
2026年6月8日にデータサイエンスエキスパート試験を受けて合格しました!
DSエキスパートの勉強方法は公式テキスト『データサイエンスエキスパート演習』を周回するだけで合格することは可能です。ただし本書は1章の重みがとてもあり、1ページの中でも行間が広いものも散見されます。そこで僕が勉強をしながら行間を埋めたり具体的な例題を探して解いたものもまとめて各章ごとの公式テキストの内容を消化していきたいと思います。
本記事は第5章の内容ですが、範囲が広すぎるので2記事に分けます。本記事はその前編です。

モデリング・AIによる課題解決
AIの歴史と応用分野
AIは「人間のように知的な振る舞いをする機械」を実現することを目的とした科学技術の総称です。
| 時代 | 出来事・ブーム | 主な内容・キーワード | 課題と限界 |
| 1950年代 | 黎明期 | ・アラン・チューリングが「チューリング・テスト」を提案。 ・1956年「ダートマス会議」で「人工知能」という用語が誕生。 | - |
| 1950年代後半〜1960年代 | 第1次ブーム | 「推論と探索」の時代。論理的な推論に重点。 ・トイプロブレム(パズルやチェスなど)を解く。 | 実社会の複雑な問題が解けない。 |
| 1970年代〜1980年代 | 第2次ブーム | 「知識」の時代。エキスパートシステムの開発が盛んに。 ・医療診断「MYCIN」、化合物探索「DENDRAL」など。 | 知識の収集と整理に膨大な手間がかかり、柔軟性にも欠ける。 |
| 2010年以降 | 第3次ブーム | 「機械学習・深層学習」の時代。 ・ディープラーニング(深層学習)の登場。 ・2012年 ILSVRCで画像認識精度が飛躍。 | - |
| 2022年以降 | 現在 | 生成AIを用いた対話システムが大きく発展。 | - |

.jpg)
| 分類項目 | 種類 | 特徴・詳細 | 具体例 |
| 範囲による分類 | 汎用AI (AGI) | 人間のように幅広いタスクをこなし、未知の状況にも柔軟に対応できる知能。 | 現在の技術では未存在(研究段階) |
| 特化型AI (Narrow AI) | 限定された領域で高い能力を発揮する。他の課題には対応できない。 | 画像分類、音声認識、AlphaGo | |
| 性質による分類 | 強いAI | 感情や意識を持ち、人間と同じように自律的な意思決定が可能なAI。 | SF映画に登場するような知能 |
| 弱いAI | プログラムされた目的やデータに基づき動作する。本質的な「理解」はない。 | 現在主流のAI技術 |
| 課題名 | 内容 | 具体的な例 |
| フレーム問題 | 行動に関係のない事柄を、いかに効率的に「関係ない」と判断して無視するかという問題。 | ロボットがコーヒーを淹れる際、照明の状態など無関係な要素まで考慮してしまう。 |
| シンボルグラウンディング問題 | AIが扱う言葉(記号)が、実世界の意味と結びついているか(接地しているか)という問題。 | 「犬」という単語を知っていても、実際の犬を見た体験から理解しているわけではない。 |

| 分野 | 主な活用シーン・技術 | 導入のメリット・効果 |
| 流通 | ・商品の需要予測、在庫管理 ・配送ルートの最適化 ・売れ筋商品の自動分析や棚配置 | ・売上向上と廃棄ロス削減の実現 |
| 製造 | ・スマートファクトリーの中核技術 ・異常検知や故障予測 ・ロボット連携による多品種少量生産 | ・無駄のない高品質な生産 ・柔軟な生産体制の構築 |
| 金融 | ・信用スコアリング、融資審査 ・株式取引の自動化、不正取引検出 ・チャットボットによる24時間顧客対応 | ・公平で透明性の高い評価 ・サービス提供の効率化 |
| インフラ・公共 | ・交通制御システム、スマートグリッド ・監視カメラ連携による防犯・災害対策 ・行政文書の分類や申請書類の審査 | ・公共サービスの業務効率化 ・社会の安全性向上 |
| ヘルスケア | ・医用画像の診断支援(画像診断) ・個別化医療、高齢者の見守り支援 | ・専門医と同等以上の診断精度 ・質の高い医療サービスの提供 |

モデル作成とデータ分析の進め方
PPDACサイクルやCRISP-DM(Cross-Industry Standard Process for Data Mining)があります。これはビジネス理解→データ理解→データ準備→モデリング→評価→展開と進んでで元に戻るものです。
覚え方は「ビデデモヒテ」です
分析目的の設定は最初に何を知りたいのか、課題は何か、を明確に言語化することが成功の鍵です。分析によって得たい成果KPIなどの指標を定義します。分析目的の設定は、具体的で計測可能なもので、定量的な表現ができることが望ましいです。それにより、必要なデータの種類や最適な分析手法の選定、正解の評価基準が定まりやすくなります。これにより、以降のプロセスを効率的に進めることができます。

パターン発見とは、データの中から有用な規則性や一貫した傾向、繰り返し現れる組合わせなどを見出すことを指します。明確な仮説を立てる前にデータ主導で知見を得ることを目的として実行されます。
発見されたパターンはあくまでデータ上の事実であり、それが意味するところや因果関係があるかどうかは追加の検証が必要です。
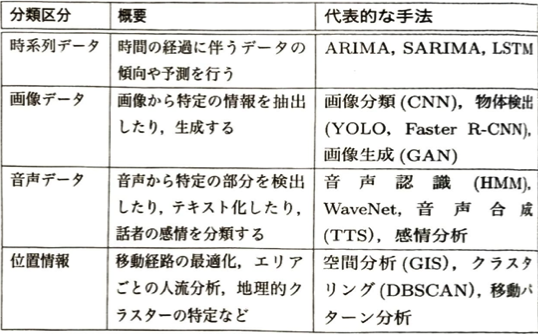

アソシエーション分析(バスケット分析)について考えます。
| 項目 | 内容 |
| 概要 | 購買データから「一緒に購入されやすい商品」の組合せ(アソシエーションルール)を発見する手法。 |
| 別名 | バスケット分析。 |
| 主なアルゴリズム | Aprioriアルゴリズム、FP-growthなど(効率的に頻出アイテムセットを抽出する)。 |
| 応用例 | ・小売・EC(併売商品の特定) ・医療データ(症状や遺伝子の共起パターン) ・Webアクセスログ(連続閲覧ページの抽出) |
アソシエーションルールの評価に用いられる指標は以下です。
| 指標名 | 意味 | 定義式(計算方法) |
| 信頼度 (Confidence) | Xを購入した人のうち、Yも購入した人の割合。 | (XとYの同時購入回数) / (Xの購入回数) |
| 支持度 (Support) | 全データのうち、XとYをセットで購入した人の割合。 | (XとYの同時購入回数) / (総購入回数) |
| リフト値 (Lift) | Xを買うことが、Yの購入確率をどれだけ高めるか。 | 信頼度(X→Y)/(Yの購入確率) |

.jpg)
モデルの作成と検証プロセスの流れです。
| 工程 | 主な内容 | 目的・詳細 |
| 作成 (構築) | ・予測モデルや分類モデルを構築する。 ・説明変数や特徴量のデータを作成・選択する。 | 目的とする現象を数式やアルゴリズムで表現する。 |
| 検証 (評価) | ・モデルの性能や汎化能力を確認する。 ・アプローチ設計時に定めた手法でパフォーマンスを検証する。 | 未知のデータに対しても正しく動作するかを見極める。 |
| 再調整 | ・必要に応じて説明変数の再選択を行う。 ・パラメータのチューニングを行う。 | 検証結果をもとに、より精度の高いモデルへ改善する。 |

以下はモデル化のプロセスです。
| フェーズ | 主な作業内容 | ポイント |
| 1. 要因の洗い出し | ドメイン知識を活かし、要因となる事柄を仮説として抽出する。 | 数式やアルゴリズムを用いて表現する。 |
| 2. モデルの作成 | 分析目的に応じた手法(予測、分類、回帰など)を選択し、学習用データで構築する。 | 特徴量エンジニアリング(変数の選択・加工)やハイパーパラメータの調整を含む。 |
| 3. モデルの検証 | 教師あり学習では精度の検証、教師なし学習ではデータの要約や意味合いの導出を検証する。 | データセットを学習用とテスト用に分割し、未知のデータへの性能を確認する。 |
| 4. 運用・評価 | 運用開始後も、予測値と実測値を定期的に比較する。 | バリデーションプロセスを継続的に行う必要がある。 |
モデルの種類別の評価指標です。
| モデルの種類 | 代表的な評価指標 |
| 分類モデル | 正解率、適合率、再現率、F1値、ROC、AUCなど |
| 回帰モデル | 平均二乗誤差 (MSE)、平均絶対対誤誤差 (MAE)、決定係数 (R^2) など |

モデルの解釈と有効性について考えます。
| 項目 | モデルの解釈性 (Interpretability) | モデルの有効性 (Effectiveness) |
| 定義 | モデルがどのように予測・判断しているか、人間が理解できる形で説明すること | モデルが実際に目的達成や業務改善に役立つかどうかを評価すること |
| 重視される背景 | 金融や医療など説明責任が重い分野、バイアスや不公平な判断(差別的予測)の検証 | 精度指標だけでなく、社会・業務への適用効果やビジネス上の成果を確認するため |
| 具体的な手法・観点 | ・回帰係数、t値の確認 ・決定木の分岐ルール ・SHAP、LIME、特徴量重要度 ・部分依存プロット | ・業務KPIの改善度合い ・コスト削減、利益増加への貢献 ・実際の運用時における効果検証 |
| 特徴 | LIME(即席のハメ込み) | SHAP(厳密な山分け) |
| 数理の正体 | データの周りに砂を撒いて、即席の直線(線形モデル)で部分近似する | ゲーム理論の「シャープレイ値」で貢献度を厳密に計算する |
| 説明の範囲 | 局所的(目の前の1件)のみ | 局所的 + 集計して大局的(全体)もOK |
| 再現性 | 砂の撒き方がランダムなので、結果がブレる | 数式が厳密なので、結果は一意に決まる |
| 計算速度 | 周辺だけを見るので圧倒的に早い | 組み合わせを網羅するので激重(※TreeSHAP等の高速化工夫が必要) |

標本調査には標本誤差が不可避です。標本誤差は、標本が母集団の縮図であっても、あくまで一部であるために生じる誤差です。標本サイズが大きいと小さくなるが、完全には排除できません。無作為性が確保されていない標本(インターネット調査のような志願型調査)では、推定にバイアスが入りやすく分析結果の妥当性に注意が必要です。
サンプルサイズの設計について考えます。
| 項目 | 特徴・詳細 | 影響と注意点 |
| 設計の目的 | 調査の「精度」と「効率」のバランスを最適化すること | nが小さすぎると、推定結果のばらつきが大きくなり信頼性が低下する |
| nが大きすぎると、時間やコストが無駄になる | ||
| 考慮すべき3要素 | 1. 許容誤差 (w/ 誤差限界) 2. 信頼係数 (1-α) 3. 母集団の標準偏差 (σ) または割合 (p) | これらの要素を調査目的に応じて計算・設定することが求められる |
| 統計的検定での役割 | 特定の対立仮説のもとでの検出力を一定以上にするために設計される | 信頼区間の幅を短くする目的とは別の観点で使われる |


それぞれのnについての条件の導出法を教えてください!
わかりました。順に追っていきます





ランダム化比較試験を考えます。
| 項目 | 内容 |
| 正式名称 | ランダム化比較試験 (Randomized Controlled Trial, RCT) |
| 目的 | 介入や処置の因果効果を科学的に評価すること |
| 基本手法 | 対象者を無作為に「介入群」と「対照群」に割り当て、結果を比較する |
| 核心となる考え方 | 反事実 (counterfactual):もし介入がなかったらどうなっていたかを想定する |
| 最大のメリット | 交絡 (confounding) の影響を最小限に抑え、純粋な介入効果を推定できる |
| 実施手順 | 1. 対象者の選定 2. 無作為な群分け 3. 介入の実施 4. 結果の観察・比較 |
| 活用分野 | 医療、教育、経済政策など |

実験計画法について考えます。まずはフィッシャーの3原則からです。
| 原則 | 英語 | 内容・目的 |
| 反復 | Replication | 同じ条件で複数回実験すること。実験誤差を推定し、結果のばらつきを評価する。 |
| 無作為化 | Randomization | 割り当てをランダムに行うこと。未知の交絡因子の影響を平均化する。 |
| 局所管理 | Blocking | 実験単位を似た性質のブロックに分けること。外的要因の影響を抑え、精度を高める。 |
次に代表的な実験計画法について整理します。
| 手法 | 特徴・使いどころ | メリット・目的 |
| 完全無作為化実験 | 最も基本的な方法。対象を無作為に各処理群へ割り当てる。 | シンプルに処理間の効果を比較できる。 |
| ランダム化ブロック計画 | 対象間にばらつきがある場合、ブロック(例:同じ気候条件)に分けて管理する。 | ばらつきをブロック要因として制御し、処理効果をより正確に評価できる。 |
| 直交配列(田口メソッド) | 要因数が多く、全組み合わせの実施が困難な場合に用いる。 | 最小限の実験回数で効率的に効果を抽出できる(田口メソッドとも呼ばれる)。 |
| 反応曲面法 | 非線形な応答の関係を探る手法。 | より精密な推定や、最適条件の探索を行う。 |
実験計画法の概要についてまとめます。

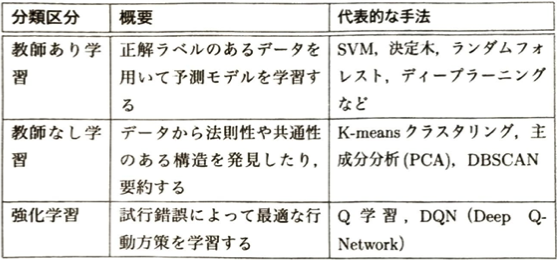
教師あり学習
線形回帰分析
ε_iはそれぞれ独立で平均は0とします。


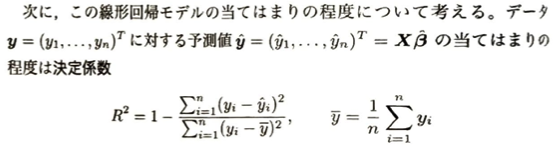
決定係数はyの推定値の当てはまりを評価しているだけで、線形回帰モデルの式が適切かを評価しているのではありません。
決定係数では使っている説明変数のうちどれが不要かを評価できません。モデル自体を評価したい場合は、決定係数でなく自由度調整済み決定係数を用いるべきです。
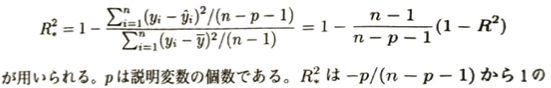

自由度調整済み決定係数と決定係数の関係式がわかりません!
了解です。解説します


次にStepwise法という自由度調整済み決定係数を用いて適切なモデルを選ぶ方法について考えます。
| 項目 | 内容 |
| 背景・目的 | 変数がp個ある場合、全パターン(2^p通り)を比較するのは膨大で困難なため、現実的な試行回数で最適なモデルを探す。 |
| 判断基準 | 自由度調整済み決定係数 (R^2*) が最大になるものを選ぶ(AICやBICが使われることもある)。 |
| 主な手法 | 変数増減法(変数を1つずつ加える)、変数減増法(変数を1つずつ減らす)など。 |
| ステップ | 操作内容 | 次のアクション |
| 1. スタート | 変数なし vs 変数1つの各パターンを比較。 | 最適な変数があれば採用し、ステップ2へ。 |
| 2. 変数の追加 | 現在のモデルに、新しい変数を1つ加えたパターンを比較。 | 追加して R^2* が上がるなら採用し、ステップ3へ。上がらないなら終了。 |
| 3. 変数の削除 | 変数を追加した後、既存の変数を1つ除いたパターンと比較。 | 除いて R^2*が上がるなら削除する。その後、再びステップ2に戻る。 |
| メリット | 注意点 |
| 調べるパターン数が 2^p個よりはるかに少なくて済む。 | ここで選ばれた「最適」なモデルは、必ずしも全パターンの中の絶対的な最適解と一致するとは限らない。 |
AICを判断基準に用いてstepwise法の具体的な問題を見てみましょう




次にいよいよ回帰係数の有意性検定へと移ります。


分散の推定量の行列表現がわからないので教えてください。
了解です。次の説明をご覧ください


途中の行列の対称行列かつべき等行列であることの証明をお願いします!
了解しました。


T統計量がt分布に従うことを計算式で教えてください
了解です。これはt分布の定義に沿って考えます


回帰分析の諸仮説の妥当性について考えます。今までの線形回帰分析を行う上での重要な4つの仮定を整理します。


| チェック内容(仮定) | 確認に使用する図 | 注目するポイント |
| 1. 外れ値の有無 | レバレッジ vs 標準化残差 | Cook距離が大きいデータがないか確認する。 |
| 2. 残差の無相関性 | 予測値 vs 残差 | 残差に系列的な特徴(パターン)がないか確認する。 |
| 3. 残差の等分散性 | 予測値 vs 残差 | 残差の分散が一定か、xが大きくなると分散も大きくなっていないか調べる。 |
| 4. 残差の正規性 | Q-Qプロット | 標準化残差が直線上にあるか(正規分布に従っているか)を確認する。 |
| 指標 | 定義・役割 | 外れ値の基準 |
| レバレッジ (h_{ii}) | X(X^T X)^{-1} X^Tの対角成分。各データが予測値に与える影響の強さ。 | - |
| 標準化残差 (r_i) | 残差をその標準偏差で割って無次元化したもの。 | - |
| Cook距離 (D_i) | レバレッジと標準化残差の両方を考慮した「影響力」の指標。 | 0.5を超えると外れ値の疑いが強い。 |

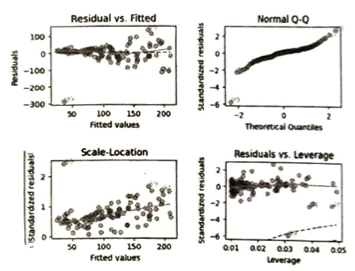
| グラフ名 | OKな状態(仮定通り) | NGな状態(仮定違反) |
| Residuals vs Fitted (残差 vs 予測値) | 点が0を中心に上下ランダムに散らばっている。 | NG1: 弓なりや波型など、特定の曲線パターンが見える(線形性が不十分)。 NG2: 右に行くほど散らばりが広がる(不等分散)。 |
| Normal Q-Q (正規Q-Qプロット) | 点が直線(45度線)上にほぼきれいに並んでいる。 | NG1: 両端が直線から大きく外れて反り返っている(裾が厚い、または薄い)。 NG2: 全体的に大きく湾曲している(分布が左右に歪んでいる)。 |
| Scale-Location (標準化残差の平方根) | 赤い線がほぼ水平で、点の散らばり幅が一定である。 | NG1: 赤い線が右肩上がり、または右肩下がりになっている(分散が予測値に依存している)。 NG2: 特定の予測値の範囲だけ極端にバラついている。 |
| Residuals vs Leverage (残差 vs レバレッジ) | 全ての点が中心付近に集まり、赤い点線(Cook距離の境界)の内側に収まっている。 | NG1: Cook距離が0.5を超える、境界線付近や外側に点が存在する(強い外れ値)。 NG2: 右端の方に独立してポツンと離れた点がある。 |

多重共線性について考えます。


回帰分析の例題について考えます


質的回帰分析
名義尺度において考えます。つまり順序を問いません。
まずロジスティック回帰の基礎概念をまとめます。つまり質的データを2値変数(0か1)を予測するための仕組みです。


| 項目 | 内容 | 役割・意味 |
| 目的変数 (Y) | 0 または 1(例:合格/不合格) | 2値のカテゴリカルデータ。 |
| 予測対象 (p) | P(Y=1) | ある事象が起こる「確率」。 |
| オッズ | p/(1-p) | 事象が起こる確率と起こらない確率の比。 |
| 対数オッズ | log({p/{1-p}) | オッズの対数をとったもの。これを回帰式で推定する。 |
| シグモイド関数 | 1/{1+exp(-x)} | 推定値を0から1の範囲(確率)に収めるための関数。 |
次は統計モデルの比較をまとめます。確率を予測するための主なモデルです。

| モデル名 | 使用する関数 | 特徴 |
| ロジスティック回帰 | ロジット関数 / シグモイド関数 | 微分が計算しやすく、最も一般的。 |
| プロビット回帰 | 標準正規分布の累積分布関数 | ロジスティックとほぼ同様の結果だが、計算がやや複雑。 |
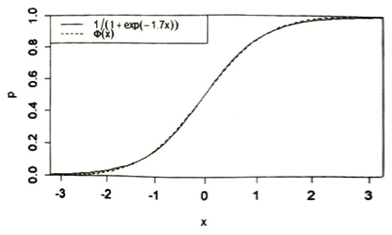
パラメータ推定と評価についてまとめます。モデルをどう作り、どう評価するかについてです。


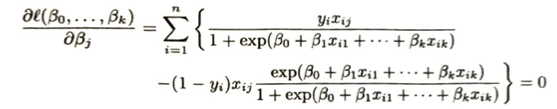
| 項目 | 内容 | 備考 |
| 推定方法 | 最尤法 (さいゆうほう) | 通常の回帰(最小二乗法)ではなく、尤度を最大化する。 |
| 解法 | ニュートン法など | 方程式を直接解けないため、数値的に近似計算する。 |
| 回帰係数 (β) | 対数オッズ比に対応 | β_1 は、変数x_1 が1増えた時の対数オッズの増分を表す。 |
| モデル評価 | 混同行列、ROC曲線 | 正解率、適合率、再現率、AUCなどで精度を測る。 |

モデル評価については次のように考えます。


多値データへの拡張について整理します。目的変数が3つ以上のカテゴリ(M個)の場合の手法です。
| 手法名 | 予測の仕組み | 応用分野 |
| 多項ロジスティック回帰 | 各カテゴリに属する確率P(Y=j)を計算し、最大となるjを予測値とする。 | 3つ以上の選択肢がある判別問題。 |
| ソフトマックス関数 | 多項ロジスティックの式を正規化したもの。 | 深層学習(ディープラーニング)の出力層の活性化関数として有名。 |

2値との違いがわからないので教えてください!
了解です。以下をご覧ください



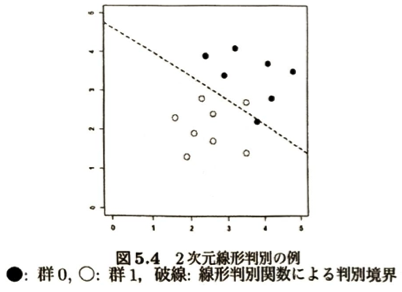
判別分析
学習データを用いて将来観測される対象がどの群に属するかを判別する手法を判別分析といいます。線形判別、2次判別、サポートベクターマシンについて考えます。





等価であることを証明してほしいです!
わかりました。こちらを見てください





次は2次判別に移ります。
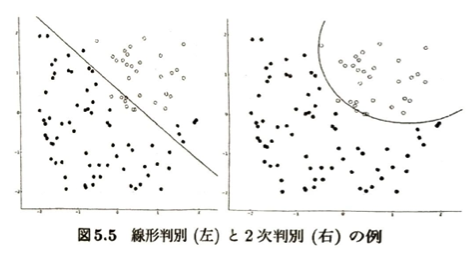
| 項目 | 線形判別 (LDA) | 2次判別 (QDA) |
| 前提条件 | 各群の分散共分散行列が等しいと仮定。 | 各群の分散共分散行列が異なると想定。 |
| 分散の扱い | 共通の分散Sを計算して使う。 | 群ごとの分散S_0, S_1をそのまま使う。 |
| 判別境界の形 | 直線(または平面) | 曲線(円、楕円、放物線など) |
| 数式上の特徴 | xの1次式になる。 | xの2次式になる。 |
| 手法 | メリット | デメリット |
| 線形判別 | 計算がシンプルで解釈しやすい。学習データが少なくても安定する。 | 分散が大きく異なるデータには対応できず、誤判別が増える。 |
| 2次判別 | 境界を曲線にできるため、複雑な分布でも誤判別を少なくできる。 | パラメータ数が多いため、データが少ないと過学習(オーバーフィッティング)しやすい。 |
次は多群判別です。
| 手法名 | 前提条件(分散の扱い) | 判別のルール |
| 多群線形判別 | すべての群の母分散共分散行列が等しいと仮定する。 | 共通の分散Sを用いて計算したマハラノビス距離が、最小となる群に分類する。 |
| 多群2次判別 | 各群の母分散共分散行列が等しいとは限らない。 | 群ごとの分散S_jを用いて計算したマハラノビス距離が、最小となる群に分類する。 |



次は正準判別になります。


さすがにこの固有値問題への帰着の証明は難易度が高すぎるので割愛しても合否に影響はでないと考えています。


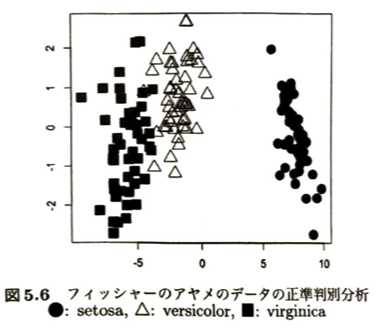

k-近傍法について考えます。
| 項目 | 内容 | 備考 |
| 分類の仕組み | 新しいデータから距離が近い k 個のデータを探し、その多数決でクラスを決める。 | 直感的で分かりやすい。 |
| 手法の性質 | ノンパラメトリック | データが特定の分布(正規分布など)に従うと仮定しない。 |
| 使用する距離 | ユークリッド距離 | いわゆる「直線距離」。 |
| ハイパーパラメータ | k (近傍データの数) | この値をいくつにするかで結果が変わる。 |
| メリット | 注意点(k の設定) |
| 複雑な数式や学習プロセスを必要とせず、簡便である。 | kが小さすぎる場合:ノイズに敏感になりすぎ、過学習(オーバーフィッティング)が起きる。 |
| データの境界が複雑な形をしていても対応できる。 | kが大きすぎる場合:境界が滑らかになりすぎて、細かい判別ができなくなる。 |
| k の設定 | 多数決の範囲 | 決定境界の形 | 予測の特性 | 統計的リスク |
| 小(k=1など) | 局所的(ミクロ) | 複雑・ギザギザ | 高バリアンス・低バイアス | 過学習(ノイズに過敏) |
| 大(k=Nなど) | 大局的(マクロ) | 単純・滑らか | 低バリアンス・高バイアス | 学習不足(大雑把すぎる) |

いよいよ分離超平面とサポートベクターマシン(SVM)に入ります。SVMの基本理念として2つのグループを分ける境界線(超平面)を、最も効率的かつ頑健に引くためのアルゴリズムです。
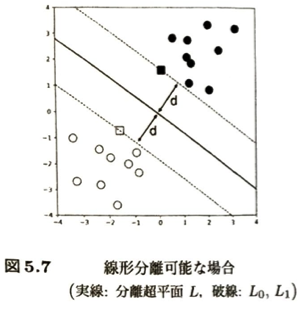
| 用語 | 意味 | 覚え方のポイント |
| 分離超平面 | グループを分ける境界線(面)。 | 2群を真っ二つに分ける「壁」。 |
| マージン (d) | 境界線から、最も近いデータまでの距離。 | 境界線とデータの間の「余白(安全地帯)」。 |
| ハードマージン | 完全に線形分離可能な場合の最大化問題。 | 余白をギリギリまで広げる考え方。 |
| サポートベクター | 境界線の決定に直接関わる、最も近いデータ。 | 境界線を支えている(サポートしている)「精鋭部隊」。 |


d=の式がわかりません。教えてください
了解です。次をご覧ください



最適化の仕組みについての数学的な流れ、つまりマージンを最大にする計算プロセスを考えます。







サポートベクターマシンの特徴について、なぜこの手法がサポートベクターマシンと呼ばれるのかの確信部分を考えます。
| 特徴 | 内容 | メリット |
| 一部のデータに依存 | 判別関数は、サポートベクター(境界ギリギリの点)のみで決まる。 | 境界から遠いデータ(その他大勢)が多少動いても、結果が変わらない。 |
| 高い汎用性 | 境界付近の「ギリギリの差」に注目する。 | 未知のデータに対しても、ミスが少ない(汎化性能が高い)。 |


SVMはかなり抽象度が高いので具体的な問題として考えてみます





ソフトマージンを用いたサポートベクターマシンについて考えます。

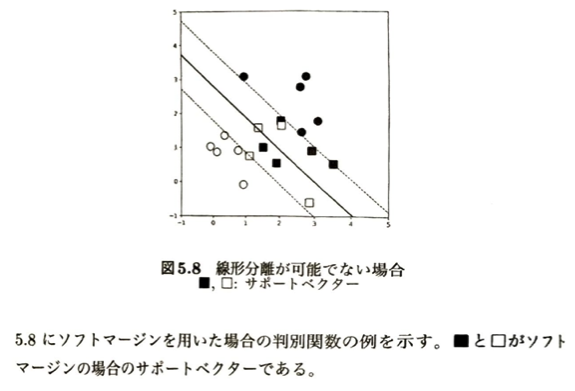
| 項目 | 内容(読みやすい形式) | 役割・意味 |
| 背景 | 線形分離不能への対応 | ノイズがある現実のデータでも分類できるようにする。 |
| スラック変数 | 境界からの「はみ出し量」 | 0なら正解エリア。プラスの値なら境界内へ侵入。 |
| マージンの定義 | ソフトマージン | 多少の「はみ出し」を許した上でのマージン(ゆとり)。 |
| 最適化の目的 | (マージン最大化) + (誤判定の最小化) | 「境界の広さ」と「分類の正確さ」を両立させる。 |
| 目的関数の意味 | 最小化: (wの2乗 / 2) + λ × (はみ出しの合計) | 前半でマージンを広げ、後半でミスを減らす。 |
| パラメータ λ | 正則化パラメータ | 誤判定をどれだけ厳しく罰するか決める「重み」。 |
| サポートベクター | 境界の条件を満たすデータ点 | 境界線の位置を決定する「支柱」となるデータ点。 |

ソフトマージンの問題もとても抽象的なので具体例を述べます




最後に非線形判別とカーネル法を学びます。

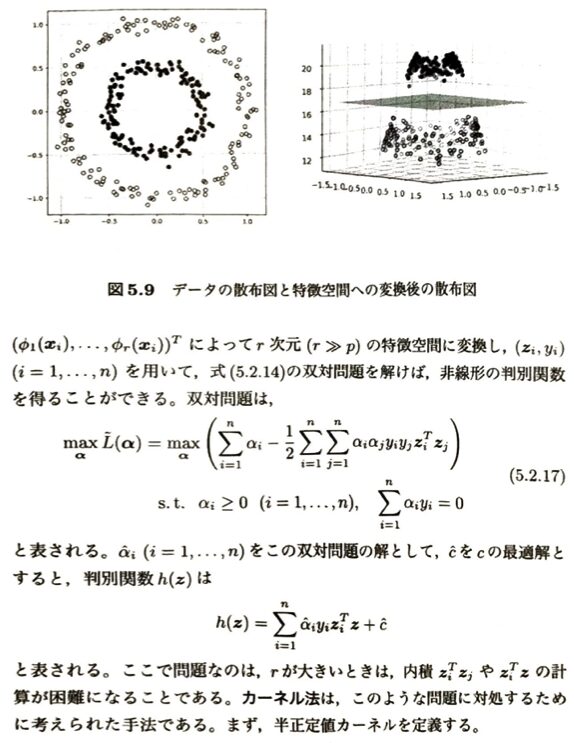






非常に抽象的で難易度が高いので具体例を考えます。


| パラメータ | 大きくすると(↑) | 境界線の形 | リスク |
| コスト C (λ) | 誤判定を「厳しく」罰する | 複雑(データに合わせすぎる) | 過学習 |
| ガウスの σ | 影響範囲を「広く」する | 滑らか(直線に近づく) | 未学習(精度不足) |
| ガウスの γ(1/(σ^2)) | 影響範囲を「狭く」する | 複雑(点に張り付く) | 過学習 |
他の問題も考えてみます




正規化法とモデル選択
| 概念 | 状態 | 特徴 | 住宅価格予測の例 |
| バイアス (Bias) | 高い = 未適合 (単純すぎる) | データの真の傾向を捉えきれていない。 モデルの柔軟性が不足している。 | すべての物件をほぼ同じ価格と予測してしまうような単純なモデル。 |
| バリアンス (Variance) | 高い = 過学習 (複雑すぎる) | 訓練データの「ブレ(取り方)」に予測値が激しく依存する。 未知のデータへの予測精度が低い。 | 訓練データの価格に完璧にフィットしているが、新しいデータでは外れるモデル。 |
| ノイズ (Noise) | 削減不可能 | データ自体に内在するランダムなばらつき。 | モデル側ではどうしようもない不可避の誤差。 |


紛らわしいので以下の場合に注意です

| 手法名 | 加えるペナルティ | 形状 | メリット(得意なこと) | デメリット(弱点) |
| リッジ回帰 (L2ノルム) | パラメータの2乗和 λ×(βのL2ノルムの2乗) | 円形 | 多重共線性(特徴量間の強い相関)に強い。 すべてのパラメータを均一に縮小し安定させる。 | パラメータが完全にゼロにはならないため、不要な特徴量を削れない。 |
| ラッソ回帰 (L1ノルム) | パラメータの絶対値の和 λ×(βのL1ノルム) | 正方形 (ひし形) | 一部のパラメータを完全にゼロにする(スパース性)。 自動で特徴量選択(次元削減)ができる。 | 高次元データや多重共線性が強い場合に、挙動にランダム性を伴い安定性が低下する。 |
| エラスティックネット | L1 と L2 の両方 λ_1×(βのL2ノルムの2乗)+λ_2×(βのL1ノルム) | ハイブリッド | 両者の上位互換的な位置づけ。 特徴量選択をしつつ、多重共線性への耐性も持つ。 | 調整すべきハイパーパラメータ(λ_1, λ_2)が2つに増える。 |
| アプローチ | 特徴量変換のやり方 | メリット | 課題・デメリット |
| 多項式回帰 (従来の手法) | [1, x, x^2, x^3, …, x^d] のように、特徴量を明示的に拡張する。 | 直感的でわかりやすい。 | 次数dや元の次元が高くなると、計算量が爆大になる。適切な次数dの選択が難しい。 |
| カーネル法 | カーネル関数を使い、高次元空間での内積を直接(暗黙的に)計算する。 | 明示的な特徴量変換が不要。 非線形関係を効率的に扱え、柔軟なモデリングが可能。 | カーネル行列の計算コストが高いため、大規模データでは計算資源が必要。 過学習対策(カーネルリッジ回帰など)が必須。 |

決定木
まず分類問題における「不純度指標」の比較を考えます。決定木がデータを分ける際、「どれくらい綺麗にクラスを分離できているか」を測る基準です。どちらも「完全に混ざっている(均等)のときに最大」になり、「1クラスだけ(純粋)のときに最小(0)」になります。
| 指標名 | 数式 | 計算の特徴 | よく使われる場面・性質 |
| ジニ不純度 (Gini Impurity) | G=1-(P_1^2+…+P_K^2) | 各クラスの確率の2乗和を1から引く。 対数logを使わないため計算が高速。 | CARTアルゴリズムや、ランダムフォレストのデフォルトとして一般的。 |
| エントロピー (Entropy) | H=-(P_1 log(p_1)+…+p_K log(p_K)) | 情報理論に基づき、乱雑さを表す。 logの計算が入るため、ジニ不純度より少し計算コストが高い。 | 分割の「情報利得(インフォメーション・ゲイン)」を厳密に最大化したい場合。 |

単一決定木の「過学習対策」ハイパーパラメータについて考えます。決定木は放っておくと訓練データに過剰に適合(過学習)してしまうため、以下のパラメータでブレーキをかけます。
| パラメータ名 | 役割 | 厳しくしすぎた場合(浅すぎる / 絞りすぎ) | 緩くしすぎた場合(深すぎる / 自由すぎ) |
| 深さ (Max Depth) | 木を何段階まで分岐させるかの最大値。 | 未適合(アンダーフィット) データの複雑な構造を捉えきれない。 | 過学習(オーバーフィット) ノイズまで学習してガタガタな境界になる。 |
| 最小サンプルサイズ (Min Samples Split/Leaf) | ノードをさらに分割するために、最低限必要なデータ数。 | 分割が途中で止まり、大雑把な予測になる。 | 細かいノイズに反応して、データ1件だけのための孤立した葉(ノード)ができる。 |
アンサンブル学習(複合手法)の徹底比較をします。
「単一の決定木は過学習しやすい」という弱点を、複数のモデルを組み合わせて克服するアプローチです。

| 手法名 | 構築のスタイル | データの選び方 | 特徴量の選び方 | メリット・強み | 代表的なアルゴリズム |
| バギング (Bagging) | 並列に作る (独立した木を同時に大量生産) | ブートストラップサンプリング (重複を許してランダム抽出) | すべての特徴量を使う | モデルのバリアンス(分散)を下げ、予測を安定させる。 | - |
| ランダムフォレスト (Random Forest) | 並列に作る (バギングの進化系) | ブートストラップサンプリング (重複を許してランダム抽出) | 毎回、特徴量もランダムに一部だけ選ぶ | 木の間の相関を減らし、多様性と頑健性(ロバストさ)が劇的に向上。特徴量の重要度も出せる。 | - |
| ブースティング (Boosting) | 直列に作る (1つ前のミスを次が修正) | 前のモデルが間違えたデータを重視するように重みを調整 | すべての特徴量を使う | 浅い木(弱学習器)を繋げることで、バイアス(偏り)を劇的に下げる。驚異的な予測性能。 | AdaBoost, 勾配ブースティング, LightGBM など |
| スタッキング (Stacking) | 階層型に組む (予測値を次の入力にする) | 通常のデータ分割(クロスバリデーション等と併用) | 異なる種類のモデル(決定木、SVM、線形など)を混ぜる | メタモデルと呼ばれる上位モデルが、異なるアルゴリズムの「いいとこ取り」をする。 | - |
ベイズ統計・モデリング
ベイズ判別手法の徹底比較を行います。データをどの群に分類するかを決める3つのアプローチの比較です。LDA,QDA,Naive Bayesです。
分散共分散行列と成分間の独立性の仮定の違いに注目します。


| 手法名 | 分散共分散行列 Σ の仮定 | 特徴量(各成分)の独立性 | 境界線の形と数式的な特徴 | メリット・デメリット |
| ベイズ的線形判別 (LDA) | 全ての群で共通 (Σ_k=Σ) | 独立とは限らない (相関を考慮する) | 直線(線形) xの2次の項xTΣ^(-1)xが引き算で相殺して消えるため、一次式になる。 | パラメータ数が少なく計算が安定しやすい。 |
| ベイズ的2次判別 (QDA) | 群ごとに異なる (Σ_k≠Σ) | 独立とは限らない (相関を考慮する) | 曲線(2次曲線) 2次の項が相殺されずに残るため、境界線が歪んだ形(楕円や双曲線など)になる。 | 表現力が高いが、データ数が少ないと分散の推定が不安定(過学習気味)になる。 |
| 単純ベイズ判別 (Naive Bayes) | 正方行列(共分散を考慮しない) | 完全に独立と仮定 (f_k(x)=f_k1(x_1)…f_kP(x_P)) | 各成分の積で表される。 | 成分ごとに1変数関数(カーネル密度推定など)を個別に適用できるため、分布の形に縛られず柔軟だが、独立性の仮定が強すぎる場合がある。 |


LDAの具体的な問題を考えます



判別関数(スコア)の数式構造について考えます。ベイズ判別では以下の判別関数δ_k(x)の値が最も大きい群にデータを分類します。
| 手法名 | 判別関数 δk(x) の数式 | 覚えるためのポイント |
| 線形判別 | δ_k(x)=xTΣ^(-1)μ_k-(1/2)μ_kΣ^(-1)μ_k+logπ_k | x が1乗の項しかありません。第一項は「マハラノビス距離」に由来する線形結合です。 |
| 2次判別 | 複雑なので下記参照 |


QDAの具体的な問題を考えます



階層ベイズの3層構造について学びます。判別分析とは異なり、データの背後にある多層的な構造をモデリングする手法です。
| 階層 | 登場する要素 | 具体的役割・数式表現 | イメージ |
| 第1層 | 観測データの生成モデル | y~f(y|θ) | 実際に目に見えるデータ yが、パラメータθに従って発生する。 |
| 第2層 | 個別パラメータの事前分布 | θ~π(θ|λ) | データのばらつきを制御するθ自体も、さらに上の基準λに従って発生する。 |
| 第3層 | ハイパーパラメータの事前分布 | λ~π(λ) | パラメータの分布をさらに統制する、最上位の基準。 |


単純ベイズ判別の問題です


教師なし学習
クラスター分析
マンハッタン距離を市街地距離とも言います。これはミンコフスキー距離でp=1の場合です。
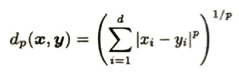
個体間の距離や類似度がわかれば個体数をnとして距離や類似度をn×n行列として表現できます。これらをそれぞれ距離行列、個体間の類似度からなる行列を類似度行列といいます。

最短距離法では1つのクラスターに各個体が1つずつ順に加わってしまう鎖構造が得られてしまいます。クラスター間の距離を直接求める方法ではありませんが、クラスターの結合方法としてクラスター内の個体の重心からの距離の平方和が最小となるようにクラスターを結合する方法をウォード法といいます。

収束は早いですが最初の点の配置がランダムなため、収束先が一意的とは限りません。そのため初期配置の設定を何度か変えて計算を行う必要があります。
| 比較項目 | 階層型クラスター法 | 非階層型クラスター法(K-means法) |
| 仕組み | 似ている個体を逐次的(段階的)に結合する。 | あらかじめ決めたグループ数に一発でドカンと分ける。 |
| 適したデータ規模 | 小・中規模(個体数が多いと計算量が増大) | 大規模データセット |
| 可視化ツール | デンドログラム(木構造の図)が使える。 | デンドログラムは作れない。 |
| クラスター数 k の決定 | 途中で結合を止めることで後から制御・調整可能。 | 事前に k をきっちり指定しておく必要がある。 |
| 結果の安定性 | 常に同じ結果になる。 | 初期配置に依存するため、結果が変わる(複数回のトライアルが必要)。 |
| 主な課題 | データが多すぎると、デンドログラムが細かすぎて見えなくなる。 | クラスター数 k の客観的な決め方がなく、試行錯誤が必要。 |
| 距離の手法 | 数式 | 特徴と使いどころ |
| 通常のユークリッド距離 | ミンコフスキー距離でp=2の場合 | 最も標準的。すべての変数を完全に平等(虚心坦懐)に扱う。データの背景知識がないとき向け。 |
| 重み付きユークリッド距離 | 上の距離で係数に主にw_iがつく | 各変数に重み w_iを付与する。「この変数は分析上、特に重要だ」というドメイン知識・背景がある場合に用いる。 |
| 注意すべきプロセス | テキストが指摘する問題点と対策 |
| クラスター数の決定 | 客観的な正解(決め方)はない。 → 多すぎると解釈不能になり、少なすぎると全然違う個体が同じグループに混ざる。自らの判断で最適なバランスを探る。 |
| 手法・設定の選択 | 「距離の選択」「計算法の選択」「クラスター数の選択」のすべてに研究者の主観が大きく依存する。 |
| 結果の解釈(最重要) | クラスター分析はあくまでデータを分けるだけの「探索的な手法」である。 →「自分の都合のいい解釈」を後付けで無理やり当てはめないよう、強く自戒すること。 |

主成分分析
まずは平均ベクトルは0としておきます。



ただし変数ごとにスケールが異なる場合は各変数を標準化して主成分分析を行います。
主成分分析の具体例を考えます



カーネル密度推定
| アプローチ | 推定手法 | データの仮定 | メリット | デメリット・課題 |
| パラメトリック | 正規分布や指数分布など | 「真の分布は〇〇分布である」と特定の形式を仮定する。 | データが少なくても、仮定が正しければ綺麗に決まる。 | 実世界の複雑なデータ(多峰性や歪んだ分布)は表現しきれない。 |
| ノンパラメトリック | ヒストグラム | 特定の分布の形を仮定しない。 | 直感的で広く知られている。柔軟。 | ビン幅や開始位置に大きく依存する。 推定された確率密度関数が不連続(カクカク)になる。 |
| ノンパラメトリック | カーネル密度推定 (KDE) | 特定の分布の形を仮定しない。 | ヒストグラムの欠点を克服し、滑らかな推定が可能。 | バンド幅hの設定に極めて敏感。 高次元で性能が落ちる。 |

| カーネル名 | 数式 K(u) | 形状の特徴 | 実務・理論での位置づけ |
| ガウスカーネル | 標準正規分布φ(u) | お馴染みの正規分布のベル型。 | 実務で最も広く用いられる。 連続かつ無限回微分可能で、理論的にも扱いやすい。 |
| 一様カーネル | U[-1/2,1/2] | 四角い箱型。 | 一定の範囲外はスパッと0にする。 |
| 三角カーネル | 1-|u| | 三角形の山型。 | 中心が最も高く、離れるにつれて直線的に減衰する。 |
KDEの具体的な問題を考えます





| 決定・調整アプローチ | 理論・仕組み | メリットと注意点 |
| MISEに基づく漸近解析 | 平均積分二乗誤差(MISE)を最適化する。サンプルサイズnに対して n^{-1/5}のオーダーで縮める。 | 理論的な美しさがあるが、あくまで理想的な状況を想定した議論。現実のデータでは必ずしも最適とは限らない。 |
| Silvermanの経験則 | データの標準偏差などから一発で初期値を計算する公式。 | 単峰の正規分布に近い場合には手軽で便利だが、多峰性や重い裾を持つ分布には適合しないため注意が必要。 |
| クロスバリデーション (交差検証) | データを学習用と検証用に分け、過平滑(バイアス大)とギザギザ(分散大)を除外する。 | 近年の主流手法(再標本化)。 擬似的な真の分布に対してバランスの良いhを見極められる。 |
| ブートストラップ | 標本を繰り返し再抽出して推定を行う。 | 推定結果を総合評価することで、特定のバンド幅に関する安定性を確認できる。 |


さらにKDEの例題を考えます


その他の学習
強化学習
| 枠組み | 入力データ | 学習の目標(出力) | 特徴・善悪の基準 |
| 教師あり学習 | 入力データ(画像など) | 望ましい出力(ラベル・正解) | 与えられた「正解」を再現するように学習する。 |
| 教師なし学習 | 入力データ(顧客データなど) | パターンや構造の抽出 | 善悪の概念はない。 データの変換や次元削減、クラスタリングを行う。 |
| 強化学習 | 状態(環境からの観測) | 勝率や収益を高くする行動 | 正解は与えられない。環境との相互作用による「報酬(フィードバック)」を基準に試行錯誤する。 |
| 用語 | 読み・意味 | 囲碁(ゲーム)の例 | 役割・ポイント |
| エージェント | 意思決定の主体(AIプログラム) | 囲碁をプレイするプログラム | 環境に対して「行動」を起こし、賢くなっていく主役。 |
| 環境 | エージェントが相互作用する対象 | 対戦相手(と基盤) | エージェントの行動を受けて「状態」を変化させ、「報酬」を返す。 |
| 状態 (State: s) | 環境の現在のシチュエーション | 盤面上の石の配置 | 厳密には「観測」と区別されることもあるが、本書では同一視して進める。 |
| 行動 (Action: a) | エージェントが選択する一手 | 新たに石を置くこと | 状態 s に応じて、エージェントが自発的に行う選択。 |
| 報酬 (Reward: r) | 行動の直後にもらえる即時的な評価 | 勝利なら +1、敗北なら -1 | 行動の「よさ」を表すフィードバック。直後の報酬だけでなく、未来の累計が大事。 |
| 方策 (Policy: π) | 行動の「対応表」(ルールブック) | 各盤面でどこに打つかの戦略 | 状態 sに直面したとき、どの行動 a を取るべきかの対応関係。 |
目的関数と収益G_tの定義をします。目先の報酬に釣られないように未来を見据えて最適化するための数式の比較です。

Q学習(価値関数の更新)と戦略



ベルマン方程式について具体的な例題を考えます





時系列解析
状態空間モデルは難易度が高いので合格のために深煎りは必要なしと考えています。
時系列解析はアクチュアリー数学でのメイン部分の1つですので別記事にもARIMAモデルくらいまでは学習できます。

時系列データの特徴
時差をkとするとき、nとn-kなどについて考えています。

| 定常性の種類 | 平均 mx(n) の条件 | 自己共分散 cx(n,k) の条件 | 密度関数の条件 | 暗記のポイント |
| 広義定常性 (弱定常性) | 時刻 n に依存しない (常に一定 m_x) | 時刻 n に依存せず、時間差 k のみに依存する。 | 特になし | 実務・試験で最も重要。 平均、分散、自己相関の3つが時間シフトで不変。 |
| 狭義定常性 (強定常性) | 時刻 n に依存しない | 時間差 k のみに依存する | すべての有限次元分布の密度関数が、時間シフトに対して完全に不変。 | 広義定常よりも条件が遥かに厳しい。「狭義ならば広義」は成り立つが、逆はNG。 |
| 周期定常性 | 周期 Tで同じ値に戻る m_x(n) = m_x(n+mT) | 周期 T で同じ構造に戻る r_x(n,k) = r_x(n+mT,k) | 特になし | 完全に一定ではなく、季節変動や周期的な規則性を持って変化する非定常の一種。 |





| モデル名 | 数式の構成要素(イメージ) | データの性質 | 差分の操作 |
| AR モデル (自己回帰) | 「過去の自分の値」 の重み付き和 + 白色雑音 | 定常 | なし |
| MA モデル (移動平均) | 「過去~現在の白色雑音(エラー)」 の重み付き和 | 定常 | なし |
| ARMA モデル (自己回帰移動平均) | 「過去の自分」 + 「過去~現在の雑音」 | 定常 | なし |
| ARIMA モデル (自己回帰和分移動平均) | ARMAモデルを、「差分をとったデータ」 に適用したもの。 | 非定常 (傾向変動がある) | d 階差分 ΔX(n) = X(n) - X(n-1)を取る。 |
| SARIMA モデル (季節ARIMA) | ARIMAに、「周期 S ごとの過去のデータ・雑音」 を取り込んだもの。 | 非定常 (季節周期変動がある) | D 階季節差分 Δ_S X(n) = X(n) - X(n-S)も取る。 |






状態空間モデルの構造と2つの数式を考えます。目に見えない真の状態X_tと、ノイズ混じりで目に見える観測値Y_tを分けて考える強力なフレームワークです。
| 方程式名 | 数式表現(線形・ガウス型) | 登場する雑音 | 数式が意味すること(イメージ) |
| システム方程式 (状態方程式) | x_t ={F_t {x}_{t-1} + G_t {w}_t | システム雑音 w_t (共分散 {Q}_t) | 目に見えない「真の状態」が、1刻み前に連動してどう推移していくか。 |
| 観測方程式 | y_t =H_t {x}_t + v_t | 観測雑音 v_t (共分散 R_t) | 「真の状態」に、センサーのブレなどのノイズが乗ってどう「観測値」に変換されるか。 |
状態推定の3つのタスクとカルマンフィルタの更新について考えます。手元にある観測データyを使って、どの時点での状態xを推定した以下による分類と、そのコアとなるカルマンフィルタのアルゴリズムです。
| タスク名 | 求めたい確率分布 | 使う観測データ y の範囲 | 直感的イメージ |
| 予測 (Prediction) | p(x_t|y_(1:(t-1))) | 1時刻前までのデータ(t-1 まで) | 「これまでのデータからして、次はどうなる?」 |
| フィルタリング (Filtering) | p(x_t|y_(1:t)) | 現時刻までのデータ(t まで) | 「今得られたデータも使って、今の真の姿を補正しよう」 |
| 平滑化 (Smoothing) | p(x_t|y_(1:T)) | 未来も含めた全データ(最後 T まで) | 「全期間のデータが揃ったから、過去のあの時点を綺麗に振り返ろう」 |


カルマンフィルタの更新ステップについて考えます。線形・ガウス型を前提とするため、期待値xバーと共分散Pの2つだけを追いかければ良いです。

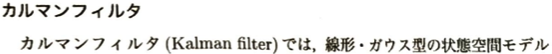


非常に抽象的な分野なので具体的な問題を考えます





生存時間解析
生存時間データ
| 概念 | 意味・定義 | 医療(追跡調査)の例 | 製造業(製品テスト)の例 |
| 生存時間データ | ある基準点から、特定のイベントが発生するまでの時間。 | 手術をしてから、病気が再発するまでの期間。 | 製品の製造(稼働開始)から、故障するまでの月数。 |
| イベント | 観測のゴールとなる現象。 | 病気の再発、死亡、退院など。 | 故障、破産、顧客の離反など。 |
| 打ち切り (Censoring) | イベントが発生する前に、何らかの理由で観測が終了すること。 ※除外せず、情報として活用する。 | 患者の引っ越しによる転院、生存したまま研究期間が終了。 | テスト期間中に壊れないまま実験が終了、機器の紛失。 |

| 関数名 | 記号 | 確率的な意味・定義 | 数式(ハザード等を用いた表現) | 直感的イメージ |
| 分布関数 | F(t) | 時刻 t までにイベントが発生する確率。 | P(T≦t) = 1 - exp(-H(t)) | 「もうすでに壊れてしまっている」確率。 |
| 生存関数 | S(t) | 時刻 t を超えて生き残る(イベントが起きない)確率。 | P(T > t) = exp(-H(t)) | 「時刻 tの時点で、まだ無事に動いている」確率(初期値 S(0)=1)。 |
| ハザード関数 | h(t) | 時刻 t まで生き残ったという条件のもとで、その直後の瞬間にイベントが起こる勢い。 | f(t)/S(t) | 「今この瞬間、どれくらいピンチ(壊れやすさの指数)か」。 |
| 累積ハザード関数 | H(t) | ハザード関数 h(t) を、初期時点から時刻 t まで積み上げた(積分した)もの。 | -log S(t) | 「これまでに溜まったダメージの総量」。 |
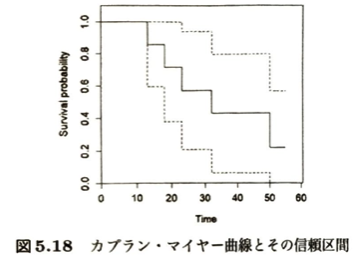
なぜ確率密度関数f(t)でなく累積ハザード関数H(t)でモデル化するのかを考えます
| 比較対象 | モデリングのしやすさ・特徴 | 指数分布(最も単純なモデル)での例 |
| 確率密度関数 f(t) | イベントの起こりやすさそのものだが、全体の確率が1になる制約などがあり、複雑な要因(年齢や環境など)を数式に組み込みにくい。 | f(t)=λ exp(-λt) (時間が経つほど値が小さくなり、直感的なピンチ度が分かりにくい) |
| 累積ハザード関数 H(t) (★推奨) | 「時刻 t までイベントが発生していない」という前提条件(分母)付きで考えられるため、人間がイメージしやすくモデル化が容易。 | H(t) = λt (ハザード h(t)=λ が一定のとき、ダメージは時間に比例して綺麗に直線で積み上がる) |

生存関数の推定





| 項目 | 定義・数式 | データの扱い・グラフの特徴 | 暗記・実務のポイント |
| 生存関数の推定式 | S ^(t)=Π(1-(d_i)/(n_i))(ただしi:t_i≦t) | 各イベント発生時点 t_i での「生き残り確率 1-(d_i)/(n_i)」を次々に掛け算(総乗)していく。 | n_i:時点 t_i の直前にまだ生き残っている人数(リスクセット)。 d_i:時点 t_i でイベントが発生した人数。 |
| グラフの形状 (図5.18) | 階段状(非増加のステップ関数) | イベントが発生した時点(t_i)でのみグラフがガクッと下がり、「打ち切り」が発生した時点では下がらない。 | 最後のデータが「打ち切り」の場合、それ以降の生存時間は観測できないため、グラフはその時点でストップする。 |
| 信頼区間の計算 | Greenwood(グリーンウッド)の公式 | 推定値のまわりの95%信頼区間を近似計算する標準的な方法。 | 改良版として、信頼区間が [0,1] を超えないように対数変換(log S(t))を挟む手法もある。 |
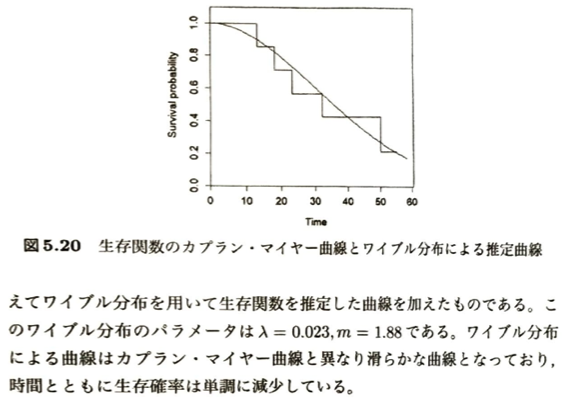
先ほどの尤度の式について振り返ります。




| 分布名 | 生存関数 S(t) | ハザード関数 h(t) | 形状パラメータ m による変化(図5.19) | 実務でのイメージ |
| 指数分布 | exp(-λt) | λ (常に一定) | m = 1 のときのワイブル分布に相当。 | 「偶発故障」のモデリング。どれだけ時間が経っても、次の瞬間に壊れる確率(ハザード)がずっと変わらない特殊な状態。 |
| ワイブル分布 | exp{-(λt)^m} | mλ^m t^{m-1} | m > 1:ハザードが時間とともに増加 m < 1:ハザードが時間とともに減少 | 「摩耗故障(経年劣化)」などを柔軟に表現できる。パラメータの推定には、通常最尤法(ニュートン法などの数値解法)が使われる。 |

| 指標名 | 数学的定義 | カプラン・マイヤー(離散型)での決まり方 | ワイブル分布(連続型)での決まり方 |
| メディアン生存時間 (MST) | MST = min_{t} {t|S(t)≦ 0.5} | 生存確率 S ^(t)が初めて 0.5 以下になるまでの経過時間。 (図5.20の例では 32 か月) | S(t) = 0.5 という方程式を解いたときの、グラフがちょうど 0.5 を横切る滑らかな点。 (図5.20の例では 35.8 か月) |
カプランマイヤー法とグリーンウッドの公式に関する具体的な例題を考えます







コックスの比例ハザード回帰モデルは薬の有無や年齢など、複数の説明変数(背景因子)が生存時間にどう影響するか調べる、実務の王道回帰です。


| 項目 | 数式表現 / 構成要素 | モデルの分類・性質 | メリット・実務での特徴 |
| 比例ハザードモデル | h(t) = h_0(t) exp(β_1 x_1 + … + β_p x_p) | セミパラメトリックモデル (ベースの形は決めず、説明変数の影響だけをパラメトリックに扱う) | ベースとなるハザード関数の形(h_0(t))を具体的に指定しなくても、回帰係数 β を推定できるため非常に使い勝手が良い。 |
| 基準ハザード関数 | h_0(t) | すべての説明変数 x が 0 のときの、いわば「素のハザード(年齢や時間の経過に伴う自然なリスク変化)」。 | ここにワイブル分布などを仮定すると「パラメトリックモデル」になるが、仮定しないコックスモデル(Cox型)が一般的。 |
| 仮説検定 | log-rank(ログランク)検定など | 各説明変数の効果(β = 0かどうか)や、2つのグループの手術療法の生存曲線に有意差があるかを調べる検定。 | 医療の治験やA/Bテストで、手法Aと手法Bのどちらが長生き(あるいは長く継続)したかを比較する際に必須。 |
ログランク検定とコックスの比例ハザードモデルの具体的な例題を考えます




クロンバックのα係数について例題を考えます


質的データ解析
多重分割表
シンプソンのパラドックスについて考えます。これは3つ以上の質的変数があるとき、特定の変数だけで丸めてしまう(周辺和をとる)と、恐ろしい誤認が生まれるという実例の比較です。
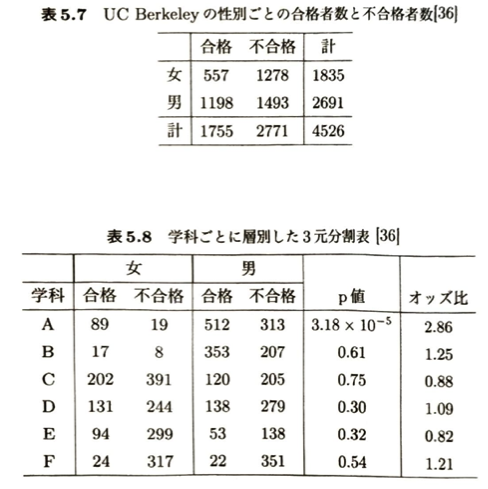
| 集計のやり方 | 表の性質 | データの見え方・検定結果 | 導かれる結論 |
| 全体で集計 (表5.7) | 性別 × 合否 の2元分割表 (学科の情報を無視) | カイ二乗値 χ^2 = 92.21、オッズ比 0.54 → 女性の合格率が有意に低い。 | 「女性に不利な入試が行われているのでは?」と誤認してしまう。 |
| 学科ごとに層別 (表5.8) | 学科 × 性別 × 合否 の3元分割表 | 最も競争率の高いA学科では、オッズ比 2.86 → 女性の方が有意に合格率が高い(他学科は有意差なし)。 | 実態は「女性はたまたま倍率の超高い学科(Aなど)を多く受験していただけ」であり、入試自体はむしろ女性に有利、または平等だった。 |
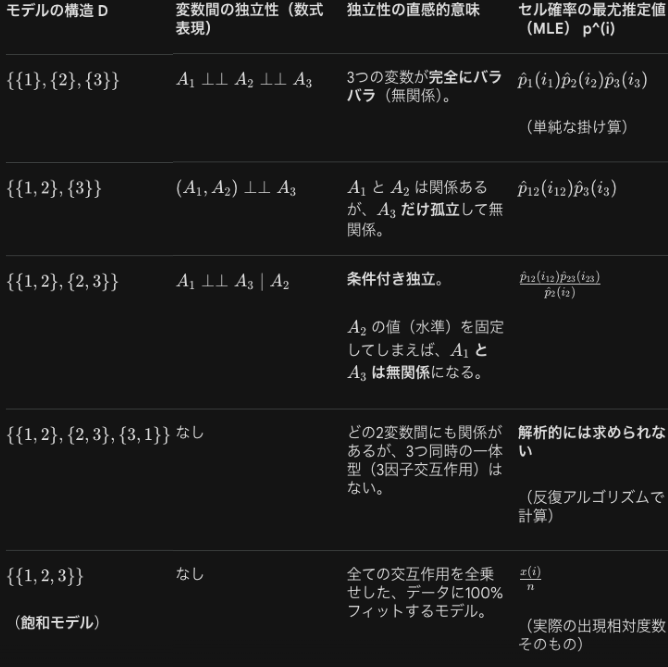
次に3元分割表における対数線形階層モデルを定義します。





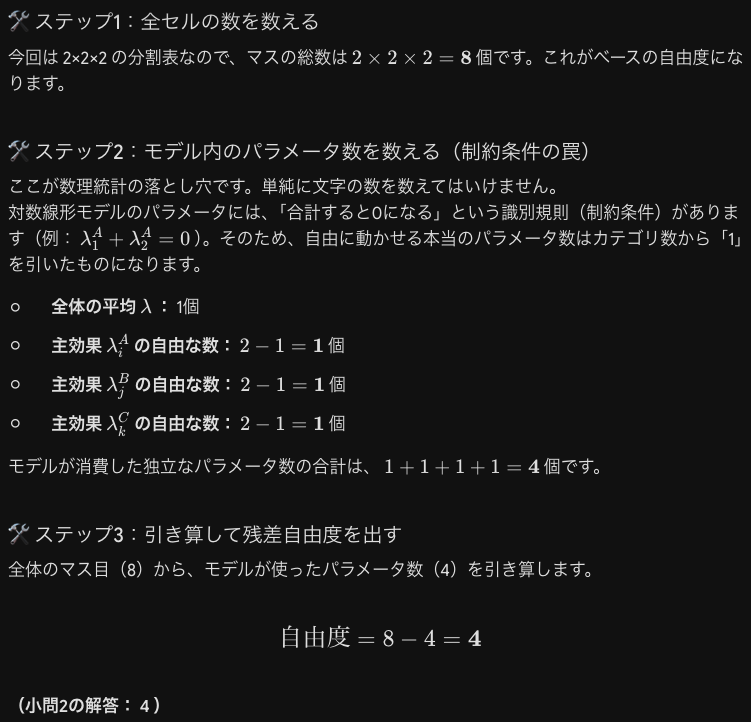
改めてモデルの指定方法(D)と独立性の関係を考えます。テキサス大やバークレーの例でも出てきた、モデルの構造 Dの選び方と、それによって仮定される「独立性」、および「確率の最尤推定(MLE)」の対応表です。


対数線形階層モデルの具体的な例題を考えます




数量化理論
日本で独自に開発された伝統的な多変量解析手法「数量化理論」を考えます。林知己夫先生によって開発されたこの手法は、一見複雑に見えますが、本質は「アンケート結果などの『質的データ』をダミー変数に変換して、お馴染みの『量的データ分析(回帰や判別など)』に持ち込む」という非常にシンプルなアイデアです。
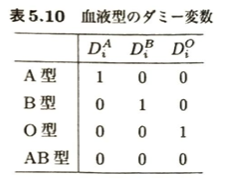
| 手法名 | 目的変数(予測したいもの) | 説明変数(予測に使うもの) | 対応する現代の多変量解析・機械学習手法 | 具体例(テキストの例など) |
| 数量化Ⅰ類 | 量的変数 (連続値・数値) | すべて質的変数 (ダミー変数化) | 重回帰分析 (説明変数をすべてOne-Hot化したもの) | 性別、年齢層、職業、居住地域から、ある商品への「支出額(〇〇円)」を予測する。 |
| 数量化Ⅱ類 | 質的変数 (カテゴリ・グループ) | すべて質的変数 (ダミー変数化) | 線形判別分析 / ロジスティック回帰 | 消費者の属性(質的)から、ある商品の「購入意向(買う・買わない)」を予測・判別する。 |
| 数量化Ⅲ類 | なし(変数の関連の可視化) | すべて質的変数 | 主成分分析(PCA) / 対応分析(コレスポンデンス分析) | アンケートの回答パターンの似ている項目や人をグルーピングして可視化する。 |


対応分析(コレスポンデンス分析)



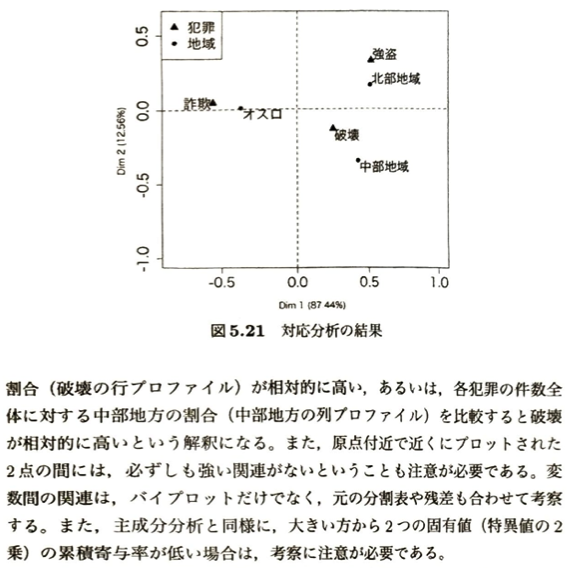


| グラフ上の関係 | 数学的な意味 | 正しい解釈のやり方(ノルウェーの犯罪例) | ⚠️ やってはいけない誤認(罠) |
| 「地域」と「犯罪」が 近くにプロットされている | 2つの点の内積が、対応するセルの指標化残差の大きさと近似している。 | 「オスロと詐欺」「北部地域と強盗」は、独立の仮定から大きくハズれて、その組み合わせが相対的に多く発生している(特徴的である)。 | 「近くにある=絶対的な件数が多い」とは限らない。 (例:中部地域と破壊は近くにいるが、破壊の件数自体はオスロや北部の方が多い) |
| 「地域同士」または 「犯罪同士」が近い | 同じ変数内の2点間の距離が、カイ二乗距離と近似している。 | プロファイルの構成比のパターン(内訳)が、その2つの間で非常に似通っている。 | 原点(0,0)の付近でたまたま近くに集まっている2点には、強い関連がない場合もあるので注意。 |
質的変数が3つ以上になった場合の拡張アプローチの比較です。

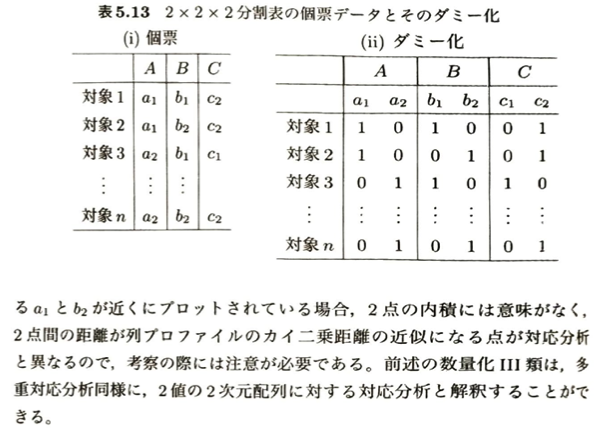
| 手法名 | 対象となる変数 | データの入力形式(図5.13) | グラフ(バイプロット)の幾何学的性質 | 他の手法とのリンク |
| 対応分析 (通常のMCA) | 2つの質的変数 | カテゴリ同士の度数をクロス集計した通常の分割表(表5.11)。 | 異なる変数に属する2点間の内積に意味がある(残差の大きさを表す)。 | 行列 Z の各行・各列を、特異値分解(SVD)を用いて2次元に縮約する。 |
| 多重対応分析 (MCA) | 3つ以上の質的変数 | 個票データ(i)のカテゴリをすべて「0と1」のフラグにしたダミー化データ(ii)。 | 異なる変数に属する2点間の内積には意味がなくなる。2点間の距離がカイ二乗距離の近似になる。 | 前述の「数量化Ⅲ類」は、2値の2次元配列に対する対応分析とみなせるため、実質的に同義。 |

コレスポンデンス分析の具体的な例題を考えます





テキストデータ解析
本章の内容もレベルが高いです。無理して深入りしないようにしたいです。
テキストデータの数値化
DS発展の時の公式を復習します





| 解析の段階 | 処理の内容 | 直感的イメージ |
| 形態素解析 | 文を「意味を持つ最小単位(形態素)」に分割し、品詞(POSタグ:NNやVBなど)や活用形を付与する。 | 「朝晩」「めっきり」「寒く」「なっ」「た」にバラバラにする。 |
| 構文解析 | 文の語句間の修飾関係(かかり受け)を解析する。 | 「めっきり」が「寒く」にかかっていることを見抜く。 |
| 述語項構造解析 | 文の「主語・目的語(項)」と「述語」の関係を解析する。 | 「誰が」「何を」「どうした」の骨組みを捉える。 |
| 文脈解析 | 文と文の間のつながりや関係を解析する。 | 前後の文の流れを追う。 |
| 照応解析 | 文をまたがった代名詞(これ、それ)や指示語が指す中身を特定する。 | 「それ」が前の文のどの単語を指しているか突き止める。 |
| 談話構造解析 | 文や節の間の、さらに大きな意味的な関係を解析する。 | テキスト全体のストーリー構造を理解する。 |



| 手法名 | ベクトルの値(要素)の決め方 | 仕組み・特徴 | メリット・デメリット |
| Bag-of-Words (BoW) | 単語が含まれているか(0 or 1)、または出現回数そのもの。 | 単語をただ「袋(Bag)」に詰め込んだように扱う。単語の出現順序や文脈は完全に無視される。 | シンプルで分かりやすいが、「てにをは」や「の」など、どの文章にも出る定番単語の重みが無駄に高くなってしまう。 |
| TF-IDF法 | tf_(t,d)×log(N/(df_t)) | TF(単語の出現頻度) と IDF(逆文書出現頻度) の掛け算。 「その文章に多く出て、かつ他の文章には滅多に出ないレア単語」の価値を跳ね上げる。 | 単語の相対的な重要度をきれいに数値化できる。検索エンジンや特徴量抽出の王道。 |


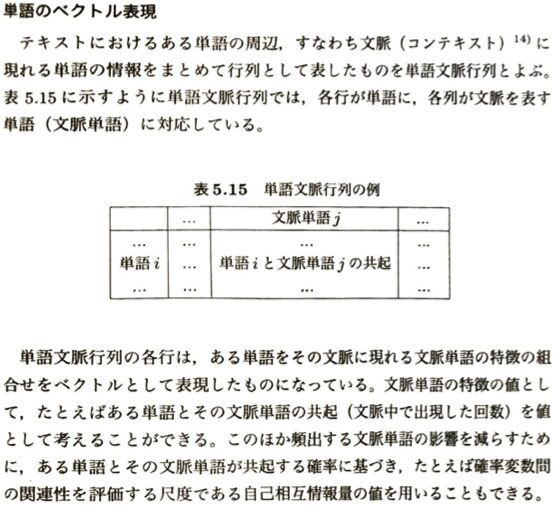

| 行列名 | 行(横軸)が表すもの | 列(縦軸)が表すもの | セル(中身)の値 | 応用・使いどころ |
| 文書単語行列 (表5.14) | 各テキスト(文書) | 各単語(語彙) | 単語の出現回数、またはTF-IDFの重み。 | 文章同士のコサイン類似度を計算し、似た内容の書類を検索・クラスタリングする。 |
| 単語文脈行列 (表5.15) | ターゲットの単語 i | 周辺に現れる文脈単語 j | 窓(ウィンドウ)の範囲内での共起回数(または自己相互情報量)。 | 「単語埋め込み」のベース。「似た文脈に出る単語は意味も似ている(分布仮説)」という考え方に基づく。 |

Word2Vec(ニューラルネットワークによる単語埋め込み)について考えます。文脈行列の「サイズが大きすぎる・スカスカ(高次元・希薄)」という弱点を、特異値分解やニューラルネットで低次元のギッシリ詰まったベクトルに凝縮(分散表現)する技術です。



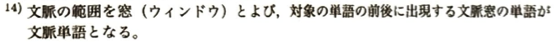

| Word2Vecのモデル | 予測の方向(仕組み) | 直感的イメージ | 最大の特徴・応用 |
| CBOW | 周辺の文脈単語から、中心にある1つの単語を予測する。 | 「今日の天気は( ? )晴れだ」の( ? )を当てる。 | 比較的軽量に学習できる。 |
| Skip-Gram | 中心にある1つの単語から、周辺の文脈単語たちを予測する。 | 「とても」という単語から、前後に「寒い」「美味しい」が来る確率を予測する。 | CBOWより性能が良く、特に低頻度な単語の表現に強い。 |


TF-IDFとCBOWに関する具体的な例題を考えます






テキスト分析


| 手法・ツール名 | グラフの形状(図) | 仕組み・表していること | 実務での使いどころ |
| ワードクラウド | 文字の大きさのバラつき (図5.22) | 単語の出現頻度や TF-IDFの重要度 を文字の大きさに反映して可視化する。 | 顧客アンケートやSNSの口コミで、どんな単語が注目されているかを一目で掴む。 |
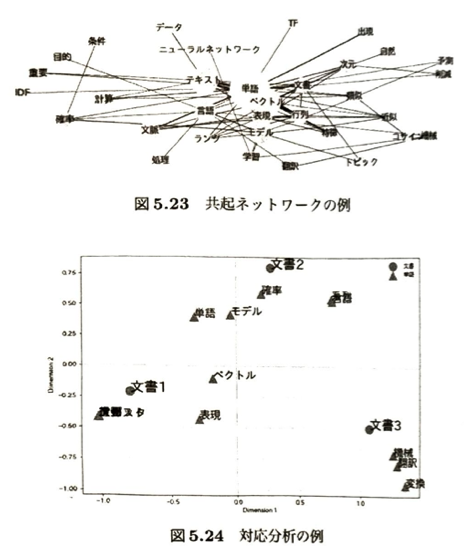
| 共起ネットワーク | 単語(ノード)と線(エッジ) (図5.23) | 単語同士が「一緒に使われる(共起する)」関係をネットワーク図にしたもの。 | ネットワークの中心性を計算して重要単語を特定したり、クラスタリング(コミュニティ抽出)でトピックを抽出する。 |
| 対応分析(低ランク近似) | 2次元の散布図 (図5.24) | 単語文脈行列を低ランク近似(次元削減)し、人が理解可能な2次元や3次元の空間にマッピングする。 | 単語同士の「意味や文脈の近さ」を幾何学的な位置関係として視覚的に理解する。 |

| 手法名 | 英語・略称 | アプローチの核(仕組み) | 暗記・位置づけのポイント |
| 潜在的意味索引付け | LSI (Latent Semantic Indexing) | 文書単語行列を「低ランク近似(次元削減)」することで、文書のベクトル表現を得る。 | トピックモデルの最も原始的なベースとなる考え方。 |
| 確率的潜在的意味索引付け | PLSI (Probabilistic LSI) | LSIに「確率モデル」を導入したもの。文書は複数のトピックの混合確率として表現される。 | トピックモデルの基本形。 |
| 潜在的ディリクレ配分法 | LDA (Latent Dirichlet Allocation) | PLSIをベースに、さらに「階層ベイズモデル」として確率分布に拡張したもの。 | 【最重要】 現在、トピックモデルの中で最も広く使われている王道手法。 |
LSIの具体的な例題を考えます











| タスク | 進化・アプローチの歴史 | コアとなる技術・キーワード | 仕組み・暗記のツボ |
| 機械翻訳 | 統計的機械翻訳 ↓ ニューラル機械翻訳 | エンコーダ・デコーダモデル (Encoder-Decoder) + 注意(attention)機構 | 原言語をベクトルに圧縮(エンコード)し、それを目的言語にデコードする。その際、文のどこに着目すべきかを制御するアテンション(attention)の導入で精度が劇的に向上した。評価尺度には BLEU が使われる。 |
| かな漢字変換 | 形態素解析の応用技術 | 最短経路問題 (ビタビアルゴリズムによる動的計画法) | 単語辞書からマッチする漢字・文字の組み合わせを「ノード」、つながりを「エッジ」としたグラフを作る。その中で「文頭から文末にいたる最も自然な最短ルート」を動的計画法でガツンと解く。 |
LDAとn-gramに関する具体的な例題を考えます






MeCabの例題を考えます


モデルの評価
解析に利用した統計モデルとそのパラメータ推定量が、データの背後にある構造にどの程度適合しているかを定量的に計算します。
データの母集団分布が既知という理想的な状況にて、どのような評価尺度が適切か→観測したデータから、その理想的な状況での評価尺度をどのように近似的に計算するかで設計されます。
ただしこの近似を行うとパラメータ推定量の構成と評価尺度の近似計算に同一の観測データを用いているため、この2つの値が相関することに由来するバイアスが発生します。これは過学習問題とも関連し、パラメータの推定量を過剰によく評価する原因にもなります。このバイアスを除くため、工夫を考えます。
モデル評価指標


| 問題設定 | 目指すべき基本指標(数式) | 指標の持つ意味・特徴 |
| (i) 尤度が計算できる場合 (確率モデル・最尤法) | 期待対数尤度 | 真のデータ生成分布 q(・)に対して、モデル p(X|θ^)がどれくらい適合しているかの「よさ」。値が大きいほど適切。 ※ベイズリスクを評価する状況では、θ を周辺化した周辺尤度を用いる。 |
| (ii) パラメータの真値 θ が 定まっている場合 | 平均二乗誤差 (MSE) 平均絶対値誤差 (MAE) | 真のパラメータ θ と、手元のデータから推定した θ^ の間の「距離・ハナレ度」。値が小さいほど適切。データの性質に合わせてノルムを選択する。 |
| (iii) データを分類する場合 (クラス・カテゴリ判別) | 混同行列に基づく諸指標 (次の一覧表を参照) | スパム判定や画像認識など、データをあらかじめ定めたクラスに振り分ける問題。タスクの目的に応じて注目する指標が変わる。 |
迷惑メールは適合率が適切で検索エンジンでは再現率が望ましいです。
| 実際 \ 予測 | 陽性(Positiveと予測) | 陰性(Negativeと予測) |
| 陽性(実物は陽性) | 真陽性 (TP) :見事的中! | 偽陰性 (FN) :陽性なのに陰性と見落とし。β |
| 陰性(実物は陰性) | 偽陽性 (FP) :陰性なのに陽性と誤検知。α | 真陰性 (TN) :見事的中! |
| 指標名 | 数式表現 | 指標の意味(何を重視するか) | 実務での具体例(テキストより) |
| 正解率 (Accuracy) | (TP+TN)/(TP+FP+TN+FN) | 全データのうち、陽性・陰性を正しく判定できたデータの割合。全体的な性能。 | 陽性と陰性のデータバランスが偏っていない通常の評価。 |
| 適合率 (Precision) | (TP)/(TP+FP) | 陽性と予測したもののうち、本当に陽性だった割合。「オオカミ少年(誤検知)」を減らしたいときに重視。 | 迷惑メールフィルター:通常の重要メールを間違えて迷惑メールフォルダに入れたくない(適合率重視)。 |
| 再現率(検出力、感度、真陽性率) (Recall) | (TP)/(TP+FN) | 本当に陽性であるデータのうち、漏らさず陽性と判定できた割合。「見落とし」を絶対に防ぎたいときに重視。 | 検索エンジン:多少ノイズが混ざってもいいから、目的の有益な情報を持つサイトを網羅したい(再現率重視)。 |
| F1値 (F-measure) | 右の説明参照 | 適合率と再現率の調和平均。どちらか片方だけが極端に高くても値が上がらない、バランスの指標。 | 適合率と再現率をバランスよく評価したい総合評価の場面。 |
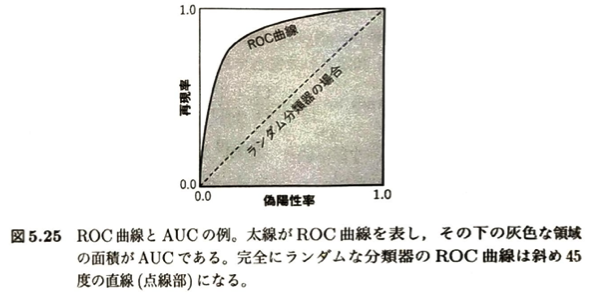

特異度=1ー偽陰性率です。つまり真陰性率をいいます
モデル評価の実務よりの例題を考えます





分かりそうでわからないのでもう少し具体例が欲しいです
了解です。次の例をどうぞ!







| 推定手法 | 仕組み・データの分割方法 | メリット | デメリット・課題 |
| ホールドアウト検証 (Hold-out) | データを「訓練用 D^{train}」と「検証用 D^{val}」の2つにスパッと分ける。 | シンプルで計算コストが最も低い。 | データの分け方による外れ値などの影響を受けやすく、頑健性(ロバストさ)が下がる。 |
| k 分割交差検証 (Cross Validation) | データを k 個に分割し、1つを検証用、残りを訓練用にする。これを k 回繰り返して平均を出す。 | 手元にある全データを無駄なく評価に使え、過学習のバイアスを綺麗に回避できる。幅広い尺度に使える。 | k 回モデルの訓練を繰り返すため、計算コストが増大する。 |
| LOO 交差検証 (Leave-One-Out) | k 分割交差検証の極限(k = n)。データ1件だけを検証用にして、残りの n-1 件で学習する。 | 評価のブレが最小限に抑えられる。 | データ数 n の数だけ学習を繰り返すため、大規模データでは計算が全く終わらない。 |



訓練データとテストデータ
| データセット名 | テキストでの表現 | 役割・モデルが受ける影響 | ⚠️ 厳格に守るべき原則(ルール) |
| 訓練データ (Train data) | 訓練用サンプル (学習用サブセット) | パラメータの推定(重みの更新や回帰係数の決定)に直接参照して使われるデータ。 | このデータに合わせ込みすぎると、ノイズや外れ値まで記憶して過学習を起こす。 |
| 検証データ (Validation data) | 検証用サブセット | 学習の途中で、過学習の兆候を検知したり、多項式の次数や木の深さなどのハイパーパラメータを調整・最適化するために使う。 | 固定して使うとサイズが小さく評価が不安定になるため、交差検証(クロスバリデーション)を併用するのが有効。 |
| テストデータ (Test data) | 最終評価用のサンプル (未知データ) | 最終的に、全く未知のデータに対する本番の予測性能(汎化誤差)を公正に見積もるために使う。 | 【絶対原則】学習・調整工程には一切使わない。 もし途中で参照すると、テストデータにまで間接的に合わせ込みが進み、客観的な評価ができなくなる(データリークの発生)。 |
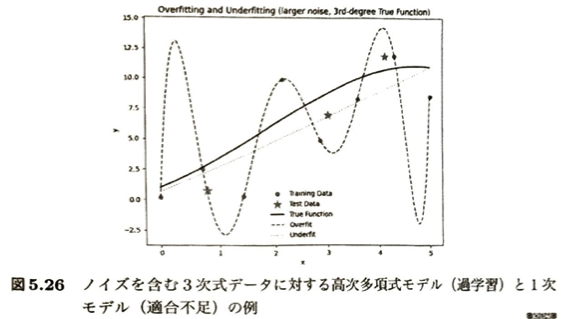
| 状態 | 原因とモデルの特徴 | 訓練データでの誤差 | 未知(テスト)データでの誤差 | グラフの視覚的特徴(図5.26) |
| 過学習 (Overfitting) | モデルの複雑さ(柔軟性)が大きすぎる。 固有のノイズや外れ値にまで合わせ込みが行き過ぎている。 | 極限まで小さくできる (ほぼゼロになる) | 大きくなる | 高次多項式モデルが、訓練データ(丸記号)をほぼ完全に通過する一方、テストデータ(星記号)から外れて不自然に大きく振動している状態。 |
| 未適合 / 適合不足 (Underfitting) | モデルが単純すぎる。 | 下げきれない (訓練データでさえ誤差が大きい) | 大きくなる | 1次の線形モデル(直線)が、データ全体を大きく平均化してしまい、真の関数から乖離している状態。 |
最終評価で性能が出なかったとき、データサイエンティストがとるべき行動と罠のまとめです。
| 評価後のアクション | 適切なアプローチ(理想論) | ⚠️ やってはいけない禁忌(罠) |
| 特徴量設計やモデル構造の再考 | 1. データの分割を最初からやり直して、未知性を確保する。 2. 別途追加の新しいテストデータを用意して再評価する。 | 「テストデータで点数が悪かったから、それが良くなるようにモデルをちょっといじって、もう一度同じテストデータで測る」を繰り返し利用してしまうこと。 |
| 禁忌による代償 | 意図せぬ合わせ込みがテストデータにまで及んでしまい、「身内びいきの甘い評価」に成り下がる。 | 真に未知であるデータへの実力(汎化誤差)を公正に見積もることが不可能になる。 |

因果推論
因果モデル
まずは条件付き確率に関する簡単な内容を復習します。


| 用語 | 読み・英語 | 意味・定義 | 具体例(新薬の例) |
| 処置 | treatment | 原因系(与える操作や条件) | 新薬の服用 |
| アウトカム | outcome / 結果変数 | 結果系(処置によって変化する変数) | 疾病の治癒、治癒までの時間 |
| 処置効果 | effect | 処置がアウトカムに及ぼす効果 | 薬による治癒効果の大きさ |
| 処置群 | treatment group | 処置を施したグループ | 新薬を服用した集団 |
| 対照群 | control group / 統制群 | 処置を施さないグループ | 既存薬の服用、または服用しない集団 |
臨床試験の実験研究でも、割り当てられた処置が守られないことがあり得ます。これをノンコンプライアンスといいます。
| 研究の種類 | 英語 | 目的 | 最大の特徴・違い | メリット・デメリット |
| 実験研究 | experimental study | 処置効果の評価 | 研究計画を研究者の手でコントロール(ランダム割付け)できる。 | ◯ 両群が同質になりやすく、効果を純粋に測定できる。 ✕ ノンコンプライアンス(割付け通りに処置が守られないこと)によるバイアスのリスクがある。 |
| 観察研究 | observational study | 処置効果の評価 | ランダム割付けができず、現実のデータをそのまま観察する。 | ✕ 処置群と対照群の間で、背景(年齢構成など)に差異(偏り)が生じ、正しい効果の判定が難しい(工夫が必要)。 |
| 調査研究 | survey | 必ずしも処置効果の評価を目的としない | - | - |






| 概念 | 定義・数式 | 概要(何を意味しているか) |
| 因果推論における根本的問題 (fundamental problem) | Y_i(1) と Y_i(0) の片方しか観測できない | 個体 i に対して「処置をした場合の結果 Y_i(1)」と「処置をしない場合の結果 Y_i(0)」の両方を同時に観測することは不可能である、という事実。 |
| 強い意味での無視可能性 (strongly ignorable) | (a) 正値性: (b) 条件付き独立性: | 共変量 X を与えた下で、「結果の可能性(潜在的アウトカム)」と「実際の処置の割付け Z」が独立であるという条件。これが満たされると、観察研究でも共変量で調整することで処置効果が推定可能になる。 |



| 指標・性質 | 定義・数式 | 覚え方・メリット |
| 傾向スコア e{X} | e(x)=P(Z=1‖X) | 共変量 X が与えられたときに、処置群に割り振られる確率。ロジスティック回帰や機械学習で算出する。 |
| 1次元への縮約 | - | 本来なら複雑な多次元の共変量 X を、「0〜1の確率(1次元)」という扱いやすい1つの数値に変換できる。 |
| バランシング性 | e(X) が与えられたとき、X と Z は条件付き独立 | 傾向スコア e(X} の値が同じである個体同士を集めれば、その中での共変量 X の分布は処置群と対照群で等しく(バランス良く)なる。 |
| 手法 | 概要 | 特徴(メリット・デメリットなど) |
| ① マッチング | 処置群と対照群から、傾向スコアの値が同じ(または類似)個体をペアとして選び出す。 | ✕ 条件に合うペアが見つからない「選ばれない個体」は推定に使われず、捨てられてしまう。 |
| ② 層別(層別化) | 傾向スコアの値が似ている個体をいくつかの一まとめ(層)にする。 | 層ごとに両群を比較し、最後にそれらを統合することでバイアスを減らす。 |
| ③ 重み付け法 | 各個体に、傾向スコアに応じた適切な「重み」を与えて効果を推定する。 | ◯ マッチングとは異なり、すべての個体を無駄なく推定に用いることができる。 |
| ④ 共分散分析 | 共変量(あるいは傾向スコア)を説明変数として回帰モデル等に組み込む。 | 処置以外の要因(共変量)の影響を取り除いて処置効果を測定する。 |
因果推論の具体的な例題を考えます



グラフィカルモデリング
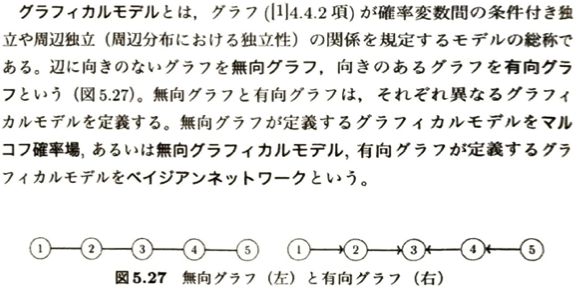

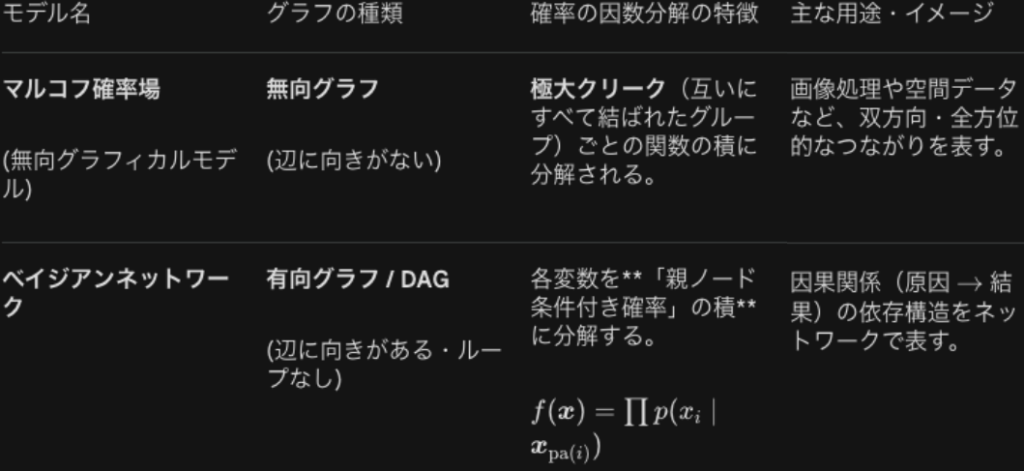



グラフィカルモデリングで無向グラフの例題を考えます

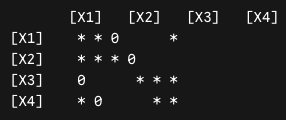




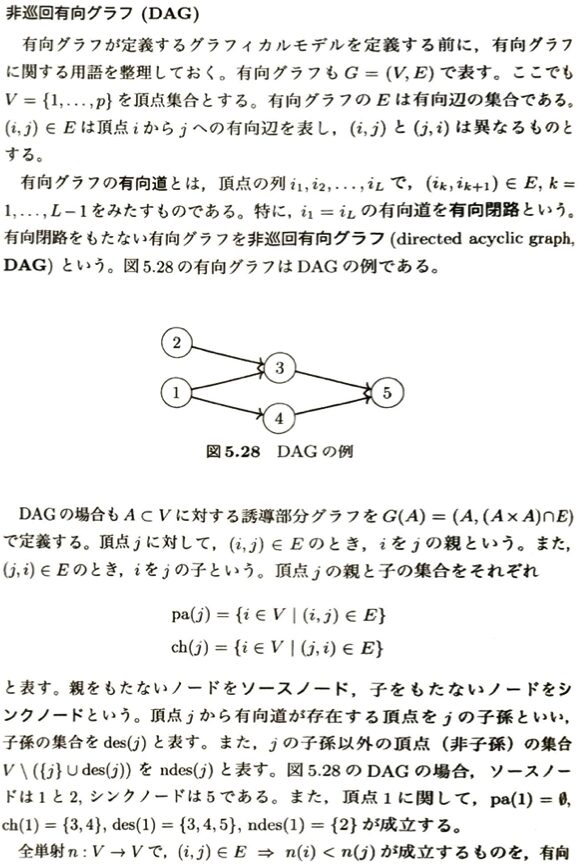


DAGに関する例題を考えます





d分離についてイメージを固めておきましょう。


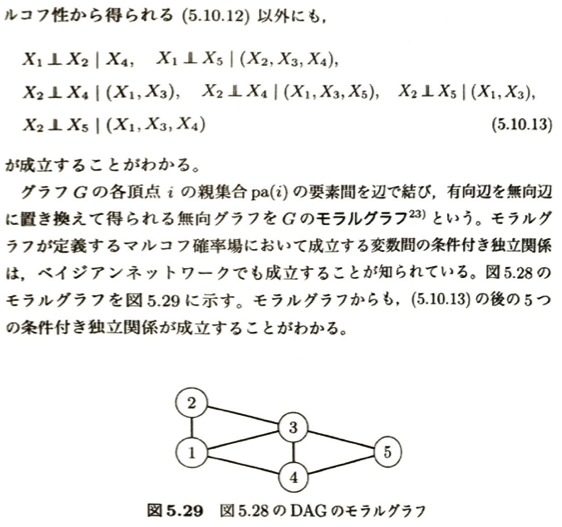
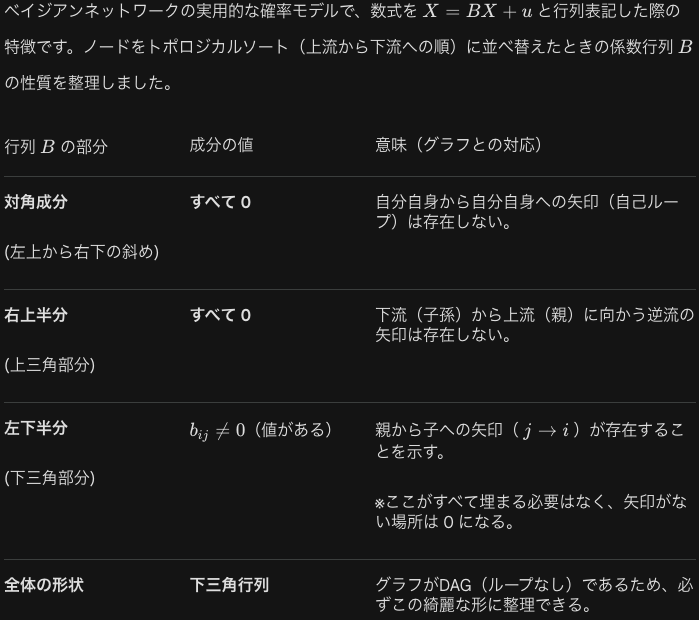
モラルグラフについて例題を考えます






最後に構造方程式モデルの具体的な例題を考えます





データサイエンスエキスパートの合格記事は下記です!


{kind=link}