2026年6月8日にデータサイエンスエキスパート試験を受けて合格しました!
DSエキスパートの勉強方法は公式テキスト『データサイエンスエキスパート演習』を周回するだけで合格することは可能です。ただし本書は1章の重みがとてもあり、1ページの中でも行間が広いものも散見されます。そこで僕が勉強をしながら行間を埋めたり具体的な例題を探して解いたものもまとめて各章ごとの公式テキストの内容を消化していきたいと思います。

コンピュータの構成
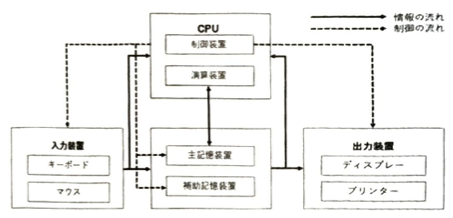
コンピュータの内部にはマザーボードという電子回路基板にバスという接続線の束があります。バスを介して様々な接続がされています。コンピュータの処理は主記憶装置上に記憶された命令とデータを読み込み、このデータに対して命令に固有のある決まった処理を繰り返して実行しメモリ上のあるルールに従って変化させていくことにより実現しています。コンピュータは論理的には命令とデータを記憶する記憶領域とこの記憶領域から命令とデータを読み取り、命令のルールに従い処理結果を記憶領域に書き出す処理を繰り返す機械(チューリング機械)としてモデル化されます。
命令とデータの扱いには2種類あります。1つは命令とデータを同一記憶装置に保存しておき、同一のバスから読み書きを行うノイマン型(プログラムストアード型)アーキテクチャ(現在のパーソナルコンピュータや汎用サーバで利用されます)で、もう1つは命令とデータを異なる記憶装置に保存しておき、それぞれ別々の命令バスとデータバスからCPUとやり取りさせるハーバード型アーキテクチャ(家庭用ゲーム機械や家電製品などの機械を制御する組み込みマイコンで利用されます)です。
データ収集
デジタルデータ収集
インターネットはIP(Internet Protcol)によって接続された世界をつなぐネットワークです。DNS(domain name system)とよばれるサービスがドメイン名からIPアドレスを教えてくれます。サービスとはネットワーク経由で提供される機能で、サーバはサービスを提供する側です。
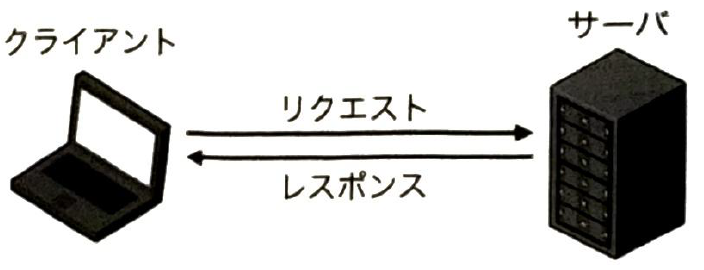
クライアントがサーバに要求することをリクエストといい、サーバが応答することをレスポンスといいます。上図との対立概念はP2P(peer to peer)で特定のサーバを介せずネットワークに接続されたコンピュータ同士が直接通信します。プロトコルは通信のやり方を決める方法です。SSHはリモートログインのためのプロトコルです。データ収集についてウェブサーバへの適切なリクエストとレスポンスのダウンロード、ダウンロードされたHTMLファイルの解読(パース)、それを受けて次の適切なリクエストを構成してデータを集めることをスクレイピングのソフトウェアには求められます。tobots.txtというファイルがスクレイピングの許可・不許可を指定ている場合がります。


これはいかなるソフトウェアでもパス/searchはスクレイピングしてはならないですが、その中でも/search/aboutであれば許可されています。スクレイピングは1ページをリクエストしたら次まで数秒開けることが望ましいとされます。多数のサイトを巡回して、あるいは長期にわたって定期的に情報を網羅的に集めることをクローリングといいます。これを行うソフトウェアをウェブクローラーといいます。これを走らせるサービスの代表が検索エンジンです。スクレイピングが禁止されているサイトでも、情報を積極的に提供するためのWeb APIを提供していることがあります。これは必要な情報だけをウェブページのような余分な情報なしにプログラムにとって読み取りやすく容量の小さなデータで取得できる仕組みです。通常、特殊なフォーマットでリクエストを送ることで、情報を取得する側にとってもHTMLファイルをパースするよりも楽に望みのデータを取り出せます。
ハッシュ値において、異なるデータでも偶然同じハッシュ値になることはあり得ますが、極めて稀です。そのためほぼないと考えてOKです
ハッシュ値の暗号化の鍵は秘密にしておいて復号の鍵は公開しておくのですね!
サイバーセキュリティでは情報セキュリティの3要素が大事です。そのほかに真正性、責任追跡性、否認防止、信頼性などがあります。
| サービス種別 | 正式名称 | 特徴(何を借りる?) | 具体例 |
| SaaS | Software as a Service | ソフトウェアそのものを借りる。Webサイトへアクセスするだけで使える。 | Gmail, Dropbox, Microsoft 365 |
| PaaS | Platform as a Service | ソフトウェアの開発や実行に必要な環境を借りる。 | Google Colab, Microsoft Azure, IBM Cloud |
| IaaS | Infrastructure as a Service | 計算機資源やネットワークなどのインフラを丸ごと借りる。 | Google Cloud, AWS EC2 |

センサーデータを取得するときセンサーを搭載し、情報を収集して送ることができるエッジデバイス(小型コンピュータ)を使います。スマート家電なども含まれます。IoTは情報量が大きくなりすぎるので蓄積のためクラウドを利用することがあります。エッジデバイスではセンサーの情報を加工・抽出してクラウドへ送るデータ量を減らし、場合によっては匿名化をおこなってセキュリティを高めます。GIS(geographic information system)は地理情報システムでセンサーの位置をGISに取り組むためには、GPSなどで位置情報を取り込む必要があります。Wi-Fiのアクセスポイントを頼りに位置を特定する方法もあります。
データ表現とデータ構造
データ表現とデータ構造について考えます。
データ表現
どのような対象をどのような数値の列として扱うかはデータ表現とよばれ、数値化する作業は符号化といわれます。文字データは文字コードの数値に変換します。テキストデータは文字コードの数値の列として表現されます。画像の符号化は画素が縦横に並んだものとして扱います。白黒の場合は例えばFAXなどには白と黒の2値で表現します。これらは各画像の明るさを数値化します。
色の情報を持たせる場合、RGBを考えます。これらの光の強さを数値として表現します。または、各画素を色相、彩度、明度の3つの値として記録するHSV(Hue,Saturation,Value)表色系も使われます。RGBの値とHSVの値は相互に変換できます。
印刷の際は、CMYK表色系(水色のCyan,紫のMasenta,黄色のYellow,黒のKey plate)です。これは、水色、紫、黄色の3色で任意の色を作り出せる仕組みからです。これhemoらRGBの光を吸収するので全ての光を反射する白い用紙に必要な量ずつ塗るとRGBを必要な割合だけ反射する状態にできます。理論上は3色を混ぜれば黒を作れますが、技術的に人間の目で見て自然な黒になるようなインクは作れていません。
音声の符号化は気圧の変化を一定時間おきに計測して記録すれば実現できます。1秒間あたりの計測頻度をサンプリングレートと呼ばれます。画像データと同様に計測したデータは量子化されて記録されます。
データの圧縮と効率化について考えます。可逆圧縮は文書データやプログラムなど正確な情報が必要な対象に、非可逆圧縮は人が見聞きして許容される程度の情報損失なら許されるマルチメディアデータを対象に用いられます。可逆圧縮されたデータを元通りに戻すことを解凍といいます。
| 手法 | 戦略 | 向いているデータ |
| ランレングス | 連続を見つける | 同じ色が続くイラスト、FAX |
| ハフマン | 頻度を見つける | 文字の出現に偏りがあるテキスト |

「ABCABC…」のようにデータが連続しない場合は、かえってデータ量が増えてしまう(A1B1C1…)という弱点があります。


どのビット列が元データのどの数値を表すのかの割り当てテーブルがないとデータを元通りに解凍できません。そのためその分のデータも増えます。出現頻度に偏りがなければデータが大きくなってしまいます。
その他の手法も含めてまとめます。
| 手法 | 仕組み(ざっくり言うと?) | 特徴・キーワード | 主な用途 |
| ランレングス符号 | 同じデータの「連続」を回数で数える | AAAAA → A5 | FAX、単純な画像 |
| ハフマン符号 | 「頻度」が高いものほど短い符号を振る | 偏りを利用する | ZIP、JPEGの仕上げ |
| LZ77 | 前に出た「同じパターン」を参照する | スライド窓、コピー&ペースト | 汎用データ圧縮 |
| LZSS | LZ77の改良版。 Storer氏とSzymanski氏による | より効率的なコピー指示 | Deflateの基礎 |

音声や動画データはデータ容量が大きいので一般的には非可逆圧縮が用いられます。人間が見聞きする分には劣化に気づきにくい部分を省略するような手法が使われます。画像データならば、人間の目の細胞には明るさを感じる細胞が多く、色合いを感じる細胞が少ないので、それに合わせた圧縮方法が利用されます。JPEG画像はまさにその例です。RGBの値を明るさと色合いに分けて、明るさはそのままで、色合いは縦横それぞれ半分に解像度を減らして記録します。画像を8×8ピクセルの小領域に分割してそれぞれに離散コサイン変換をかけて周波数領域にデータを移し、高周波数のデータを減らす処理も行われます。動画データはそれらに加えて、前後の画像との類似部分を省略する方法がとられます。音声データは、人間の聴覚の特性上、認識されづらい音を省略するような方法などが用いられます。
データ構造
データ構造とデータ構造を操作するときの計算量について考えます。入力データ量に対してどれくらいの計算時間がかかるかの尺度を考えます。必要なメモリ量を空間計算量といい、計算時間を時間計算量といいます。時間計算量の場合、実際に計算にかかる時間ではなく、ジョリに必要な計算の回数であるステップ数を表します。

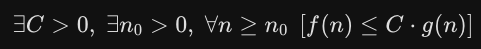
配列において新しい要素をi番目に追加する場合の計算量は平均的にO(n)です。削除も同様です。ある値に一致するものがあるかの検索も同様です。最大値や最大値の取得も同様です。配列は単純な構造を持つが複雑な操作には向きません。追加や削除や探索が発生しにくいデータに使われます。行列やベクトルなどの数学的対象のデータを保持するのに使われることが多いです。
リストは要素と次の要素のメモリアドレス(ポインタ)の組からなるデータ構造です。一番最後の要素には最後の要素のポインタは0番地を指すポインタ(ヌルポインタ)にすると決まっています。そのため探索や最大値・最小値の取得の計算量はO(n)で配列と変わりません。要素の追加や削除は配列より高速になります。つまりO(1)です。
| 特徴 | 二分木 | 二分探索木 |
| 子の数 | 最大2個 | 最大2個 |
| 値の順序 | 指定なし(バラバラでOK) | 左 < 親 < 右 の順 |
| 主な用途 | 数式の表現、ヒープ構造など | データの検索、挿入、削除 |
| 検索効率 | 端から探す必要がある | 半分ずつ絞り込める(高速) |
2分探索木は探索を高速で行えるデータ構造です。大小比較が可能なデータを考えます。比較回数は平均で約log2(n)回で計算量はO(logn)です。これを2分探索といいます。要素を追加・削除するときは配列と同じくO(n)の計算量が必要になります。木構造はエッジで結ばれたノードの間に親子関係があり、それぞれのノードには最大1つの親ノードがあるとします。親がないノードは1つだけでこれが根ノードです。子を持たないノードを葉といいます。
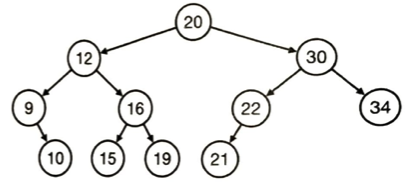
バランスが良い木が平衡2分探索木(平衡2進木)であり探索も挿入も削除も最大値や最小値の取得も計算量はO(logn)です。ソートなどの目的で最大値を求めることに特化したデータ構造はヒープです。大抵2分木(2分木は「子は2個まで」という形状の制約のみです。2分探索木は、これに加えて値の並び方の順のルールが追加されたものです)ですがヒープは2分探索木と違って親ノードの要素の値はどの子ノードの要素の値より大きいです。
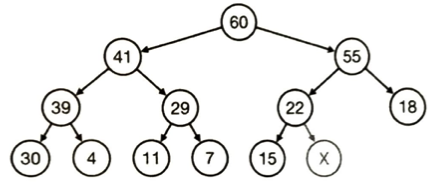
この構造なら最大値は計算量O(1)です。

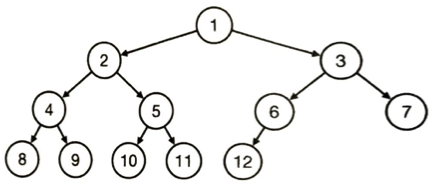
以下では今までのオーダーのまとめです。リストについては以下の点に注意します。この表ではリストにおいては悪い状況(2.)で考えています。

| データ構造 | 操作 | 平均オーダー | 最悪オーダー | 最速(最良)オーダー | 補足・備考 |
| 配列 | 追加・削除 | O(N) | O(N) | O(1) | 途中の挿入・削除は要素のずらしが発生するため O(N)。末尾の追加・削除なら最速 O(1)。 |
| 最大・最小取得 | O(N) | O(N) | O(1) | ソートされていない場合、全探索が必要。運よく先頭にあれば O(1)。 | |
| リスト | 追加・削除 | O(N) | O(N) | O(1) | ポインタの繋ぎ替え自体は O(1) ですが、その場所を特定する(探す)のに平均・最悪で O(N) かかります。先頭/末尾への追加なら O(1)。 |
| 最大・最小取得 | O(N) | O(N) | O(1) | 配列同様、全探索が必要です。 | |
| 二分木 (普通の木) | 追加・削除 | O(N) | O(N) | O(1) | 構造に規則がないため、挿入場所や削除対象を探すのに全探索( O(N) )が必要です。 |
| 最大・最小取得 | O(N) | O(N) | O(1) | どこに何があるか分からないため、すべて探す必要があります。 | |
| 2分探索木 (BST) | 追加・削除 | O(log N) | O(N) | O(1) | 最悪ケースに注意。 データが昇順などで偏って登録されると、一本道のリスト状態(斜行木)になり O(N) に悪化します。 |
| 最大・最小取得 | O(log N) | O(N) | O(1) | 左の果て(最小)、右の果て(最大)をたどるだけですが、木が偏っていると最悪 O(N) です。 | |
| 平衡2分探索木 (AVL, 赤黒木) | 追加・削除 | O(log N) | O(log N) | O(1) | データの偏りを自動で修正(回転)するため、最悪の場合でも必ず O(log N) をキープします。 |
| 最大・最小取得 | O(log N) | O(log N) | O(1) | 木の高さが常に log N 程度に保たれるため、最悪でも高速です。 | |
| ヒープ (二分ヒープ) | 追加・削除 | O(log N) | O(log N) | O(1) | 追加時は最下層から上へ、削除時はルートから下へ並べ替える(ヒープ再構築)ため、常に木の高さ分( log N )に収まります。 |
| 最大・最小取得 | O(1) | O(1) | O(1) | ヒープ最大の強み。 根(ルート)に必ず最大値(または最小値)が君臨しているため、常に O(1) で取得できます。 |

ハッシュ値の例題について考えます


データベース
リレーショナルモデル
データベースは、ある目的に従ってデータを利用しやすい形で整理、蓄積、管理を行う機能を提供します。意思決定の支援を目的とした大規模なデータベースであるデータウェアハウスは、データの蓄積とともにデータの分析の機能を提供します。データモデルはデータの構造やデータ間の関係を表現する枠組みを与えます。
決定すべきモデルの構造をスキーマといいます。リレーショナルモデルのスキーマの決定は、概念設計、論理設計、物理設計の順に行われます。概念設計ではE-Rモデルを用います。E-Rモデルはデータ間の関係を図式化したものです。図にしたものをE-R図といいます。
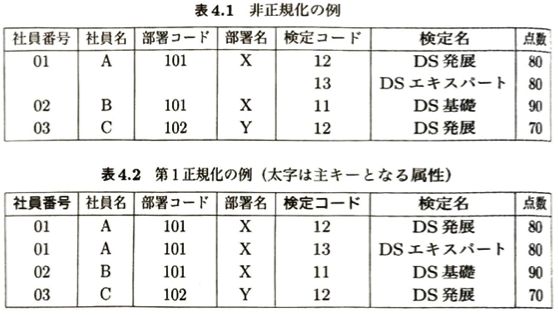
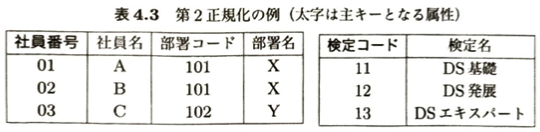
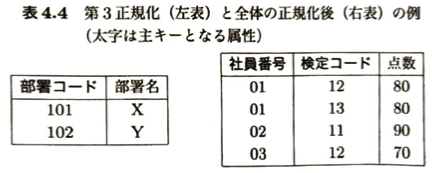
結合とは、2つのテーブルについて、共通する属性でそれらを関連づける関係演算です。ユーザがDBMS(データベース管理システム)を介して実際にデータベースを操作するためのデータベース言語としてSQL(Structured Query Language)があります。データ定義言語(DDL)、データ操作言語(DML)、データ制御言語(DCL)があります。




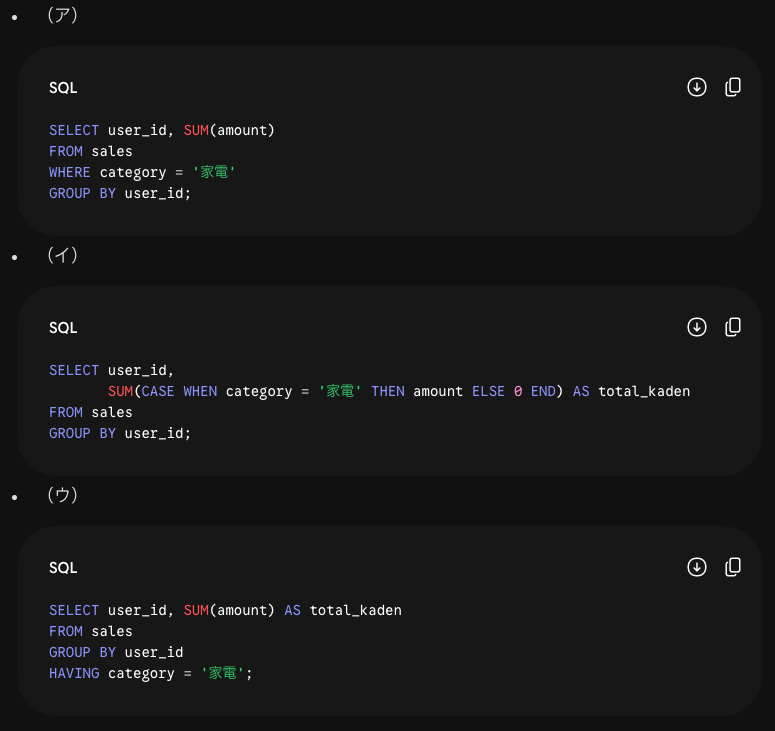
SQLについての例題を考えます


Window関数についての例題を考えます

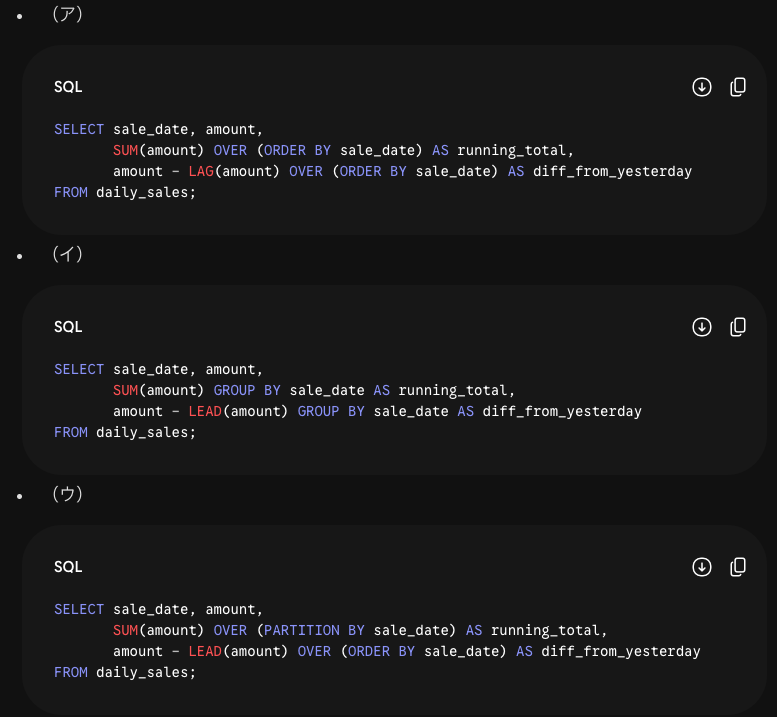


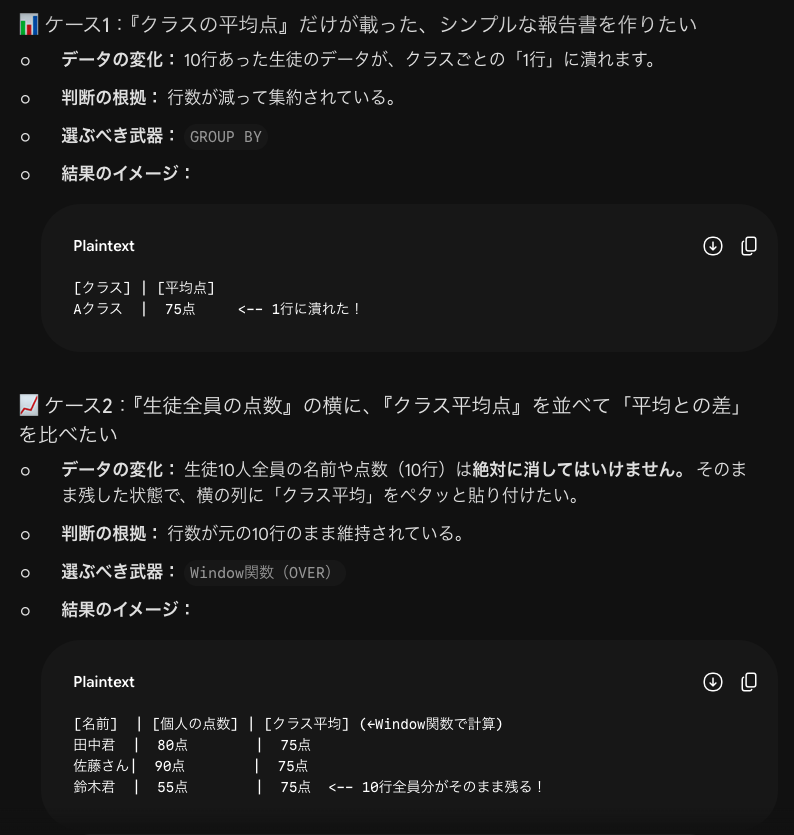
| 判断の根拠となる問い | GROUP BY | Window関数(OVER) |
| 処理後の「行数」はどうなる? | ギュッと減る(集約される) | 1行も減らない(元のまま) |
| 元データの「個人の情報」は残る? | 消える(グループの平均や合計しか見えなくなる) | 残る(個人の値の横に、全体の平均などが並ぶ) |
| 構文としての目印は? | クエリの最後に GROUP BY 列名 がある | 各集計関数の後ろに OVER (...) がある |
アルゴリズムとプログラミング
アリゴリズム
ソートアルゴリズムは比較によるソートと比較によらないソートとで大別されます。比較によらないソートとは、桁ごとにバケツソートを行う手法はRadixソートといわれます。しかしこれでは応用が効きません。比較によるソートは必要に応じて要素間の前後関係を判定して、その通りに並び替えていく汎用性の高い手法です。

比較によるソートアルゴリズムの性能は、安定なソートか不安定なソートか、時間計算量、内部ソートか外部ソートかで比較されます。
安定か不安定かについて以下のような例で説明します。
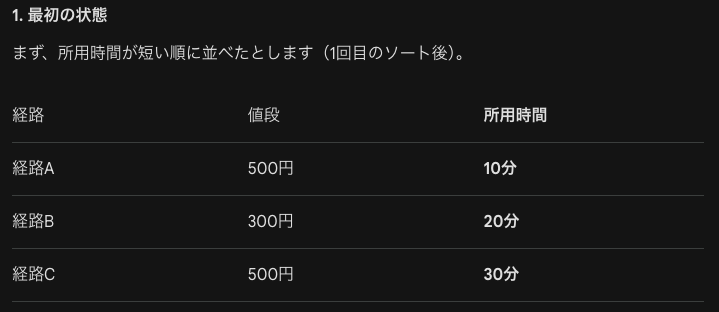

| 種類 | 順序の維持 | メリット | デメリット |
| 安定なソート | 維持される | 複数の条件で並べたい時に便利 | 計算の手間が増えることがある |
| 不安定なソート | 入れ替わる可能性あり | なりふり構わず並べるため、時間計算量が少ない傾向にある | 1回目のソート結果を壊してしまう |
計算量についてはn個の要素に対して時間計算量O(nlogn)未満のアルゴリズムは存在しないことが証明されています。
そのため基本的には時間計算量O(nlogn)のアルゴリズムが採用されています。
内部ソートと外部ソートの違いは、主に対象の配列の中身を直接入れ替えのみでソート可能か、それ以外に追加のメモリを必要とするかです。追加でO(n)程度の量のメモリを追加しないと処理できないソートを外部ソートといいます。




| 項目 | 覚え方のフレーズ |
| 計算量 | 原始的(挿入・バブル)は遅い(n^2)。工夫したやつは速い(nlogn)。 |
| 安定性 | 「急に(Quick)冷えて(Heap)不安定」。残りは安定。 |
| 領域 | 合流させる(マージ)のは「外」から持ってくるから外部。 |
O(nlogn)の安定な内部ソートである実用的なアルゴリズムは発見されていません。
安定を優先するか内部ソートを優先するか内部ソートを優先するかのトレードオフになりますね!
アルゴリズムの途中でそのアルゴリズム自体を再利用するようなアルゴリズムを再帰的アルゴリズムといいます。
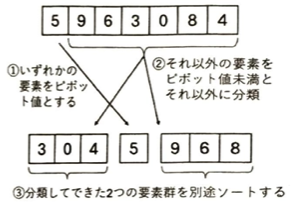
| 項目 | 内容・特徴 | 詳細解説 |
| アルゴリズムの核心 | 「分割」と「再帰」 | 配列をピボット(基準値)をもとに分割し、再帰的に処理を繰り返す。 |
| 処理の4つのパート | 分類の境界をずらす | 「ピボット未満」「ピボット値」「未処理」「ピボット以上」の4つに分けて管理する。 |
| 高速な理由1 | 再帰回数が O(logn) | 配列をだいたい半分に分けていくため、少ない再帰回数で終了する。 |
| 高速な理由2 | 実装の単純さ | 余分な処理が非常に少なく単純なため、他の O(n log n) 級より高速に動く。 |
| 平均時間計算量 | O(n log n) | ほとんどの場合、非常に早いソートアルゴリズムとして機能する。 |
| 最悪時間計算量 | O(n^2) | ピボット選択が不適切な場合(例:ソート済み配列で端を選ぶなど)に発生する。 |
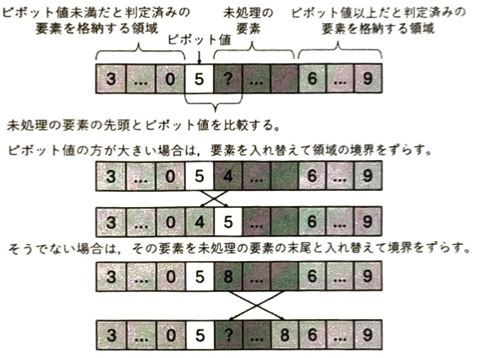
2分ヒープは木構造の一種ですが、要素数に応じて木の構造が一意に決まるので、木の構造をデータとして記憶する必要がないメリットがあります。
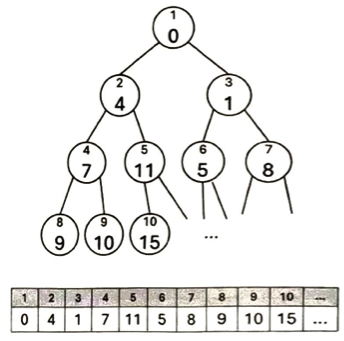
マージソートにおいて次のような図を考えます。
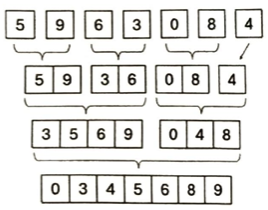
例えば最上段は要素数nの配列は、要素数1の山がn個あると考えます。
グラフ関連のアルゴリズムを考えます。辺の重さを距離と見なしたときの、2つのノードの最短距離を求める経路探索を考えます。ダイクストラ法を考えます。




これらのように部分問題の解を見つけ、それらの解を元に別の部分問題の解を見つけ…を繰り返していくことで最終的な解を見つけるアルゴリズムの設計方針は、動的計画法とよばれます。特徴は、部分問題の解は1回求めた後、上手く記録して使いまわすことが重要で、それにより無駄な計算を省いて解を高速に求めることができます。ダイクストラ法は、採れる選択肢を増やすことを優先して探索するので、幅優先探索という手法の1つです。逆に選択肢を見つけたるような場合は、先に深堀りし尽くすような手法を深さ優先探索といいます。無駄なやり直しが多数発生するので幅優先探索よりも遅くなりますが、なんでも良いので経路を1つ見つける場合には有用です。チェスなどのゲームの流れを表現したゲーム木の探索など、そもそも完全な探索が不可能なほどに大きい木の探索にも応用できます。
グラフの別の応用としてはフローネットワークがあります。グラフの辺の重みを、その辺を通せる流量や容量と見なす応用です。このような最大量を求める問題は、最大フロー問題といわれます。他の問題を最大フロー問題に帰着させることも可能です。
| 分類 | 手法名 | 仕組み・特徴 | 具体例・補足 |
| 組合せ最適化 | 貪欲法 | とりあえず現状で最もよい解を選んでいく。必ずしも最適解が得られるとは限らない。 | ダイクストラ法(最適解が得られる例)、巡回セールスマン問題、ナップサック問題 |
| 局所探索 | 仮の解をベースに、少しだけ異なる「近傍解」を生成し、改善されれば更新する。 | 焼きなまし法、タブーサーチ | |
| 関数 f(x) の最小化 | 最急降下法(勾配降下法) | 関数の傾き(勾配)を利用して最小値を探す。微分可能な場合に有効。 | 機械学習の学習アルゴリズムなどで多用 |
| 座標降下法 | ベクトルの要素を一つ選び、増減させて値が小さくなる方へ更新する。微分不可能でも使える。 | シンプルな反復更新アルゴリズム |

プログラミング
構造化プログラミングとは、プログラムの構造に制約を加えてプログラムを理解しやすくする方法です。「次にどの行がどの順番で実行されるのか?」を条件分岐や繰り返し処理などで構成する手法です。Python、C、Java言語などのプログラミング言語は多くはこの考え方を採用しています。制約がない場合は、機械語や一部のプログラミング言語にあるgoto命令という「次にどの行、どの命令を実行するのか?」を指示できる仕組みがあります。これを「ジャンプしない場合は次の命令を実行する」、「条件を満たした場合のみジャンプ」というように使うことで、どんなプログラムも記述できます。

しかしジャンプは、理解や修正が困難なプログラミングになりがちです。そのためジャンプ命令を使わずにプログラミングを行えるプログラミング言語が登場し、その手法は構造化プログラミングと呼ばれるようになりました。
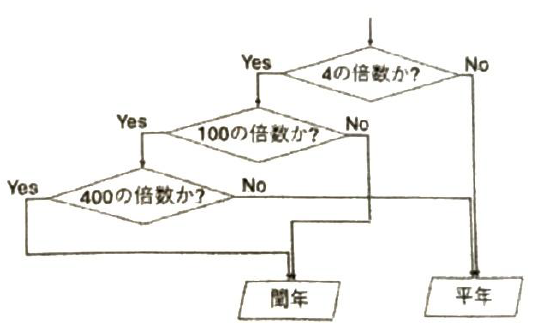

ジャンプを用いないPython表記だと次のようになります。

このようにそのままでは書けない構造が存在するデメリットより、人間が見て把握しやすいプログラムになっているメリットの方が大きく勝るため、現在では構造化プログラミングは基本的な手法として広く採用されています。ジャンプ命令を用いるものや構造化プログラミングを含む、プログラムが上から下へと1行ずつ順に実行されることを基本とする手法は、手続き型プログラミングとよばれます。これ以外にも関数型プログラミング(何らかの計算内容を示した関数を定義し、それらの組み合わせで目的を果たすプログラミングを行います)や論理プログラミング(決められた書式で命令を記述しておき、その解をコンピュータに探索させる手法です)といった手法も存在します。関数プログラミングでは、実行ごとに結果が異なる関数は避けられます。そのため複数のCPUやコンピュータに処理を割り振って並列に計算することが容易にできる利点があります。LISP、Haskell、F#言語などです。論理プログラミングではProlog言語が著名です。人工知能やエキスパートシステムの実装で用いられました。
モジュール化について考えます。プログラムを再利用しやすい単位に分割して実装する方法です。


| 項目 | 内容・仕組み | メリット / 注意点 |
| モジュール化 | ソースコードを機能単位で分割して書く手法。別のプログラムから import して利用する。 | 機能の再利用がスムーズになり、コピー&ペーストによるバグ修正の混乱を防げる。 |
| ライブラリ / パッケージ | モジュールをさらにまとめたもの。有償・無償で公開されており、一から書く手間を省ける。 | Pandas が NumPy を利用しているように、ライブラリ同士が依存し合っている場合がある。 |
| リポジトリ | インターネット上にライブラリを集めて保管している場所。 | 公開者はリポジトリに登録し、利用者はそこから探してインストールする。 |
| パッケージ管理システム | ライブラリの導入・更新を一元化するソフト(Pythonの pip など)。 | 依存関係にある別のライブラリも自動的にすべてインストールしてくれる。 |


リファクタリングについて考えます。
| 項目 | 内容 |
| 定義 | ソフトウェアの外側の動作は変えずに、内部構造を整理すること。 |
| 主な作業内容 | ・モジュール化などによる重複の排除。 ・変数や関数の命名規則の統一。 ・ソースコードの整理・構造化。 |
| 実施するメリット | ・コードが整理され、バグの温床を防げる。 ・機能追加時の影響範囲が見極めやすくなる。 ・長期的な維持コスト(メンテナンスコスト)を抑えられる。 |
| よくある誤解 | 「機能が増えないからコストだけかかる無駄な作業」と敬遠されることがある。 |


最後にオブジェクト指向について考えます。
| 用語 | 意味・役割 | 具体的なイメージ(画像より) |
| オブジェクト指向 | オブジェクトと呼ばれる仮想的なものを組み合わせてソフトウェアを構成する設計方針 | GUIアプリでウィンドウ、ボタン、ラベルなどを組み合わせて画面を作るイメージ |
| クラス | オブジェクトの「ひな形(設計図)」をプログラミング言語で書いたもの | windowクラス、randomクラスなど |
| オブジェクト | クラスをもとに生成された実体。実行時に必要に応じて作られ、互いに影響しあって動作する | windowオブジェクト、buttonオブジェクト、ユーザオブジェクト |
| メソッド(操作) | オブジェクトに対する命令 | windowオブジェクトに対して「show」と命じると画面に表示される |


データサイエンスエキスパートの合格記事は下記です!


{kind=link}