
2025年5月15日にDX推進パスポート3を取得できました。ITパスポート→G検定→データサイエンティスト検定リテラシーレベルの順で合計で3ヶ月で取得できました。学習方法やおすすめの参考書などを振り返り、学習にお役立てくだされば嬉しいです。
各試験についての記事のリンクは下記になります。
ITパスポート→G検定→データサイエンティスト検定リテラシーレベル(DS検定)


-678b62a34bdcc.jpg)
ITパスポート
ITパスポートの学習はG検定やデータサイエンティスト検定と比べて難易度が低く感じました。その理由は、試験範囲が狭く、下記の基本書『【令和7年度】 いちばんやさしい ITパスポート 絶対合格の教科書+出る順問題集 (絶対合格の教科書シリーズ)』と過去問道場の演習を行う勉強法でほぼ過学習を起こさないと判明しているからです。
僕は令和6年版を使いましたが、こういう試験の参考書は絶対に最新版が良いです。その理由は試験範囲の改訂と最新の時事状況が反映されているからです。

ITパスポートの試験内容はG検定やデータサイエンティスト検定と被る部分も結構あります。そのため、まずはITパスポート単体で攻略し、その後にG検定とデータサイエンティスト検定をほぼ同時攻略する戦略で試験に臨みました。下記の試験対策記事は主にほぼインプットメインになっております。
過学習の起きやすさでは、ITパスポートが最も低く、G検定が中くらい、データサイエンティスト検定がかなりの高さになります。データサイエンティスト検定は合格ラインが8割程度となっており、この3つの検定の中では最も難しい試験だと考えています。データサイエンティスト検定(DS検定)では白本+黒本の問題メインの学習だとギリギリ8割に届かない状況に陥りやすいとかなり言われています。
G検定
ITパスポートの次はG検定です。G検定の勉強のまず先に『人工知能は人間を超えるか ディープラーニングの先にあるもの』を読んで人工知能とは一体なんなのだ?を感じました。

本書の読了後の数ヶ月後に本格的にG検定の対策に入りました。2025年1月から学習を開始しました。G検定とデータサイエンティスト検定の学習の順序がやや入り組んでいます。詳しい時系列は僕のXのページをご参照ください。
以上で赤本『最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版』や黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』とヤン先生の緑本(有名な教科書の方)『ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[第2版] [徹底解説+良質問題+模試(PDF)]』と(問題集の方)『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』で模試を除く学習となりました。
上記の本の中では結局、赤本が最も難易度が高いと感じました。1ページ1ページの解説量が深く解説されており、理解ができればかなりの情報量を吸収できると思いますが、僕はそれが難しかったので、赤本の内容を理解できるところまでは理解しようという気持ちでインプットに取り組みました。
AIに関する法律は本番で結構出てくるという声が多いです。そのため『ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト』を用いて別途インプットする必要性を感じてAIに関する法律関連のみをインプットする本書を購入しました。しかし本書の前書きにも書いてある通り、G検定の合格という意味ではかなりのオーバーワークだと感じました。しかしとても良い本であることは確かです。
G検定の模試(過去問としての演習)
G検定の模試の1回目は不合格の点数

ここまでの黒本とその他の問題集で行った1周目時点の演習問題の成績はこちらです。後から気づいたことですが、こういった結果報告はブログの記事内でなくX上で行った方がデータベース的には良いかなと気づきました。
間違えた問題や確信が持てずに正解した問題もあることも要因の1つですが、G検定の章のもう少し後からこのXの埋め込みのスタイルになります。
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の1回目の結果は次の通りでした。明らかに弱い分野(1回インプットしただけで覚えていない部分)が明確になっています笑
第1章:6/7
第2章:10/16
第3章:18/36
第4章:21/30
第5章:7/25←ディープラーニングの要素技術
第6章:7/52←ディープラーニングの応用例
第7章:8/14
第8章:10/12
第9章:3/13←AIに関する法律と契約
第10章:11/15
合計:101/210≒48%
2025年1月23日の時点(インプットして復習せずに解いた結果)ですね。このままでは合格ラインに達していないので、しっかりと復習してから内容を消化していきたいですね!
黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』での演習で少し経過した後に、復習なしで別の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』を用いた問題演習の結果は次のようになりました。黒本の内容と併せて、試験本番までに間違えた問題を正解できるように訓練しておきたいですね。
第1章:16/23
第2章:41/58
第3章:44/77(RNNやCNNやQ学習やVAEなどの箇所がほとんどインプットされていない)
第4章:23/57(ディープラーニングの応用についても定着しにくいので何回も見直す必要があります)
第5章:15/23
第6章:24/64(AIの法律関連はまとめてインプットする必要があります。)
第7章:26/30
合計:189/332≒57%
復習をしない段階での模試を抜かした場合の1周目の得点率は189/332≒57%でした。しっかりと復習していかないと合格点には届かないことが分かりましたので、試験前までにしっかりと復習しておくことが大事だと心から思います。ここから本記事にある書籍に付属する模擬試験やネットで行える模試を解いた後で、さらに先ほどの2冊の本の演習問題を解きました。2周目の結果は以下になりました。
G検定は参考書の付属模試や特典という形での模試があります。僕は黒本などの問題の正解率が半分程度の状態で模試を受けてみようと思い、実際に受けてみました。
あと7点で合格ラインと言われる7割でした。試験では試験の特性上、調べるという行為ができるため、この時点で合格はできそうと感じました。この模試の難易度は当時の自分には高く感じたので、復習は試験の直前にとっておくことにしました。
G検定の模試の2回目で初めての合格点超え

その後、やや自信が付いてきた段階で、赤本『最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版』の学習を再度行いました。赤本は1回目はインプットで通読しているので2回目としては初めて問題として解いてみました。
この時点で1週目は消化不足かなと思っていた内容が、実際に問題として解いてみると8割の正解率を超えていたので、G検定に関して手応えを感じ始めてきた時期になりました。
Xはリプライという形で復習はしやすそうな媒体ですよね。
復習をメモとして残していこうとこの時から思い立ちました。
その後に黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の2週目の問題演習を行いました。こちらも正解率が8割を超えて軸の部分は理解できるという確信が持てました。
そしてヤン先生の緑本の問題集『ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)』の2週目の問題演習に取り掛かりました。やはり本書の難易度は高めに設定されている感じがしましたが、しっかりと勉強させていただきました。
本書は前書きにも書いてありますが、法律の問題が多めです。その傾向は模試の問題にも現れています。一般に法律問題が多いと難易度が高いセットとなります。
この段階でG検定の模試の2回目として黒本『徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版』の巻末の模試に挑戦しました。
G検定の模試の3回目でまぐれ正解でないことを確認

G検定の本番の問題は黒本の模試よりも難しいという声も聞きますので、さらに模試を重ねる覚悟をしました。
G検定の模試の3回目としてヤン先生の緑本(問題集ではなく教科書で有名な方)『ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[第2版] [徹底解説+良質問題+模試(PDF)]』の模試を解きました。本書の模試は1回分でしたので貴重な1回として解きました。尚、問題集の方の模試の方が難易度は断然高めです。
模試で8割を超えられた結果が続いたので、G検定の学習の前半はここで一旦終了となりました。
G検定の模試の4回目で法律多めの難問セットに挑戦

3回目の模試の結果の時点で本番でよほどの難問セットが来なければ合格は大丈夫だろうと感じたので、数日間データサイエンティスト検定の学習に回しました。そして数日後に再びG検定の学習に戻りました。
G検定の模試の5回目で難問セットで8割越えの王台へ
次は上で行った模試の次の模試を行いました。法律系の出題が多めのヤン先生の模試での初めての8割ごえは嬉しかったです!時間も1時間45分なのでやや余裕がありました。途中眠くて一瞬寝てしまいましたが、それでも15分余ったので良かったです。
もちろん本番中は寝てはいけません。2時間という長丁場の試験なので自己コントロールが大切です。僕も実際に模試を受けていて「G検定は眠気が襲ってくる可能性がある」ことを学びました。
前向きな出来事でしたね!笑。本番は色々と気をつけましょう!
G検定の模試の6回目で赤本の特典模試の復習回
いよいよ本番間近の残り3日となってきたので、1回目の模試である赤本『最短突破 ディープラーニングG検定(ジェネラリスト) 問題集 第2版』のもう一つの特典模試(時間制限なしの方)に挑戦しました。1回目は不合格の点数となっているので、合格点の7割を超えられるか挑戦しました。実際は1回目の模試と同じ問題で配置が変わった問題セットでした。1回目の模試は復習が未完了の状態でしたので、完全に実力勝負の模試となりました。
8割に到達したとはいえ、間違っている問題が40問程度あるのは、あまりよろしくないと思うので、ここでしっかりと復習しておきたいですね。
G検定の模試の7回目でStudy-AI模試に挑戦
public leaning boxの模試を解きました。なんと問題が200問以上あり、164/223≒74%の正解率でしたがシステム的には不合格の判定となりました。ちなみに全問題調べることを禁止で、わからない問題はとりあえず選んで次へ次へとやっていったら50分くらい余りました。実際は残った時間で不明な問題を調べることになりそうです。
G検定の模試の8回目でStudy-AIの最新シラバス100問に挑戦
前回と同様のStudy-AIさんの最新シラバス対応の模試を受けました。全部で98問あって73問の正解で74%の得点率でした。しかし前回と同様にシステム的には不合格の判定のようでした。明日が本番なので、もう1種類の模試で自己ベストを出せるように気合を入れます。
G検定の模試の9回目でdiverさん提供模試で本番直前確認
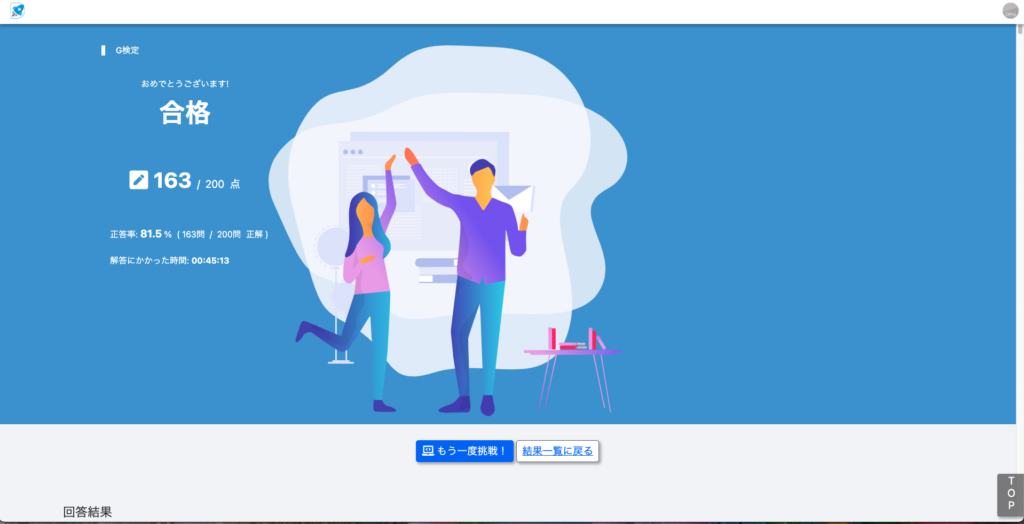
明日の本番前の直前模試で8割でした。調べ物をしない状態だと8割前半が自己ベストだと感じました。今回の模試で残り時間が1時間14分だったため、本番では分かる問題をケアレスミスなく解いて、余った時間で参照の時間にします。
そして試験直前の日の就寝前に公式ページにある20問の直近の過去問を解きました。法律問題を3問間違えてしまいましたが、良い勉強になりました。
G検定の本番
本番は参考書や問題集に載っていない問題が多かったです。しかし参考書や問題集で学んだ知識を用いて得た内容を消去法などを用いて正解を導くことはほぼ全ての問題で出来ました。G検定は今後、範囲が増えて難易度が上がっていくと思われますので早めの受験と取得をおすすめします。
G検定本番は難しく感じました。複数書籍で勉強し模試で問題慣れしないと本番の試験で時間切れになる可能性があり、また実際の難易度を見て面食らう可能性があります。ただしG検定はAI全般の知識をバランスよく学習できる素晴らしい検定試験だと思います。
データサイエンティスト検定
データサイエンティスト検定の1問1問の難易度はG検定の問題と比べるとややぶつ切り感があります。そのためDS検定の内容はG検定の時とは異なり、X上でなくブログ内にて残した方が見やすいと判断しました。また、G検定のインプットが深い部分まで要求されることに対して、データサイエンティスト検定は、もう少し広い範囲を実用的なレベルの理解で説明できれば良いと判断しました。ただし範囲が広いので下記の記事に全体の内容をインプットしてからアウトプットに移行しました。
『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』を用いた学習が間違いないです。

僕はこの白本を各章に分けて数回の読み込みを行いました。その理由は白本の読み込み不足で惜しくも合格できなかった方々の様子を知っているためです。
本章はDS検定の学習記録ですが、データエンジニアリングの分野は特にアウトプットが大事になります。アウトプットは『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』を用いた学習を合格者の多くは実践しています。

また模試も大事です。上の2冊の書籍に付属している模試やネット上の模試などを駆使して合格を目指していきたいところですが、実は緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書』というDS検定の教科書的な存在を知り調べたところ「緑本の内容は白本のわかりにくい部分を噛み砕いて説明しており、節末問題や模試で本番とかなり似ている問題がかなり多い」との情報を得たので急遽、追加で購入し問題と模試を解きました。
G検定と比べるとインプットの大変さはDS検定の方が緩やかだと感じました。そのためDS検定の方は割と早めに模試へ移行しました。

DS検定の模試(過去問としての演習)
DS検定の模試(問題演習)を計5種類行います。用いる模試は①公式本『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』の巻末に付属している模試、②公式本『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』の購入者特典模試、③2024年に出版されたヤン先生の青本『データサイエンティスト検定[リテラシーレベル][徹底解説+良質問題+模試(PDF)] 最強の合格テキスト』の購入者特典模試、④黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』に付属している模試、最後に⑤DS検定の教科書と言われる緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書』の巻末の模試になります。④の黒本模試を最後に持ってきたのは模試の中では最も難易度が高いと言われています。⑤の緑本の模試は最も本番に近いという合格者からの声も聞く素晴らしい模試です。
データサイエンス分野をDS、データエンジニアリング分野をDE、ビジネス分野をBIZと表記します。
1回目:リファレンスブックの付属模試
1回目(復習しないで受けた状態)では合計が35/50で7割で合格ラインの8割には届きませんでした。敗因は明らかにDE分野です。そのための対策として公式本『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』のDE部分のみを周回して読み込むことにしており実行しています。その結果、DE分野の得点率が別模試にて大幅に上昇しています。
DS分野の1回目は18/24で正解率は75%でした。目標の8割までもう少しなのであやふやな理解の部分をしっかり復習して2回目に備えます。
相関があっても因果関係があるとは言えません。指数関数のグラフが直線になるのは対数スケールにした場合です。y軸を対数スケールに設定します。原点を0以外に設定すると見た目と実数にずれが生じて誤った解釈を招く可能性があります。ヒストグラムは区間ごとの度数データを違い色で表すと見難いです。3Dグラフを立体的にすると実際の割合と視覚的なずれが生じ誤った解釈を誘発しやすく不適切です。5-foldsクロスバリデーションは、データセットを5等分し、そのうち1つを検証データとして使用し、残り4つを訓練データとして使用します。これを全ての分割で繰り返します。クロスバリデーションのプロセスが終了した後で使用していないデータは存在しません。連合学習ではデータを共有せず、各端末で学習されたモデルのパラメータを中央サーバーで統合して最終的なモデルを構築します。コンテンツベースフィルタリングはユーザーの好みに基づき類似したコンテンツを推薦します。協調フィルタリングはユーザー同士の行動や評価の類似性を基に推薦します。プーリングは特徴マップのサイズを小さくする操作です。
DE分野(最も苦手意識が強い分野)の1回目(インプットを1度した段階で挑戦)は7/13で54%でした。公式本『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』を何度も読み返すことが得点力アップに役立つと知り、もう1度目を通した際にリファレンスブックの特典模試のDE部分に挑戦しました。
第一正規化はテーブル内の各カラムが原子的な値をもち、重複するグループのデータが存在しないようにすることが目的です。第二正規化は第一正規化を満たした上で、各テーブルがその主キーに完全に依存する非キー属性のみを含むようにすることを目的とします。これは主キーの一部にのみ依存する非キー属性を排除することで達成できます。Apache Sparkはイミュータブル(不変)なデータ構造です。データ変更が必要な場合は、変更を適用した新しいデータセットを生成する方法が一般的です。A以前はAは含みます。「s?」はsが0回か1回です。「(/.*)?」はスラッシュで始まるURLのパス部分で、任意の文字列にマッチします。文字列を日付型に変える関数は、TO_DATE関数です。ブラックボックステストは内部構造に触れずある特定の入力に対する期待される出力のみを確認したい場合に用います。画像型の学習済予測モデルの例はOCRです。OAuthを用いる場合、まず認証サーバーに対してアクセストークンを要求します。これにはクライアントIDとクライアントシークレットなどの認証情報が使用されます。アクセストークンを受け取ったらトークンをHTTPリクエストのAuthorizationヘッダーに付与してAPIを呼び出します。これによりAPIサーバーはリクエストを認証し、適切なデータへのアクセスを許可します。
BIZ分野の1回目(インプットを1度した段階で挑戦)は7/8で約88%の正解率でした。ここはITパスポート試験やG検定などの学習で下地ができていたと推測します。失点してしまう分野でなく安心しています。また全問正解を狙えるように細かい部分まで注意を払いたいところです。
データを扱う際はデータの欠落事実を透明にし、分析における限界や仮定を明確に示すことが大事です。
モデルカリキュラムの1回目の結果は3/5でした。出題数が少なめですが油断しないように気をつけたいところです。
予測データ分析では、過去の情報を用いて定期的におこりうる事象の予測や検知を自動で行うことが可能です。四半期予測は季節変動を捉えられず、交通機関はイベントや天候などの要因が捉えられず、ポートフォリオ予測は複雑な要素がありますのでこれらは不適切です。医療現場において適しています。運動習慣と病気は、相関関係も因果関係もあります。
2回目:リファレンスブックの特典模試
1回目(公式本の付属模試の後に復習をした後の状態)は82/100で合格ラインの8割を超えることができました。しかし実際の試験ではこの模試よりも難易度が高いようです。その後に行う模試も合わせた過学習にならないように気をつけた学習が必要です。
DS部分の1回目は42/50で84%で目標の8割を超えることができました。スタージェスの公式など「こんな問題も出るのか」という発見がありました。本試験ではノーミスで乗り切って後の苦手分野の失点をカバーする作戦を立てています。
スタージェスの公式はnをサンプルサイズでkを階級数とすると、k=log2(N)+1です。平均値を対称に分布していると正規分布の可能性があります。日次データは日次で集計することが望ましいです。散布図は横軸を独立変数にして縦軸を目的変数にします。異常検知と次元削減は教師なし学習です。活性化関数は入力層に用いません。隠れ層は計算に寄与します。画像のリサイズによりモデルへの入力が一貫した形になります。第1種過誤とは、実際には効果がないのに統計的に効果があると誤って結論づける誤りです。移動平均は特徴量のスケーリングや変換とは異なります。平行座標プロットは、複数の変数間の関係性や全体的なパターンを一度に確認するのに最適です。時系列データでは時間の順序が大事なので、過去のデータを訓練データとし未来のデータをテストデータとして分割します。
DE部分の1回目は22/30で73%の正解率となり目標の8割まで後少しでした。公式本『最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版』の付属模試で初めてDE部分に触れた際に強烈な苦手意識を感じましたが、実際の問題がSQLとそれ以外で構成されると気づいたので、SQLの基本的な部分は取れるようにすること+公式本のDE部分を読み込むことを試験までに何回も行う作戦を立てています。
非構造化データの例は顧客がウェブサイトに投稿したレビューのテキストです。なぜならフォーマットが決まっておらず雑多なテキストデータであるためです。一人の顧客は複数の注文を持てるので、1対多です。第三正規化は第二正規化を満たして、非キー属性間の依存関係を排除したものです。
正規化問題は時間がかかるまたは難問の可能性が高いので後回しにした方が無難です。
*は0文字以上で、^は先頭を意味するとき、^A*B*C*の一例は、AABBCCです。JSONのネストされた構造(あるものの中に、それと同じ形や種類の(一回り小さい)ものが入っている状態や構造、つまり入れ子構造のこと)は、単一の平坦なCSVファイルに変換する際に複雑を生じる場合があります。地域の昇順で並び替え、売上の金額の昇順で並び替えると意味のあるものになります。
顧客データを送信し予測結果を受け取るとき、サーバーにデータを送信し、処理を依頼するPOSTリクエストを用います。POST(データ送信+作成)とGET(取得)の違いは、POSTはキャッシュされずデータ長の制限なし、GETはキャッシュされデータ長に制限があることです。POST(リソースの新規作成)とPUT(リソース作成または完全更新)の違いは、POSTはサーバがリソースの場所を指定し、PUTはクライアントがリソースの場所を指定することです。サーバはリソースなどの提供者で、クライアントはリソースなどの利用者です。
BIZ分野の1回目は17/19で89%の正解率でした。良い感じですがやはりDE分野での失点数が気になるので、BIZ分野では全問正解を目指したいところです。
ELSIは倫理的・法的・社会的課題の頭文字で、行き過ぎる技術の社会適用に関する課題を扱ったものです。準委任契約では業務期間や工数に基づいて費用が支払われます。収益モデルと主要な変数を考えたいとき、顧客の定性データだけでは情報不足となります。歩留まりは製造業や生産プロセスにおいて、投入された材料や工程のうち、実際に完成品として利用可能な部分の割合を指す言葉です。効率性や生産性を評価するための重要な指標の一つです。
モデルカリキュラムの1回目は1/1で失点なしでした。
3回目:青本の模試

本記事作成時では知らなかった情報ですが、この青本の模試は難易度が異様に高いそうです。青本模試に取り組まれる方は、点数が低くても自信喪失しないようにしてくださいね。
3回目の模試は、緑本のインプットを終わった時点で青本の特典の模試を使用しました。100分全て使い手応えを感じない問題がかなりあり、どれくらい正解しているのだろうかという興味を持ちながら採点しました。結果は65/100で、もしもこのレベルの問題が出題されたら後15点取れば合格ラインだとわかりやや安心しています。
「たくさん間違えた=たくさん学べることがある」と考えて前向きに学習を行いましょう!
DS分野は40/53で正解率が75%程度でした。解いていた感想ではかなり本格的な偏微分の問題があったり、本番ってこんなに難しいのかな?と思うところがありましたが、固有値の計算ミスもあり、良い練習になったと思います。おそらく実際の試験ではここまで数理の比重は高くないと推察します。
分類指標の1つにTPR(真陽性率)があります。これは検査の感度とも言います。データの離散化は量的変数を質的変数に変換する操作でビニングとも言われます。ミンコフスキー距離のp=1の場合がマンハッタン距離です。データ数が多いとデンドログラムが複雑になりクラスタを決めにくくなります。非階層クラスタの方が大規模データセットに対しても高速で実行可能です。時系列解析は非定常性のモデルも扱えます。時系列分析では過去のデータから将来のトレンドやパターンを予測します。ROC曲線は分類器の性能評価に使われます。年齢は間隔尺度の量的データです。順位は順序尺度(質的データ)で比例尺度ではありません。四則演算ができないので平均値も出せません。並行座標プロットの横軸は各変数名のラベルで縦軸は各変数の値です。
フィッシャーの3原則は偶然誤差と系統誤差の2種類の誤差を減らすことが目的です。乱塊法はこれら3原則を全て満たす実験計画法です。
反復は偶然誤差を評価します。無作為化は系統誤差を偶然誤差に変換します。局所管理は系統誤差を生じる可能性のある要因によってブロックに区切り、各ブロック内で比較したい条件を全て含ませます。局所管理は無作為化以上に系統誤差を減らす効果があります。
モデルは数値しか学習しないので都道府県はダミー変数に変換します。第一種過誤=偽陽性です。疑似相関は相関関係はあるが因果関係はない状態です。フルカラーはPNGとJPEGでPNGは画質は劣化しませんがJPEGは劣化します。AACは音声データです。アクティブラーニング(能動学習)は一部のモデルの精度を向上させるのに有効と判断したデータのみラベルをつけて学習に使用します。SVMは教師あり学習です。外れ値は境界線の決定に影響を及ぼします。One-Hotベクトルは文章内のユニークな単語の数と同じ次元です。一般に高次元になります。そしてスパースな数値表現です。モデルの規模を小さくすると必要な訓練データの量や計算リソースや計算時間も節約できます。
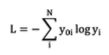
上式の交差エントロピーの使い方は、たとえば4クラスの分類問題で3番目のクラスが正解の時、正解ラベルは、y_01=0、y_02=0、y=_03=1、y_04=0となります。そしてモデルの予測値がそれぞれy_1~y_4が与えられたときに上式に代入すれば答えが得られます。
不均衡なデータを用いて分類モデルを訓練するとき、データ量の少ないクラスの予測精度が低く出る傾向です。アップサンプリングなどは偏りをなくす効果が高いとは言えません。交絡要因は因果関係が存在しない2変数の相関係数を高くするように影響を及ぼす第三の要因のことです。電子メールや実験ノートはフリーテキストなので非構造化データです。ChatGPTは答えを出す際にウェブ上を参照しません。ChatGPTは本来言語のみ生成します。ノイズ除去は新たな画像の生成とは趣旨が異なるので画像生成の応用例ではありません。欠損値は明示的欠損と暗示的欠損があり、後者は不適切な値が入っている状態です。実験計画法はバイアス抽出の効果はありません。
DE分野は13/25で52%の正解率でした。ほとんど未知の問題が多かったのでここでしっかりと復習して吸収していきたいですね。
2段階認証は機密性を高めるもので完全性は保持できません。DWHは多様な情報源から収集され整理されたデータを保存し分析のためにアクセスしやすくなることを目的としたデータベースです。
データレイクは構造化・非構造化問わずあらゆる形式のデータを格納できます。DWHは分析にすぐ使用可能な処理済みのデータを保管しています。データマートは特定の部門やビジネスエリアに焦点を当てたデータのサブセットを提供するため、全社で横断的なデータ分析を可能とするDWHより狭い範囲です。
FTPは特定のコンピュータ間でファイル転送に使用するアプリケーション層のプロトコルです。セキュアな通信はFTPS、SFTPを使用します。80番はHTTPで20番と21番がFTPです。
通信を行う人数が増えると鍵の管理が複雑になるのは共通鍵暗号方式の特徴です。RSAは公開鍵暗号方式のアルゴリズムです。ハッシュ関数は入力データの長さに関わらず固定長のハッシュ値を出力します。一方向性アルゴリズムと言われています。AESは共通鍵(秘密鍵)暗号方式の1つで平文を一定の長さごとに暗号文に変換するブロック暗号です。RSAは公開鍵暗号で巨大な素数同士の掛け算の素因数分解の困難性を用います。積で公開鍵を2つの素数をもとに秘密鍵を生成しますので公開鍵を手に入れても対になる秘密鍵を割り出すのは困難です。RC4は共通鍵(秘密鍵)暗号方式です。DSAはデジタル署名方式です。
JSONはnull、bool値、オブジェクト、配列のデータ型に対応しています。{ }の中でキーと値がコロンで区切って記述され、キーは必ずダブルクォテーションで囲む必要があります。シングルクォテーションだとエラーになります。またJSONは文字列データのみを扱います。XMLはデータ交換のためのデータ形式です。スタイルシート言語としてXMLはXSLで、HTMLはCSSが用いられます。JATSは学位論文などの雑誌記事をXML形式で記述するのための共通規格です。
OAuthは利用者の認証情報そのもののやり取りはしていません。Apache Sparkは大量データに対する処理を複数のコンピュータに分散して並列してインメモリで処理を行うソフトウェアです。Apache Kafkaは分散データストリーミングプラットフォームです。Apache Stormはオープンソースのビッグデータ処理フレームワークでリアルタイム性が要求される用途に適しています。Apache Hadoopは一回の分散処理ごとに結果をストレージに書き込むのでApache Sparkより処理速度は遅いです。UIはボタン設計などです。SOAPは異なるコンピュータ上で動作するプログラムがネットワークを通じて通信し連携して動作するための軽量な通信プロトコルです。記述にXMLを用います。データ転送はHTTPの他にSMTP、FTPも用いることができます。SOAPはエンベロープ、ヘッダ、ボディに分かれます。角丸長方形は端子でフローの開始と終了を表します。ループの開始はダイヤモンドです。ログデータはクラウドと相性が良いです。量が多いためです。Amazon AthenaはDWHではありません。
ER図のIDEF1X記法ではPは1以上、Zは0か1、nは定数n、n-mは範囲指定された定数です。
ORDER BY句は指定がない場合は昇順でソートされます。◯%□は◯を□で割った余りを指します。感情のポジディブなどを表現するプロンプトは「昇進試験に合格した」//ポジティブなどとします。
BIZ分野は12/22で54%の正解率でした。普段はこのような結果にはならないので、やはり青本の模試はかなり難し目に作られているのだと思いました。ただし問題はかなり良いと思うのでしっかりと復習していきます!
SLOはどのレベルのサービスを目標値とするかです。オープンデータは正確性は保証されません。
個人データはデータベース化された個人情報です。マーケティング分野ではRFM分析で顧客をグルーピングし市場を細分化します。Rは直近購入時期、Fは購入頻度、Mは購入金額です。AIに指示を出すときは、制約条件をなるべく明確かつ具体的に記述すると効果的です。初学者の人がAIに指示を出す際にまずはプロンプトをシンプルに書いてみるのが良いです。
4回目:黒本の模試

黒本『徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応 第2版』の模試はDS、DE、BIZ分野の区分けがなく、完全ランダムな出題になっており、その意味では異色な模試となります。
4回目の模試は黒本の模試でした。結果は75/90で正解率は83%で合格ラインを超えることができました。時間は50分で解けたので、なかなか良い感じだと思われます。
テストの点数は間隔尺度です。e-statはオープンデータが公開されています。
Web APIで次のようなHTTPメソッドがあります。DELETEは指定されたリソースを削除、GETは指定されたリソースを取得後クライアントに返す、POSTはクライアントがサーバに対してデータを送信、PUTは指定した場所にリソースを保存します。通常はXMLやJSON形式です。これらを用いて画像データや音声データの送受信ができます。Web APIを実現する際に用いる設計原則の1つをRESTと言います。
SCPはSSHの機能でファイル転送をします。転送が中断されても途中から再開できません。SFTPはSSHで暗号化されますがSCPと異なり途中からの再開ができます。オンプレミスは初期費用が高く、災害時のリスクが大きく、物理的なスペースが必要な欠点があります。BIはデータを蓄積、加工したデータ分析、データの可視化ができますが、ノーコードAIツールとは異なります。ウィルスはプログラムの一部を改ざんし自己増殖を行います。ロジックボムは特定の条件を満たした際にコンピュータを攻撃します。ワームはプログラムに寄生せず単独で自己増殖をします。二値化は画像の画素を一定の条件下で白か黒かの画素に変化することです。深層学習のYOLOの物体検出手法が多数提案されています。U-Netはセマンティックセグメンテーション手法です。対話は人による質問に対し答えを音声で返すタスクです。シグモイド関数はロジスティック回帰で用います。UMAPは次元削減法です。t-SNEより高速で非線形次元削減にも適用できます。post-hoc analysisは実験計画法の統計的解析手法です。データレイクはデータをそのままの形で保存します。データオーギュメンテーションは機械学習で学習データを水増しする手法です。棒グラフでデータの理解に関して誤解を招くような軸幅の操作はできません。チャートジャンクとは不要な視覚要素などで視聴者の注意を逸らすような視覚要素です。3次元散布図は3つの変量を座標軸とした散布図です。散布図行列の対角成分は各変数のヒストグラムです。ヒートマップでは3変数をそれぞれ別の色で表現する場合は、1つのマスを複数の色で塗る必要があり、効果的な可視化を行えません。
MySQLでデータ型はNUMERIC(小数点を含む数値など)、VARCHAR(可変長文字列など)、TIMESTAMP(日付と時間など)などがあります。
データセットは機械学習などで用いるデータ集合、データマートは特定の利用目的のために抽出されたデータの保管場所です。正規表現で特定の条件に当てはまる数値や文字列を検索できるので、その結果に対して数値や文字列の置換を実行できます。交差結合は2つのテーブルのデータの全ての組み合わせを抽出する処理です。差はあるテーブルから別のテーブルに含まれる行を取り除く演算です。
CSVはカンマで区切るデータ形式で、値をカンマで区切ったものが1つのレコードとなりそれぞれのレコードは改行により区切られます。テキストデータの記法でバイナリデータも使えます。空白を値を区切るのはSSVです。エスケープ機能でカンマを記号として含ませることができます。
FTPサーバは不特定多数と共有する際にanonymousというユーザIDを作成します。通常はパスワードとしてクライアント側のメールアドレスを入力します。adminは管理者のためのIDです。Jupyter Notebookは方程式やグラフなどのドキュメントの生成や共有が可能です。言語はPythonやRやRubyなどが可能です。開発環境に位置付けられます。SQLのコマンドのDCLはデータを制御する言語です。GRANT(権限付与)やREVOKE(権限取り消し)などがあります。
RDBの例はMySQL、PostgreSQL、Oracle Databaseなどです。NoSQLはHBase、MongoDB、Redisなどです。
公開鍵暗号方式は共通鍵暗号方式より処理に時間がかかります。GDPRには越境移転規制があります。HGPはヒトゲノム計画です。本籍地や労働組合への加盟などは金融分野の情報保護ガイドラインにおける機微情報です。本人の同意の有無を問わず提供を禁止します。これは要配慮個人情報の取り扱い基準より厳格です。匿名加工情報は本人の同意を得ずとも利用できます。仮名加工情報の提供は法令に基づく場合を除き禁止されています。準委任契約では善管注意義務が課せられることがあります。疾患などでは1次情報が大切です。
オプトアウト(緩い)は本人の同意を得ずに提供できる制度です。個人情報保護委員会への届出が必要です。一方でその都度本人の同意を得る必要があるのはオプトイン(厳しい)制度です。
報告書には課題の定義、仮説、検証結果、考察結果、施策の実行の5つを入れます。結論がわかっている場合はトップダウン型です。
5フォース分析は新規参入者の脅威、売り手の交渉力、買い手の交渉力、代替品や代替サービスの脅威、既存企業同士の競争です。僕は次のようなイメージで覚えました。語呂は「ファイブ・フォースは神機だけど売る気かい?」で行きましょう。
新
売 既 買
代
仮説検証に必要なデータ確保は仮説検証結果を評価するときでなく、仮説検証時に行います。機械学習に詳しい人材が社内にいない場合は外部委託が考えられます。アジャイル開発のスクラムは1ヶ月以内で設定します。A/Bテストも大事です。
5回目:緑本の模試
最後の模試はDS検定の教科書の緑本『合格対策 データサイエンティスト検定[リテラシーレベル]教科書』の模試を行いました。今回の模試も黒本の模試と同様に分野横断型の模試でしたので、一括で得点を出しました。75/90で約83%の得点率で合格点を超えることができました。DS検定の模試は1回目の模試と青本(これは本当に難しい)の模試で正解率が合格ラインに届かずといった感じですが、それ以外は合格ラインを超えることができていた結果となりました。
ROCの内側の面積をAUCで0.5~1を取ります。HadoopはHDFSで複数ストレージに分散蓄積、SparkはRDDでメモリ保存。業務で資料報告の際は1次情報を用います。政府の公開資料からの引用にも出典明記します。データサイズと最大振幅は関係性はありません。反対にサンプリイングレート、量子化ビット数、録音時間は影響します。CPSはSociety5.0でのサイバーフィジカルシステム。
原価率=売上に対する原価の割合
ReLU関数は中間層で用いる。運営コストの削減について、店舗を運営する上のコスト(原材料費、光熱費、人件費)ですが売上に関する仮説は運営コストとは無関係です。マルウェアでネットワーク感染はワーム。個人情報授受の契約は渡し方と管理方法や破棄なども取り決めます。データ追加はINSERT文。CREATE文はテーブル作成。JSONはキーと値のペアでデータを表現する構造化データです。
文字誤り率=(挿入誤り語数+置換誤り語数+削除誤り語数)/実際の音声の全文字数
=(0+2+2)/21=0.19
実際の発話: 昨日はたくさんの子供が公園で走っていました
音声認識結果:機能はたくさんの子供が公園で走っていた
画像の正規化は各画素の0~255の値を0~1に狭めて変換する処理。アナログ画像を正方形に区切る作業は標本化です。全数調査では誤差が発生します。検定力は帰無仮説を正しく棄却する確率です。支持度=全ての実績で商品A、Bが購入された割合、信頼度=商品Aが購入された後でBも購入された割合、リフト値=商品AがBの購入率をどれくらい引き上げたかの指標。Jupyter Noteookはプログラム実行などはボタンなどのGUIで操作可能です。
プロジェクトの結果報告資料の作成は、現状課題→分析方法などのアプローチ法→分析結果→結果からの意味合い→次のアクション提案
問題解決力=解決すべき問題の本質を見極め、その問題について対応策を考え、解決に導く能力です。
次の問題は統計検定準1級(対策記事はこちら)に類題が出題されているレベルの難問(というより良問)です。
-scaled.jpg)
10000人に1人が感染する病気について99%で陽性・陰性共に正しい結果が出る検査を受けた人に陽性が出た場合、その人が罹患している確率は(P(B|A)×P(A))/P(B)=(0.99×0.0001)/(0.99×0.0001+0.01×0.999)=0.009804です。
この問題は条件付き確率の問題で非常に読みにくい問題ですが、事象Aを罹患、事象Bを陽性とした場合に、P(A|B)を求めるだけです。
P(A)=0.0001、P(B|A)=P(実際に罹患していて陽性)=0.99よりP(B)=P(実際に罹患して陽性)+P(実際に罹患してなく陽性)で求められますね!
代表値には相加平均も含まれます。アプリケーションを開発するためのインターフェイスはAPIです。因果関係→相関関係が成立します。例えば最高気温の上昇にともなってビールの売り上げが上がる傾向が得られたと問題文にある場合は因果関係があるとしてOKです。自動的に相関関係も認められます。欠測は初めから欠けている場合で脱落は途中で外れた場合です。交絡バイアスは中間因子と直接関係しない交絡因子により引き起こされた偏りで、分析段階でも調整可能です。データ収集時に対象の意思が存在する場合には自己選択バイアスが生じます。中央値をヒストグラムから読み取ることは困難です。公開鍵暗号方式と共通鍵暗号方式を合わせたSSLという仕組みがあります。
G検定の試験日にDS検定の5回目の模試が終わったところです。ここから苦手な問題の復習としての追い込み作業に突入します。またQC検定4級とQC検定3級の学習も同時進行となりました。
その他の問題演習(公式HPの模擬問題など)
DS検定まで残り2日となりました。ここで盲点を潰すべくネットに転がっている問題を解いて演習量をこなしました。検索すると公式が出している模擬問題が転がっていました。その他にもいくつかの問題をこなして苦手な分野を潰す作業に取りかかりました。
電気使用量の1日単位の予測モデルで不要な情報はマンションの1時間あたりの日照時間です。(その他は毎日の水道使用量、家庭の所得、家族構成が選択肢にありました)。重相関係数はyとyハットの相関係数で説明変数がモデルをどれだけ説明できるかを示します。この2乗が決定係数です。散布図について、縦軸は因果関係のある変数を、横軸には結果となる変数を置きます。ソフトウェアを使用した暗号化と復号について、データの機密性が高い場合は、ソフトウェアによる暗号化を鉄橋して保存します。
数値データの特徴量化について、相互作用特徴量は異なる特徴量同士の組み合わせから新しい特徴量を生成する手法です。これは特徴量エンジニアリングの手法です。元の特徴量の単なる組み合わせ以上の情報をモデルに提供できます。これによりモデルの性能向上や構造を適切に捉えることが可能になります。
Amazon S3:データ保存
Instagram Filters API:画像処理
Google Cloud Speech ~to -Text:音声をテキストに変換
データをクリーニングしたい時、例えばNULL値や範囲外の値を規定値に更新するクエリは、UPDATEです。背景色の変更は視覚的な対比を生み出しデータの協調に貢献します。またデータサイズも同時に拡大すると効果的です。指数関数は縦軸が対数スケールの片対数グラフが適しています。
XML文書は常にルート要素から始まり、階層的な構造を持ちます。可読性が高くテキストベース形式です。データ型の指定はなく様々な形式を扱えます。数値や日付なども表現できます。タグ内の属性は単一だけでなく複数の値も取れます。属性は名前と値のペアで表現され必要に応じて複数の属性を持たせることができます。
セグメンテーションを利用した自動運転の応用例は車両の車線変更検出です。車線との相性が良いです。フローチャートで表現することが適切なプログラム仕様は制御構造です。特異度は真陰性率のことです。つまり特異度=TN(真陰性)/(FP+TN)です。感度は真陽性率でリコールのことです。
データサイズをnとすると、二重ループの計算量は最悪でO(n^2)、単一ループはO(n)、直接アクセスではO(1)、シャッフルはO(n)です。
SELECT※FROM table_name ORDER BY RAND() LIMIT 1; はテーブルからランダムに1つのレコードを取得する意味になります。データポータビリティについてユーザの同意が倫理的かつ法的な観点から重要な要素です。変数が質的変数の時、関係の強さを算出するのはカイ2乗検定です。
以上がDX推進パスポート3のための学習の軌跡となります。これからの時代にDX人材の需要は増えてくると思います。多くの方がこれらの資格に興味を持たれ、学習されることを願っております。

{kind=link}