD(ロジカルなネットワーク(LOD: Linked Open Data))の順で星が増えます。レベル3以上はオープンフォーマットです。
オープンライセンス<編集可能<SWを問わない<外部からリンクが可能<外部へのリンクがあるという理由になります。
4つ星までは「データの形式」の問題ですが、5つ星は「データ同士の繋がり(セマンティック・ウェブ)」を目指す段階であり、データの孤立を防ぐという点において最大の優位性があります。

オープンデータは、利用できる、再利用できる、誰でも使えることが条件です。例えば電子行政オープンデータ戦略では、二時使用のルールは積極的なデータ公開、機械判読可能、営利非営利問わずに活用を促進することが原則です。
各種オープンデータは、e-stat(人口統計など政府統計ポータルサイト)やDATA.GO.JP(各府省の保有データを利用できるデータカタログサイト)があります。
統計法はデータに関する基本的な法律です。第1条は使う目的です。基幹統計とは、行政機関が作成する統計のうち総務大臣が指定する重要な統計です。(第2条第4項)。それを作成するための統計調査を基幹統計調査といいます。(第2条第6項)。報告義務(第13条)があります。かたり調査の禁止(第17条)(公的調査を装う詐欺を許さない。)、地方公共団体による事務の実施(第16条)、調査関係者の守秘義務(第41条)があります。統計調査のために2次的に利用可能です。調査票情報の自らの利用(第34条)、匿名データの提供(第36条)があります。オーダーメイド集計及び匿名データの提供を受けるには手数料の納付が必要です(第38条)。
調査実施者は自ら行った統計調査の調査票情報でもその利用は統計の作成等を行う場合に限定されます。調査実施者は自ら行った統計調査の調査情報を一定の要件を満たした民間事業者や個人に提供できます。委託による統計の作成等は、調査実施者等が、一定の要件を満たした一般の依頼者からの依頼に対して、統計成果物を作成・提供することをいいます。匿名データとは、一般の利用に共することを目的として調査票情報を特定の個人や法人等の識別ができないように加工したものです。委託における統計の作成等や匿名データの提供を受けるには、手数料を納付しなければなりません。
k-匿名性とは、データセット内の各個人が、少なくとも(k-1)人の他の個人と区別がつかないようにする手法です。例えばヒストグラムにて2つの階級値を用いる場合、変換されたデータベースは3-匿名性を持ちます。
匿名化について他には、連結可能匿名化は連続性のあるIDを発行して連結表を持つことです。連結不可能匿名化は連結表を持たない、仮IDすら持たないことです。
数理に関する基礎的な事項
ド・モルガンの法則のことを双対性ともいいます。
10桁のパスワードと言われた場合、最高位には0が入っても問題ないパターンが普通にあります。
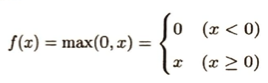
シグモイド関数y=1/(1+e^(-x))の逆関数がロジット関数です。ロジスティック損失関数はシグモイド関数に自然対数をとったものです。
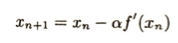
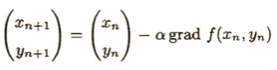
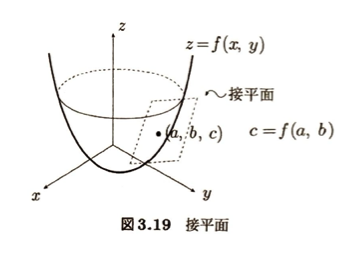
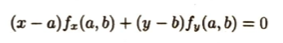
等高線の接線の方程式は、接する平面の方程式において、z=cとしたときの結果となります。
情報に関する基礎的な事項
2の補数は、負の数を絶対値が同じ正の値から1を引き、その値のすべてのビットを反転させれば良いです。
例えば3ビットで考えるとき、−1は1を考えて1−1=0つまり2進数にすると000なので111です。−4は4を考えて4−1=3つまり011つまり100です。
整数型を浮動小数点数形式で保持した場合、符号部、指数部、仮数部で表現するため表現できる整数は同じビットではかなり少なくなり、整数の表現として上位互換性はないので問題があります。仮数部を4ビットに増やせば精度が一桁改善されますが、指数部が3ビットで8通りに減るので表現できる数の範囲が1桁狭くなります。
浮動小数点形式で整数は丸め誤差を伴わずに正確に表現できることはありません。また浮動小数点形式は表現できる最小値から最大値までの値をすべて正確に表現できるわけではないです。
情報落ち=絶対値が大きい数と小さい数の加減で小さい数が結果に含まれないこと
桁落ち=大きさが近い数同士の引き算で有効数字が減ること
打ち切り誤差=値の計算を途中で打ち切ることにより生じる
丸め誤差=有効桁数などにより桁が制約されて生じる

ちなみにゼタより上はヨタ(Y)、ロナ(R)、クエタ(Q)です。ピコより下は、フェムト(f)、アト(a)、そしてゼプト(z)、ヨクト(y)、ロント(r)、クエクト(q)と小さくなります。
まあ試験には出ないと思いますけどね!笑
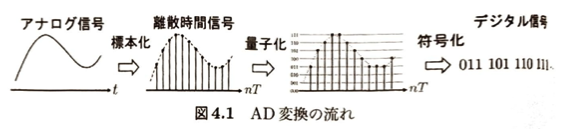
標本化定理とは、離散時間信号からアナログ信号を復元する際の定理で、サンプリングレートがアナログ信号に含まれる成分の最大周波数の2倍より大きければ誤差なく完全に元の信号を再構成できます。パルス符号化変調(PCM)は量子化された2進数ラベルを時間インデックスの順に並べてデジタル信号を得る方法のことです。
画像では2次元の空間の座標に対して輝度値が割り当てられます。輝度値は階調で表します。画像データは容量が大きいので圧縮されます。ただし白黒画像なら0 or 1です。カラー画像ならRGB方式が代表的で、R,G,Bそれぞれを256階調で表現する場合、1ピクセルあたり8bit×3色で24bitになります。可逆圧縮はPNGやGIFです。非可逆圧縮はJPEGです。動画において1秒あたりの画素数(fps)はフレームレートといいます。現在の地上波デジタルテレビ放送では29.97fpsです。
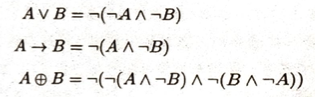
IEEE754は浮動小数点形式の標準です。けち表現とは、最初の非0桁f_1を1として省略し、f_2以降の桁のみを用いると、実質的に1ビット多くの情報を保持できるためにそのように呼ばれます。
Aには97を割り当てるなど、非負整数値の集合を、符号化文字集合=文字コードといいます。
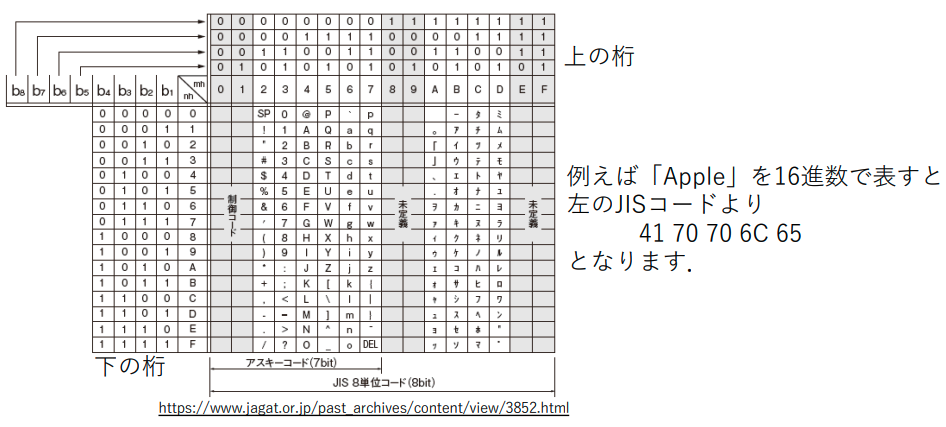
ASCⅡコードはアルフベッド数字や記号に7ビットで表現できる数字を割り当てます。1バイトで表される文字をシングルバイト文字で日本語など2バイトで文字を表現する方式をダブルバイト文字です。JISコードは0~65535と日本語の文字を対応させる方法式です。コンピュータにUnicodeを用いる場合には文字符号化方式を用います。例えばUTF-8です。シフトJISは、シングルバイト文字2つとダイルバイト文字の区別をするためのもので、半角カナが使えますが複雑な処理をします。この前にEUCがありました。データサイエンティストの試験などでは、特に「UTF-8はASCIIと互換性がある」という点がよく問われます。
.jpg)
2進木(根から出発して高々2つの子を持つように作られる木です)の点vに対して、vから根まで辿ったときに通過する枝の本数をvの深さといいます。各点の深さの最大値を2進木の高さといいます。高さkの2進木Tに対して深さk未満の点がすべて表れているとき、平衡2進木といいます。つまり各葉の深さが(高々1しか違わず)揃っており、バランスの取れた木です。
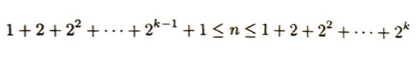
アルゴリズムの基本的構成要素として、代入、順次構造、選択構造、繰り返し構造があります。
構造化定理とは、順次、選択、反復の3つの構造で任意のプログラムが表現できることです。
結局、選択ソートがオーダー的には一番効率が悪いのですね。また、フィボナッチ数列のアルゴリズムはO(τ^n)です。
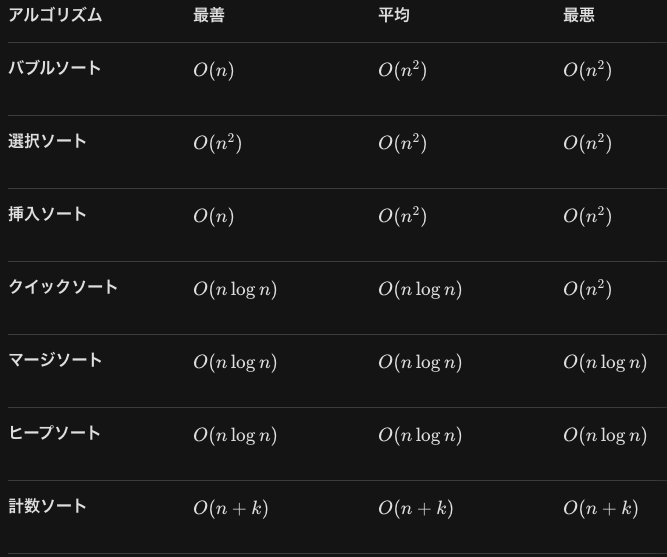
計数ソート<ヒープソート=マージシート<クイックソート(ここまでlog)<バブルソート=挿入ソート<選択ソートの順です。
配列は連続的にアクセスしやすいですが要素の追加や削除に時間がかかります。対してリストは要素とポインタの組から形成されるのでアクセスに時間がかかりますが、要素の追加や削除には便利です。つまり両者の長所短所は真逆の関係になります。現代ではリストにするメリットがあまりありません。連想配列はキーと値の組を格納するデータです。Pythonにおける辞書です。検索を高速で行えるのでデータベースでも使用されます。
インタプリタ方式(Python、R、JavaScript)は開発時の修正作業が容易であり、可搬性が高いですが実行時の性能は低いです。コンパイラ方式(Java、C、C++)はプログラムが大きくなるとコンパイルの完了を待つ時間が長くなります。また可搬性が低いですが実行時の性能が高いです。これも真逆の関係があります。
.jpg)
Pythonでbreakはfor文などを強制終了して抜けるための命令です。


csvは単純すぎるため複雑な構造のデータにはXMLを用います。<>がないのがJSONです。{}を用います。XML形式は複雑な階層的データを表現できます。csv、XML、JSONはいずれもテキストデータです。JSON形式はJavaScriptのオブジェクトの表記法から発生しました。
形態素を表すタグを品詞(POS:Part of Speech)タグといいます。
tf-idfは、単語の出現頻度(tf)にその単語を含むテキスト数の逆数をかけ合わせた値です。単純な出現頻度でなく、テキストにおけるその単語の重要度を示す値です。
以下に具体的な例題を挙げます。
| ID | 内容 |
| Doc1 | "Python Data" |
| Doc2 | "Data Science" |
| Doc3 | "Science Cooking" |
ここで全文書数N=3で、各文書における各単語の重要度を考えます。


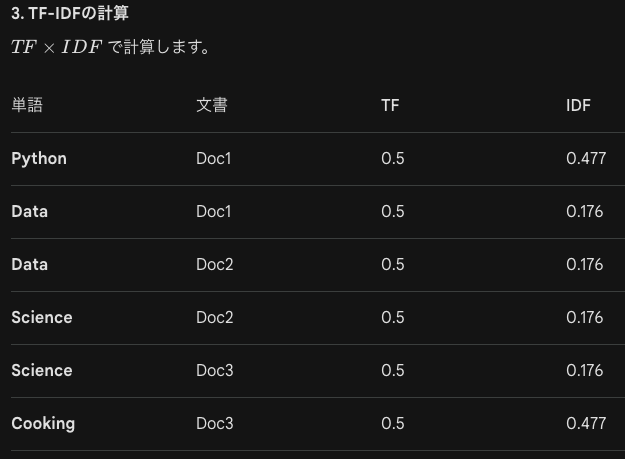

これらの解析の利点は、重要度の低い単語を無視することで次元削減できます。また、scikit-learn の TfidfVectorizer を使えば、これらを一撃でベクトル化可能です。ただし単語の頻度についての手法なので、単語の意味は考慮されません。対策としてはBERTやTransformerなどの意味ベクトルを用いる手法が主流です。これらはG検定の範囲です。
.jpg)
コサイン類似度は、テキスト間の類似度を2つのベクトル(テキスト)がなす角度で表現します。
グラフにおいて閉路を部分グラフとして含まない連結グラフを木(グラフ)といいます。グラフを表現する際に隣接行列がありますがデータ量を減らすために隣接リストがあります。これは1と表示される行列の成分を書き足していくものです。
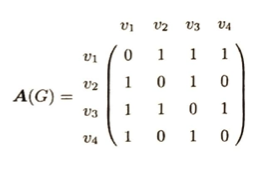
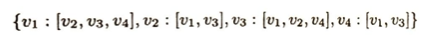
データベース管理システムとしてOracle(米国オラクル社)、DB2(IBM)、SQL Server(マイクロソフト)、MySQL(オープンソース)、PostgreSQL(オープンソース)があります。
リレーショナルデータベースは1970年代にコッドにより提案されました。第1行を属性やフィールド、第2行以下がタプルやレコードと呼ばれます。
商演算について考えます。
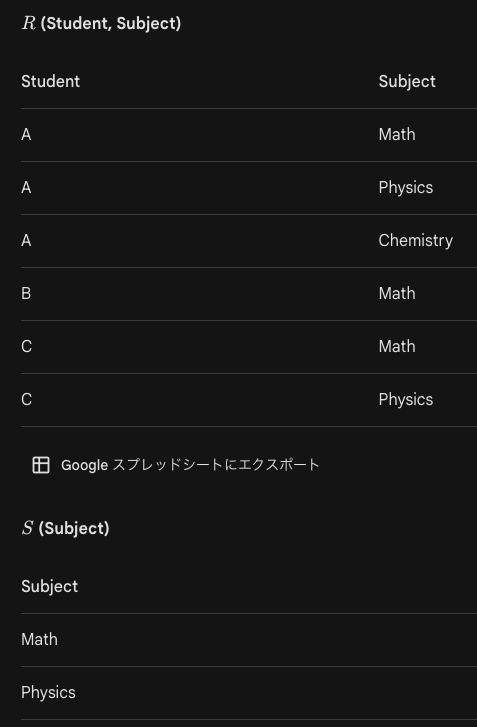

データベース管理システムの機能は、メタデータ管理、質問処理、トランザクション管理などがあります。

| 社員番号 | メールアドレス | 氏名 | 生年月日 |
| 101 | a@ex.com | 佐藤 | 1990/01/01 |
| 102 | b@ex.com | 鈴木 | 1995/05/05 |

次に正規化について考えます。これにより更新時異状、削除時異状、修正時異状が防げます。第1正規化までではこうした異状が起こる可能性があるので第3正規形まで追っていきます。
| 学生ID | 氏名 | 講義コード | 講義名 | 担当教官 |
| 101 | 田中 | CS01 | アルゴリズム | 佐藤教授 |
| 101 | 田中 | CS02 | データベース | 鈴木教授 |
| 102 | 佐藤 | CS01 | アルゴリズム | 佐藤教授 |
まずこの表は第1正規形です。なぜなら、1つのセルには1つのデータのみ入っているからです。もし「講義」の欄に「アルゴリズム, データベース」とカンマ区切りで入っていたらそれは非第1正規形なので、それを1行ずつに分けるのが第1正規形です。公式教材には第1正規形までしか掲載されていませんが、第2正規形以降も解説します。
第2正規形は、部分関数従属の排除が目的です。つまり主キーの一部にのみ依存している情報を別テーブルにします。

第3正規形は推移的関数従属の排除が目的です。つまり主キー以外の列に依存している情報を別テーブルにします。

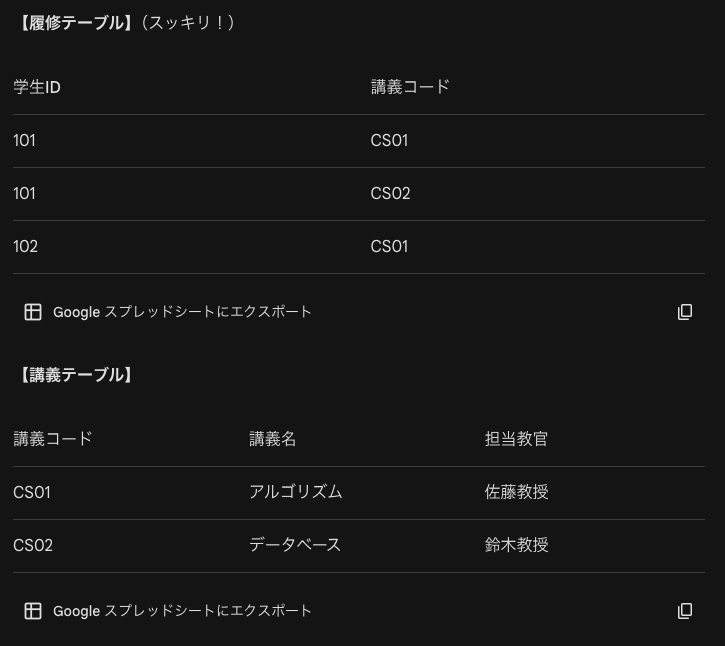
結合演算によって元のリレーションに戻せるようなリレーションの分解は情報無損失分解と言われます。
外部キーとは、その値が空でないときは、他のリレーションの主キーの値をとる属性のことです。
NoSQLにおいて、共有データシステムでは、整合性、可用性、分断特性の3つの性質のうち2つしか両立できないCAP定理があります。NoSQLでは、基本的に可用(CAP定理の意味で)、ソフト状態(入力がなくても時間経過とともに変遷していくかもしれない)、結果整合性(整合性のないデータでも更新要求がなく、システム障害などが発生しなければ、いつかは整合するということ)というBASE特性があります。
キーバリューデータベースは、Dynamoが採用し、列指向データベース(クローラが収集したwebサイトデータなどを収集)は、Bigtableが採用し、ドキュメント指向データベース(XMLやJSON)は、MongoDBが採用し、グラフデータベースもあります。
名寄せとは同一の意味を表す異なる表記のデータを同一のものとして扱う処理です。
統計・可視化に関する基礎的な事項
量的データをメジャー、質的データをディメンジョンともいいます。
量的変量は、示量性変量(総和量を算出できるデータ)と示強性変量(総和量に意味を与えられない密度や速度などのデータ)に分けられます。
5数要約は最小値、第1四分位数、第2四分位数、第3四分位数、最大値のことです。
同じクラスターに属する調査対象は似た性質を持ちやすいので標本には偏りが生じる可能性が高いです。
異常検知は異常データが少ないので教師なし学習を適用します。典型的なアプローチとしてはpdf(確率密度関数)を使う方法があります。pdfの結果から閾値を超える値を異常と見做します。
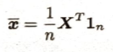
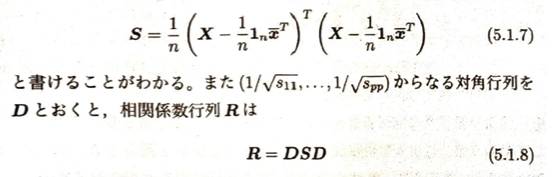
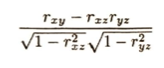

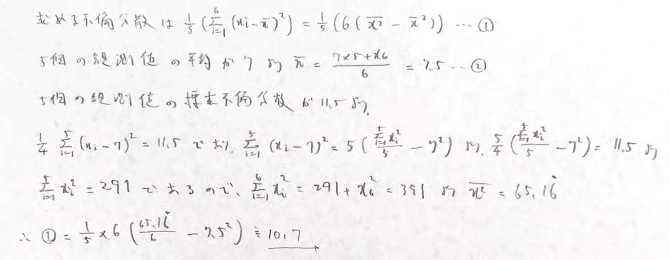
ベイズの定理周辺は時間がかかるので後回しが賢明です。
| 混同行列 | 予測:正 (Positive) | 予測:負 (Negative) |
| 実測:正 (Positive) | TP (True Positive: 真陽性) | FN (False Negative: 偽陰性) |
| 実測:負 (Negative) | FP (False Positive: 偽陽性) | TN (True Negative: 真陰性) |
| 指標名 | 別名 | 定義式 | 意味(直感的な理解) |
| 正解率 (Accuracy) | - | 最も単純 | 全体のうち、どれだけ正解したか |
| 適合率 (Precision) | 精度 | TP/(TP+FP) | 「正」と予測したもののうち、本当に正だった割合 |
| 感度 (Sensitivity) | 再現率 (Recall) | TP/(TP+FN) | 実測が「正」のもののうち、正しく予測できた割合 |
| 特異度 (Specificity) | - | TN/(FP+TN) | 実測が「負」のもののうち、正しく負と予測できた割合 |
| F1値 (F1-score) | - | F値のこと | 適合率と再現率の調和平均(バランスの指標) |
ROC曲線において横軸は偽陽性率(FPR)=1ー特異度です。縦軸は真陽性率(TPR=感度=再現率)です。ちなみに不均衡データに強いPR曲線は(縦軸:適合率、横軸:再現率)です。

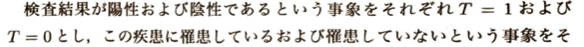

モーメント推定量を求めよと言われたら、対象となる確率分布に注意します。また不偏性はnによらないので、不偏性について判断する場合はn=1として様子を見ることも有効な手段です。
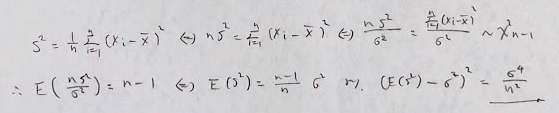
この解き方はアクチュアリー数学での常套手段です。


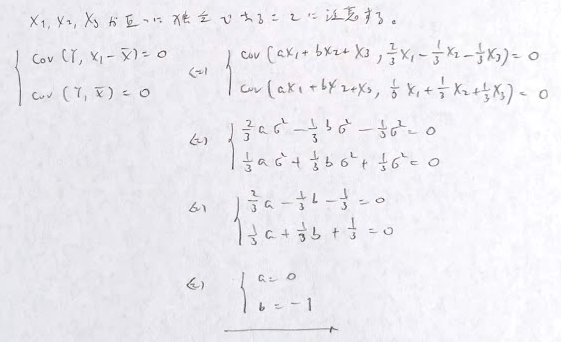
和の不偏分散も通常の分散の公式つまり共分散が出てくる公式に対応しています。その理由は、その公式の両辺にnをかけて両辺をn-1で割れば和の不偏分散の式が出てくるためです。
単回帰モデルにおいて、切片が0のとき(RTOモデル)について、βを求める公式は通常の公式とは異なる形になります。残差の和が0にならずに回帰直線がデータの重心を通る保証がなくなります。通常の決定係数を計算すると負になるケースがありますので、RTOでは決定係数の定義を全変動の捉え方から変える必要があります。

独立性の仮定を行うと、カイ2乗検定統計量は次のように計算できファイ係数と密接な関係があります。
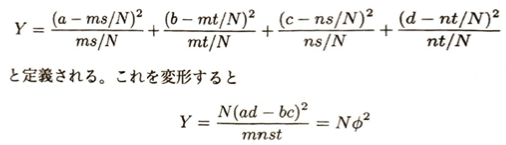
次の問題が指定教材『データサイエンス発展演習』の中で最難問です。
まず以下のことに注意します。度数分布の器つまり、各試行で得られた結果(成功回数k)が何回発生したかをカウントするための「バケツ」を準備している状態を意識しましょう。
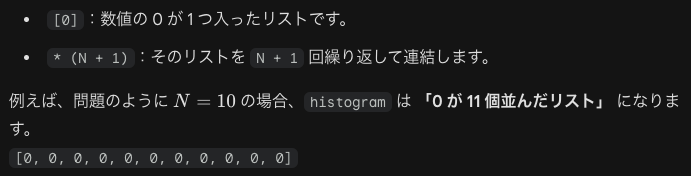
0からNまでの整数を数え上げるためには、合計でN + 1個の要素が必要になります。


施策を行った対象を処理群や処置群、行わなかった対象を対照群やコントロール群といいます。また、自然実験とは、偶発的な実験状況になっているケースです。
条件のそろったペアを作ることをマッチングといい、このようにして得られたデータを対標本といいます。処理の前後での比較を行うことを差分の差分法といいます。
時系列データは折れ線グラフによってチャート化するといいます。チャートジャンクは過度な視覚的要素です。散布図においてプロットに自治体名などの文字列を加えてると情報過多になります。円グラフはカテゴリを2-5にします。
前年同期比について原系列を計算すれば季節変動を除去できますが、季節調整済み系列の前年同期比を用いると2重に調整されるため不適切です。
人間の視覚属性は、次の順で比較しやすいです。位置>長さ>向き(角度)>太さ(幅)>大きさ(面積)>色(彩度または明度)>色(色相)>形
覚え方は、語呂「イナム・フオ・サシカ」。勢いで考えました。

A/Bテストでは調査が長期化すると調査期間中に気候や社会情勢の変化など広告デザイン以外の条件が変動する可能性があるため、時期的な影響を受けない程度に短期間で十分なデータが得られるように実験を設計すべきです。
A/Bテストの例として、アプリでさまざまなクーポンを発行して顧客の反応が良いものを見つけたいときに用います。k-means法の例は、顧客を類別してそれぞれのアプローチを考える際に用います。
離散一様分布に従う確率変数YはU~U[0,1]のとき、Y=INT(nU)+1です。
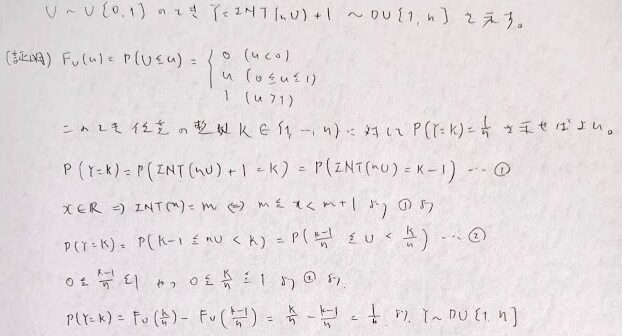

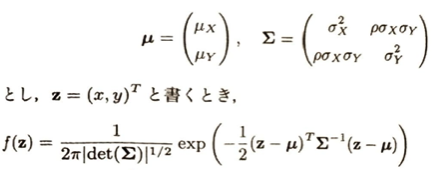
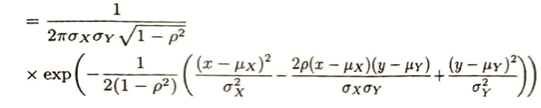
混合正規分布はGMMといいます。これは複数の正規分布の和で表現されます。
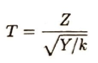
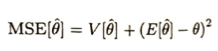
p値とは、帰無仮説のもとで、それ以上に極端な値を観測する確率です。また先ほども説明を行いましたが、2×2分割表においてカイ2乗統計量をYとすると、Y=N(φ)^2が成立します。わかち書きとは、文章において語の区切りに空白を挟んで記述することです。日本語はそれを行いません。

名詞出現頻度を度数分布表で表しても良いですがワードクラウドという視覚に訴える方法もあります。

画像認識では画像から抽出された特徴量を元に機械学習やアルゴリズムによる解析を行います。シーン全体を推測することをシーン認識、ここの物体の情報を抽出するには物体認識を行います。物体認識では物体検出と画像分類の双方を行います。物体検出はバウンディングボックスを利用し、画像分類は特徴抽出器と分類器によって構成されます。近年は特徴抽出器と分類器が合わさっています。
顔画像検出はViola-Jones法で、Harr-like特徴量による顔画像検出を行います。ImageNetは画像認識向けの大規模データセットです。AlexNetはILSVRC2012でトロント大学が考案しました。CNNの畳み込み層では特徴を取り出してプーリング層で画像を小さくします。UCF101は101種類の動作認識を行うデータセットです。
回帰のモデルは平均平方二乗誤差(RMSE)つまり、残差平方和をnで割ったものの平方根を取ったものが、最小になるモデルを構築することが一般的です。MSE(平均二乗誤差)はRSMEのルートを取る前です。これらは外れ値の値の影響を受けやすいですが、MAE(平均絶対誤差)は誤差の絶対値の平均のため、外れ値の影響をRSMEほど受けにくいです。MAPEは誤差の割合で評価するための手法です。
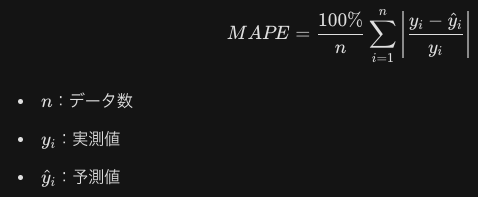
主成分分析は教師なし学習です。主成分分析では特徴量は元データの一次結合でありますが、深層学習においては非線形な特徴量をもつオートエンコーダ(自己符号化器)が用いられます。


DS検定の模擬試験
本番の3日前である2026/4/29に指定教材『データサイエンス発展演習』の第8章の模擬試験を解きました。合格圏で安心しましたが、色々と課題が残る結果となりました。
選択肢にて、該当するものをすべて選べ、などの表現に注意しましょう。僕はそれで1問正解を逃しました。
終盤の問題ではアクチュアリー数学と似た雰囲気の問題もありました。おそらく難問指定だと思うのですが、それが正解していて他の暗記系の問題で失点していることが勿体無いと感じています。残りの3日間で知識の抜けを埋めていきたいと思います!
DS発展で用いるPythonのライブラリ
本書の巻末にあるDS発展試験にて出題される内容が整理されていますので、ここでまとめます。
MATH
通常の戻り値は浮動焦点です。複素数には対応していません。
math.pow(x,y)=x^yでmath.log(x[,base])=底がbaseのxの対数でbaseが指定されていないとeが使用されます。rradians(degree)でdegreeが度数法で書かれた角度を弧度法で表現します。
NumPy
np.dot(A,B)は行列積です。
NumPyには制限もあり、配列のサイズは固定されており、一度作成すると変更できません。
Pandas
表形式のデータにデータクレンジング、加工、分析などの操作ができます。


Pandasにも制限があります。
Scikit-learn
Scikit-learnはオープンソースライブラリです。

2026/4/29日現在で本番まであと3日になりましたので、当日の戦略を立ててXに投稿しました。
DS発展の本番の難易度

本番では作戦通り少しでも考えてしまう問題を後回しにして1周目を10分以内で終えました。2周目を終えた時点で合格ラインの17問は確保できていたと思います。3周目は答えまで辿り着くのに5分程度要する問題を解きました。最後の4周目で複雑なアルゴリズムの問題や他の問題では最も答えに近いものを2択まで絞って選びました。
DS発展では公式教材のレベルと模擬試験の難易度で本番の予想をした難易度の1つ上の難易度だと思っておいた方が良いです。僕が今回受けた回が難易度が上振れしていた可能性もありますが、公式参考書よりも全体的に難易度が高いと感じました。
数学の問題で数学検定1級1次と同等の問題が出ていて驚きました。次のデータサイエンスエキスパート試験は統計検定準1級〜1級のレベルのようですので、しっかりと勉強して準備をしていきたいと思います。


{kind=link}