
2026年6月8日にデータサイエンスエキスパート試験を受けて合格しました!
DSエキスパートの勉強方法は公式テキスト『データサイエンスエキスパート演習』を周回するだけで合格することは可能です。ただし本書は1章の重みがとてもあり、1ページの中でも行間が広いものも散見されます。そこで僕が勉強をしながら行間を埋めたり具体的な例題を探して解いたものもまとめて各章ごとの公式テキストの内容を消化していきたいと思います。
本記事は第5章の内容ですが、範囲が広すぎるので2記事に分けます。本記事はその後編です。

深層学習・ニューラルネットワーク
ニューラルネットワークは画像認識、音声認識、自然言語処理、生成AIといった広い分野で活用されています。
ニューラルネットワークの仕組み
脳にはニューロン(神経細胞)があり、そこから軸索が別のニューロンの樹状突起に接続されています。外部からの刺激を受けるとニューロンは電気的に活性化され、その電気信号を次のニューロンへ伝達します。これをモデル化してコンピュータ上で実現したものがニューラルネットワークです。ニューロン同士が情報をやり取りする接続部分をシナプスといいます。シナプス結合の強さ(どれくらい信号を伝えるか)を制御することが神経細胞で高次情報処理を実現するための基盤となります。ニューラルネットワークではニューロンという計算ユニットを定義して、それらを互いに接続してネットワークを構成します。ニューロンは前の層から入力を受け取り、重み付けされた信号の総和を計算し、非線形な変換(活性化関数)を施して次の層へ出力を伝えます。この重みが生物のシナプス結合の強さに対応しており、学習において大事なパラメータになります。


このような順伝播型の全結合層によるNetworkは入力層と出力層のみで2値分類を行い線形パーセプトロンに中間層を導入した多層パーセプトロンの一般型ともみなされます。隠れ層を持たない場合、入力層から出力層の計算は本質的に線形演算になり非線形な回帰問題や分類問題を解くことができませんが、隠れ層を複数重ねるとニューラルネットワークはより複雑な非線形関数を表現する能力を獲得し、高度な特徴抽出や意思決定が可能になります。このような多層構造のネットワークをディープニューラルネットワークあるいは深層ニューラルネットワークといい、これに基づく学習を深層学習といいます。
| 関数名 | 定義式 ϕ(x) | 主な特徴・メリット | 抱える課題・デメリット | 主な対策・派生関数 |
| ステップ関数 (Heaviside関数) | 1(x≧0) , 0(x<0) | 古典的なパーセプトロンで使われた超シンプル構造。 | 微分が不可能(または0)なため、バックプロパゲーションでの重み学習ができない。 | 微分可能な滑らかな関数(シグモイドなど)へ移行。 |
| シグモイド関数 | 1/(1+e^(-x)) | 出力が [0, 1] の区間に美しく収まる、滑らかなS字型関数。 | 入力が大きすぎたり小さすぎたりすると、傾き(導関数)がほぼ0になる「勾配消失問題」が起きる。 | 深いネットワークでは使用を避け、ReLUなどを採用する。 |
| ReLU | max(0, x) | 入力が正ならそのまま出力。計算が非常にシンプルで高速。シグモイドに比べ勾配消失が起きにくい。 | 入力が負のときに勾配が完全に0になるため、ニューロンが更新されなくなる「死んだReLU問題」がある。 | Leaky ReLU、PReLU、ELUなど、負の領域にも僅かに傾きを残す工夫。 |
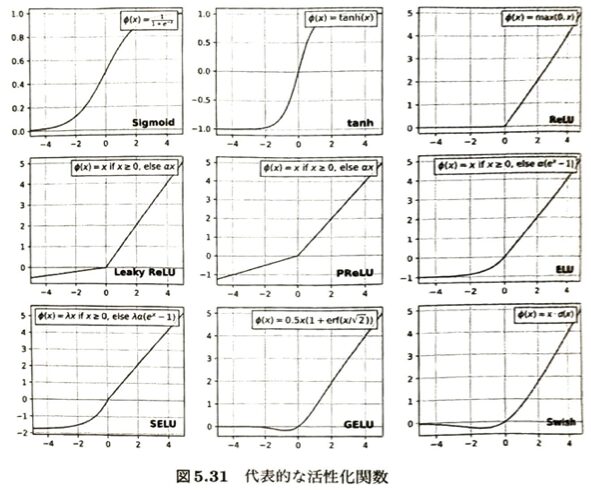
図5.31等に示されている、ReLUの弱点を克服した関数や、特定の領域で強力な効果を発揮する特殊な関数たちです。
| 関数名 | 負の領域( x<0 )の挙動 | 注目すべき特徴・メリット |
| Leaky ReLU | ax( a は小さな固定値) | 負の入力でもわずかに値を返すことで、「死んだReLU問題」を防ぐ。 |
| PReLU (Parametric ReLU) | ax ( a は学習データから最適化するパラメータ) | データの特性に合わせて、負の領域の傾きをネットワーク自身が自動で学習してくれる。 |
| ELU | α(e^x - 1) | 負の領域で滑らかに変化し、出力の平均値を0に近づけることで学習を安定化させる。 |
| SELU | λα(e^x - 1) | 適切な条件下で、ネットワークの出力を自動的に自己標準化(Self-normalizing)する。 |
| GELU | 確率的なアプローチによるカーブ | BERTなどのトランスフォーマーモデルで非常によく使われる高性能な関数。 |
| Swish | x・{sigmoid}(βx) | Googleが発見した関数。ReLUよりも滑らかな形状で、深層ネットワークで高い精度を出しやすい。 |
| tanh (双曲線正接関数) | -1 に近づくS字カーブ | 出力が [-1, 1] と、0を中心にバランスよく配置されるため、シグモイドよりも学習が進みやすい。 |
特定のパターン認識や、時系列・信号処理で局所的な特徴を捉えるために設計されたモデルです。
| 関数名 | 数学的アプローチ | どんな時に有効か(強み) |
| 動径基底関数 (RBF) (ガウス関数など) | exp(-‖x-c‖^2(/2σ^2)) | 中心点 c からの「距離」に応じて反応する。入力が特定のパターンに類似しているときだけ強く反応するため、パターン認識に有効。 |
| ウェーブレット関数 (モールウェーブレットなど) | cos(ωx)exp(-(x^2)/2) | 振動性と局所性を兼ね備える。時間と周波数の両方の解析が同時に可能なため、信号処理や時系列データの微細な変化の抽出に強い。 |
(確率的)勾配降下法とそのアルゴリズムを学びます。
| 用語 | 英語 | 定義・役割 | 覚え方・イメージ |
| 損失関数 | loss function | 予測値と理想値(正解)との間の「ズレ(誤差)」を集約して数値化した関数L(θ)。 | この関数の値を「最小化」することが学習のゴール。データセットが大きくなると計算コストが増大する。 |
| 学習率 | learning rate | パラメータを更新する際の「一歩の歩幅(ステップ幅)」を表す定数 η(エータ)> 0。 | 小さすぎる場合: 収束するが、更新回数が多くなり時間がかかりすぎる。 大きすぎる場合: 最小値を飛び越えて発散(振動)してしまう。 |
| 学習率スケジュール | learning rate scheduling | 更新の進捗(エポック数など)に応じて、学習率 η の大きさを動的に制御すること。 | 最初は大きく、ゴールに近づくにつれて歩幅を小さくしていくのが理想。 |
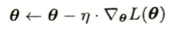
データの全件を使う「通常の勾配降下法(バッチ勾配降下法)」の課題を解決するために考案されたアプローチの比較です。
| 手法名 | 英語(略称) | 計算に使うデータ量 | メリット | デメリット・課題 |
| 勾配降下法 (バッチ勾配降下法) | Gradient Descent | すべてのデータ | 勾配の方向が安定しており、確実に関数の谷を進むことができる。 | データ規模が大きくなると、1回の更新にかかる計算コスト(時間・メモリ)が膨大になる。 |
| 確率的勾配降下法 | Stochastic Gradient Descent (SGD) | ランダムに選んだ1件 | 計算が非常に高速。データが1件ごとに変化するため、局所解(ローカルミニマ)を飛び越えて脱出しやすい。 | 1件ごとのノイズに影響されるため、勾配の挙動が不安定(ランダムにフラフラ進む)になりやすい。 |
| ミニバッチ勾配降下法 | Mini-batch Gradient Descent | 数十〜数百件のまとまり (ミニバッチ) | SGDの計算効率(高速さ)と、通常の勾配降下法の安定性をいいとこ取りしている。実務のデファクトスタンダード。 | GPUのメモリサイズに合わせて適切なバッチサイズ(16, 32, 64など)をチューニングする必要がある。 |
ミニバッチ法などをベースに、学習率や慣性を動的に制御する実用的なアルゴリズムの分類です。
| アルゴリズム名 | アプローチの特徴 | 狙い・強み |
| Momentum 法 | 過去の勾配の方向を「慣性(モメンタム)」として蓄積し、更新方向に加える。 | 物理的なボールが坂を転がり落ちるように、同じ方向への更新を加速させ、振動を抑える。 |
| AdaGrad | 過去に大きく更新されたパラメータの学習率を小さく、あまり更新されていないパラメータの学習率を大きく自動調整する。 | パラメータごとに最適な歩幅を設定するが、学習が進むにつれて歩幅が小さくなりすぎて止まる欠点がある。 |
| RMSProp | AdaGradの改良版。過去の勾配の影響を指数移動平均で徐々に減衰させる。 | 過去の古い勾配に引きずられることなく、直近の傾きに合わせて学習率を適切に調整し続ける。 |
| Adam | Momentum(慣性)の良さと、RMSProp(学習率の適応調整)の良さを組み合わせたハイブリッド手法。 | 現在のディープラーニングにおいてもっとも実用的かつ標準的に広く使われている。 |
「自動微分と計算グラフ」の重要なポイントを考えます。


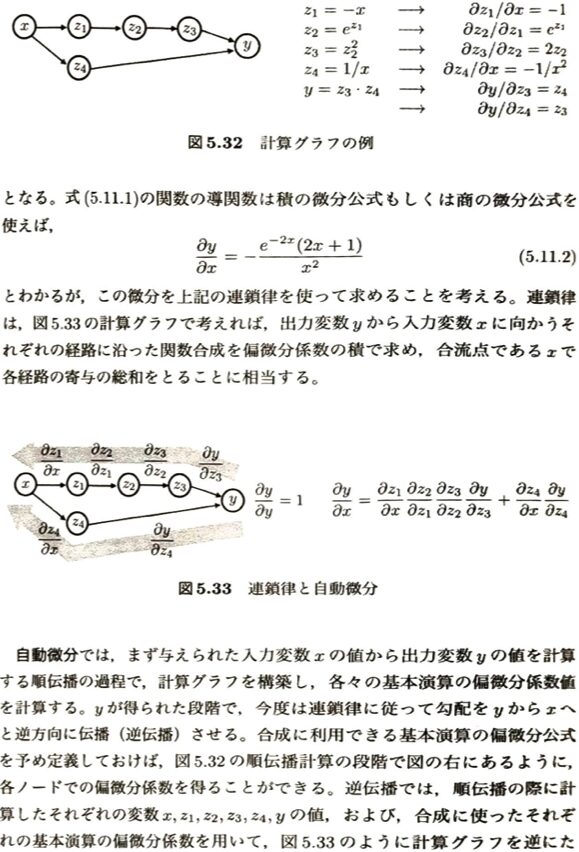

| 手法 | 特徴・計算の仕組み | メリット・デメリット |
| 記号微分 (Symbolic Differentiation) | 数式全体を手で微分するように、数式として展開する。 | 複雑な式では数式が爆発的に巨大化しやすい。 |
| 数値微分 (Numerical Differentiation) | 微小な値(極小の h)を使って数値的に近似する。 | 実装は簡単だが、桁落ちなどの誤差が含まれる。 |
| 自動微分 (Automatic Differentiation) | 計算の流れ(計算グラフ)に沿って、偏微分係数を逐次的に記録・伝播する。 | 正確かつ高速。深層学習の基盤技術。 |
自動微分の核心である「前向き」と「後向き」の決定的な違いです。試験でも非常によく問われるポイントです。
| モード | 計算の方向 | 特徴・効率的なケース | 深層学習での位置づけ |
| 前向きモード (Forward mode) | 順方向に計算 (入力の変化 → 出力の影響) | 入力次元(パラメータ数)が少ないときに効率的。 | あまり使われない。 |
| 後向きモード (Backward mode) | 逆方向に計算 (出力 → 各入力への勾配) | パラメータ数(入力次元)が多いときに圧倒的に有利。 | 誤差逆伝播法(バックプロパゲーション)に対応し、深層学習の主流。 |
| ステップ | 処理内容 | 具体的におこなっていること |
| 順伝播 (Forward) | 入力 x から出力 y を計算し、計算グラフを構築する。 | 各ノードの基本演算(加算、乗算など)の偏微分係数を予め定義・取得しておく。 |
| 逆伝播 (Backward) | 出力 y から入力 x へ、連鎖律(チェーンルール)に従って勾配を伝える。 | 順伝播で記録した中間変数の値と偏微分係数を用いて、数値的な積と和を繰り返して効率的に勾配を求める。 |
ニューラルネットワークは「出力は1個(損失関数の値)」に対して「パラメータは膨大(数百万〜数千億)」という極端な構造をしています。そのため、出力側から一気に1回で全パラメータの勾配を計算できる「後向きモード(逆伝播)」が自然に適合します。
第 i 層における各変数が「何を意味しているか」のまとめです。





数式がやっていることを「順伝播(計算)」と「逆伝播(誤差の伝播)」の2つに分解したまとめです。

最終的に「重み」と「バイアス」をどう修正するかを表した、一番実用的な部分のまとめです。


誤差逆伝播の例題を考えます






層が深くなるにつれて勾配が0に近づいてしまう「勾配消失」のメカニズムと、その対策となる活性化関数の特徴です。
| 活性化関数 | 導関数 ϕ′(x) の最大値 | 勾配消失の起きやすさ | メリット・デメリット・特徴 |
| Sigmoid | ≦0.25 | 🚨 非常に起きやすい | 層をさかのぼるごとに勾配が最大でも 1/4 ずつ減衰する。 |
| Tanh | ≦1 (0に近づきやすい) | ⚠️ 起きやすい | Sigmoidよりはマシだが、入力が中心から外れるとすぐ0に近づく。 |
| ReLU | = 1(x > 0 のとき) | ✅ 起きにくい | x > 0 では勾配が減衰しない。ただし、x ≦ 0 で勾配が完全にゼロになる「死んだReLU問題」がある。 |
| Leaky ReLU | 負の領域でも小さな傾きを持つ | ✅ 対策済み | 負の領域を完全にゼロにせず、わずかな傾きを残して「死んだReLU」を緩和。 |
| PReLU | 負の領域の傾きが学習パラメータ | ✅ 対策済み | 層ごとに最適な傾きをデータから自動で学習する。 |
| ELU / SELU | 負の領域で滑らかな指数関数 | ✅ 対策済み | 微分可能で勾配消失が起きにくく、学習が安定する。 |
| GELU / SiLU (Swish) | 複雑に工夫された関数 | ✅ 極めて起きにくい | Transformer(BERTやGPTシリーズ)で主流の高性能な関数。 |
ネットワークの学習を劇的に安定させる2つの超有名テクニックの比較です。
| テクニック | 解決する課題 | 仕組み(学習時) | 推論(テスト)時の挙動 |
| ドロップアウト (Dropout) | 過学習(オーバーフィッティング)の抑制 | 一定の確率(保持確率 p)でニューロンをランダムに無効化(出力を0に)して学習する。 | すべてのニューロンを使用する。 ※学習時とのスケールを合わせるため、出力を p 倍(または学習時に 1/p 倍)にする。 |
| バッチ正規化 (Batch Normalization) | 内部共変量シフトの軽減 (学習の鈍化・不安定化) | ミニバッチごとに、各層の出力を平均0、分散1に正規化する。さらに学習パラメータ γ, β でスケールとシフトを調整。 | 初期値や学習率への依存が緩和され、学習が劇的に高速化・安定化する。 |


データの特性(帰納バイアス)に合わせて設計される、ニューラルネットワークの基本構造の分類です。ネットワークの構造的な設計をアーキテクチャといいます。
| データの構造・種類 | 具体例 | データの持つ本質的な特徴 | 最適なアーキテクチャ |
| 構造なし(何でもあり) | 汎用的な数値データ | 特徴量の順番(隣接関係)には意味がない。 | 多層パーセプトロン(MLP) (全結合層の重なり) |
| 格子状の多次元配列 | 画像データ | 画素の並び順や2次元的な隣接関係が本質的に重要。 | 畳み込みニューラルネットワーク(CNN) |
| 系列データ (Sequence) | 音声、自然言語 | 単語や音響情報の時系列の前後関係が重要。 | リカレントニューラルネットワーク(RNN) 長短期記憶(LSTM) |

ニューラルネットワークモデル
CNNの根幹をなす、脳の視覚野の仕組みから着想を得た2つの処理のまとめです。
| 演算名 | 主な役割・特徴 | 脳の神経科学(視覚野)との対応 |
| 畳み込み (Convolution) | 画像からエッジ(輪郭)やパターンなどの空間的な特徴を効率的に抽出する。 | 特定の位置・方向・太さの線分に厳密に反応する「単純型細胞」に対応。 |
| プーリング (Pooling) | 位置のズレや歪みの影響を吸収し、データを扱いやすいサイズに微小変化に対してロバスト(頑健)にする。 | 入力パターンが少々ズレても反応する「複雑型細胞」に対応。 |
1960年代の基礎研究から、現代の深層学習のブレイクスルーに至るまでの歴史的な流れです。「年代・人物・モデル名・データセット」の組み合わせが大事です。
| 年代 | 提唱者・人物 | モデル名 / イベント | 概要・実世界での応用・意義 |
| 1960年代 | (神経科学の研究) | 細胞の受容野の局所性 | 視覚野のニューロンが特定のパターンに反応することを発見。(CNNの原点) |
| 1980年代 | 福島邦彦 | ネオコグニトロン (Neocognitron) | 視覚野の知見をベースに提案された、CNNの直接的な先祖となるモデル。 |
| 1990年代初頭 | ヤン・ルカン (Yann LeCun) | LeNet | 誤差逆伝播法で学習可能なCNN。手書き数字(MNIST)の認識に成功し、銀行の手書き小切手認識などに実用化。 |
| 2012年 | アレックス・クリジェフスキー ジェフリー・ヒントン ら | AlexNet (コンペ:ILSVRC) | 大規模画像認識コンペ(ILSVRC)で圧倒的勝利。世の中に「深層学習(ディープラーニング)」が広まる決定的な契機となった。 |
| 以降〜現代 | (多数の改良モデル) | VGG, ResNet, EfficientNet など | 画像分類だけでなく、物体検出(自動運転)、画像生成(GAN)、自然言語処理や医用画像診断など多岐にわたり活用。 |

畳み込みについて考えます。計算に登場する3つのデータの役割とイメージのまとめです。

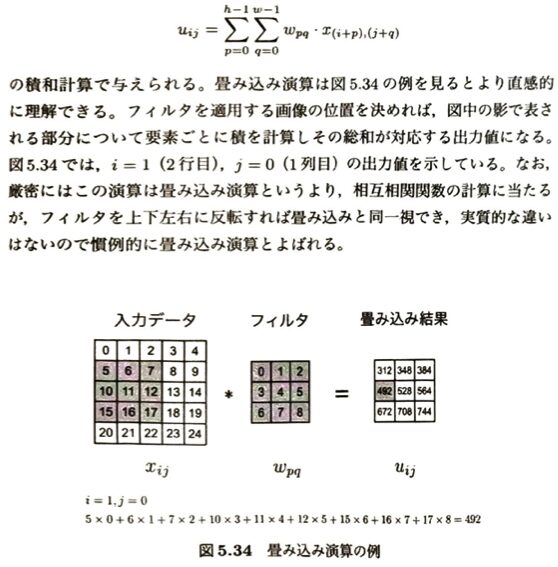


| 用語・概念 | 本質的な意味・違い | 試験対策のポイント(割り切り方) |
| 相互相関関数 | フィルタをそのまま(反転させずに)重ねてスライドする計算。 | 画像内の実際の計算(図5.34)は、数学的にはこの「相互相関」にあたる。 |
| 畳み込み(畳み込み積分) | フィルタを上下左右に反転させてから重ねてスライドする計算。 | 数学的な厳密さでは反転が必要だが、ディープラーニングにおいては「実質的な違いはない」ため、慣例的にどちらも「畳み込み」と呼ぶ。 |

パディングについて考えます。パディングを行う理由と、最もよく使われる手法のまとめです。
| 項目 | 内容・仕組み | なぜそれを行うのか?(目的・メリット) |
| パディングなし (Valid) | 画像の端からはみ出さない範囲だけでフィルタを動かす。 | 🚨 問題点: 端の画素の計算回数が少なくなり、さらに畳み込むたびに出力サイズが小さくなってしまう。 |
| パディングあり (Same) | 入力画像の外側に一回り「ふち(余白)」をつけて大きく拡張する。 | ✅ 目的: 畳み込みを行った後も、出力サイズを入力サイズと同じ(あるいは狙った大きさ)に維持するため。 |
| ゼロパディング (Zero Padding) | 拡張した「ふち」の画素値をすべて「0」で埋める手法。 | 最も一般的でシンプル。ただし、0が含まれることで出力される畳み込み値が小さめの値になりやすい点に注意が必要。 |
試験の計算問題で非常によく狙われる「出力サイズ」の決まり方です。
| 条件 | 出力サイズの計算公式 | 言葉での直感的な理解 |
| パディングなし | (H - (h - 1)) (W - (w - 1)) | フィルタのサイズから1を引いた分だけ、縦・横ともにサイズが縮む。 |
| サイズを維持する場合 (上下左右に均等にパディング) | 上下方向に幅(h - 1) / 2 左右方向に幅(w - 1) / 2のふちを足す | フィルタサイズ(h, w)が奇数のとき、この公式でぴったり入力と同じサイズをキープできる。 |

ストライドについて考えます。フィルタの「動かし方」を決めるストライドのまとめです。
| 項目 | 内容・仕組み | どんな時に使うか(目的・メリット) |
| ストライド (s) | フィルタを重ねてずらしていく際の「移動間隔(マスの数)」。 | * s = 1:1マスずつ地道に動かす(標準)。 * s > 1:2マス、3マスと飛ばしながら動かす。 |
| ストライドを大 (s > 1)にする目的 | 計算を意図的に粗くスキップする。 | データ量を削る「ダウンサンプリング」が目的。 のちに学ぶ「プーリング層」の代わりに、畳み込み層自体でサイズを小さくしたい時に大活躍します。 |


畳み込み層について考えます。

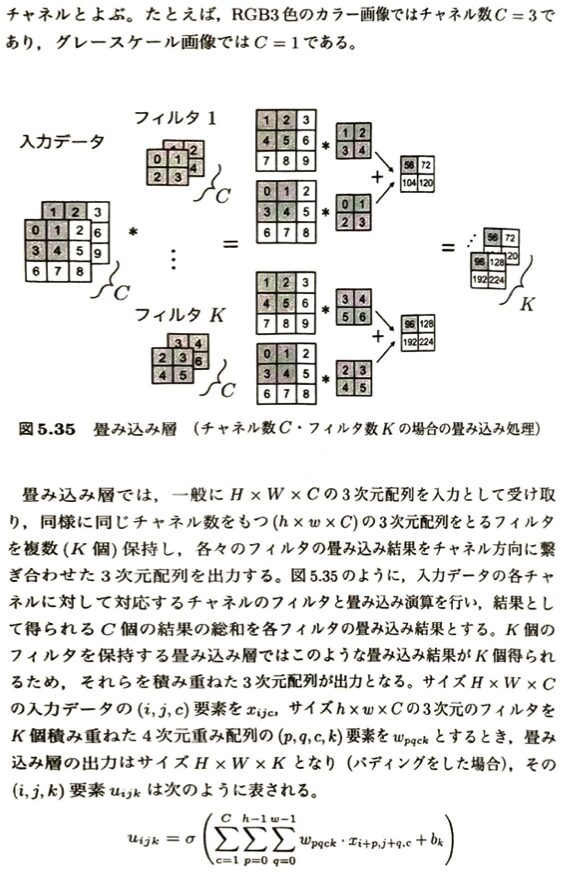
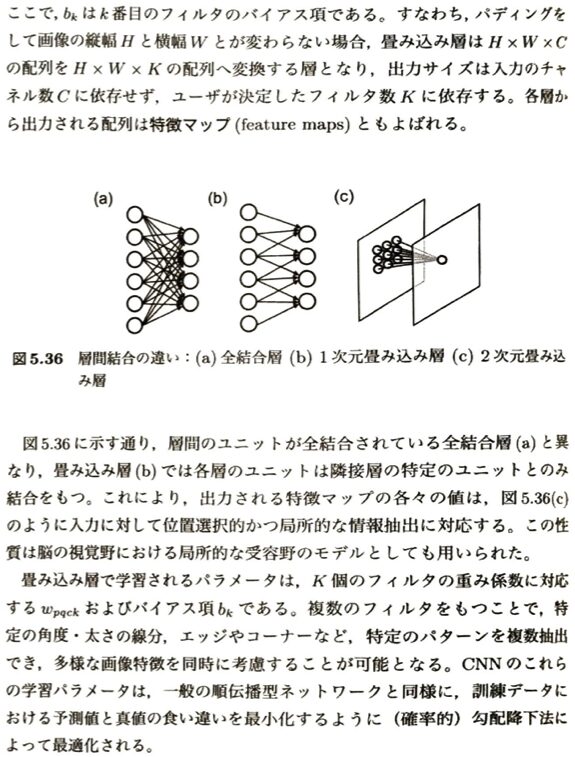
| 項目 | 概要・特徴 | 覚えておくべきポイント |
| 主な役割 | 入力データから特徴抽出を行う。 | CNNを最も特徴づける層。 |
| データの次元 | 入力:HWC 出力:HWK(パディングあり時) | 縦幅(H)・横幅(W)に加え、チャネル数の軸を持つ。 (例:RGBカラー画像なら C=3) |
| フィルタ(重み) | サイズ hwC のフィルタを K 個保持。 | フィルタのチャネル数は、必ず入力のチャネル数 C と一致する。 |
| 出力の決定要素 | 出力サイズ(特徴マップの数)は K になる。 | 出力チャネル数は、入力の C ではなくユーザが設定したフィルタ数 K に依存する。 |
| 学習パラメータ | フィルタの重み係数 w_{pqck} + バイアス項 b_k | 確率的勾配降下法(SGDなど)により、予測値と真値のズレが最小になるよう最適化される。 |
| 結合の特徴 | 局所受容野(全結合層とは異なる) | 隣接層の特定のユニットとのみ結合(図5.36)。位置選択的かつ局所的な特徴(エッジやコーナーなど)を抽出。 |


プーリング層を考えます。


| 項目 | 概要・特徴 |
| 主な役割 | ・位置への感受性を軽減(位置不変性の獲得) ・空間的なダウンサンプリング(サイズ縮小)による情報の段階的集約 |
| 畳み込み層との違い | 学習パラメータ(重み)が存在しない(計算規則が固定) |
| 処理の進め方 | 固定サイズのウィンドウをストライド(一定間隔)に従ってずらしながら演算 |


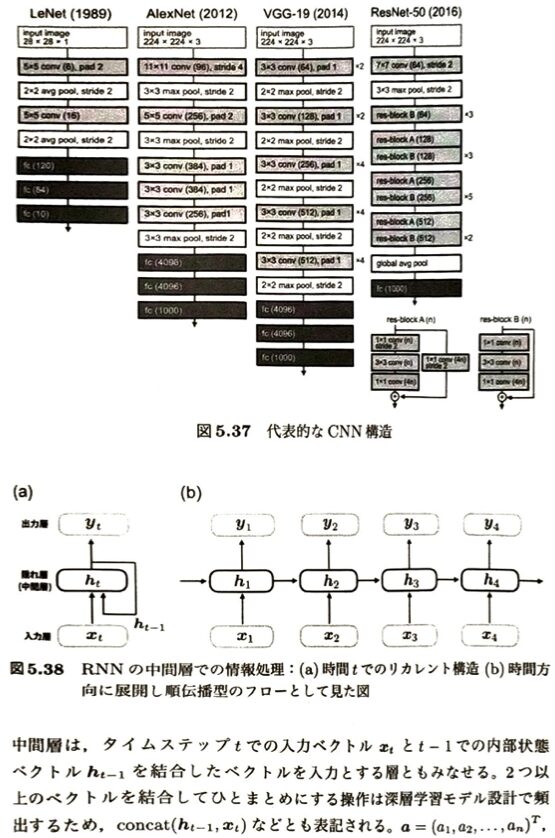
代表的なCNN構造を考えます。
| アーキテクチャ名 | フィルタサイズの特徴 | 主な構造・革新的な特徴 | 後のモデルや別技術への影響 |
| LeNet | (文脈上の基本型) | CNNの基本的な原型となるアーキテクチャ。 | すべての現代的なCNNの出発点。 |
| AlexNet | 大きな畳み込みフィルタから、徐々に小さなフィルタへと順に適用する。 | ILSVRC(ImageNetのコンペ)での活躍を機に、CNN設計の発展を下支えした歴史的モデル。 | ディープラーニングブームの火付け役。 |
| VGG | すべての層で 3 × 3 の小さな畳み込みフィルタに統一して処理する。 | フィルタサイズを固定し、層を重ねることで**さらに深い構造(深層化)**を実現。 | シンプルな設計ルールとして広く普及。 |
| ResNet | (ストライド畳み込みによるダウンサンプリングでプーリング層を廃止) | ・100層を超える超深層化を初めて可能にした。 ・残差接続(スキップ接続)という迂回路を導入。 ・バッチ正規化の利用。 ・大域平均プーリング(GAP層)で全結合層へ接続。 | 残差接続(スキップ接続)と正規化は、後の Transformerの設計にも継承 される必須要素となった。 |

CNNの次元について具体的に例題を考えます




他の例題も見てみます


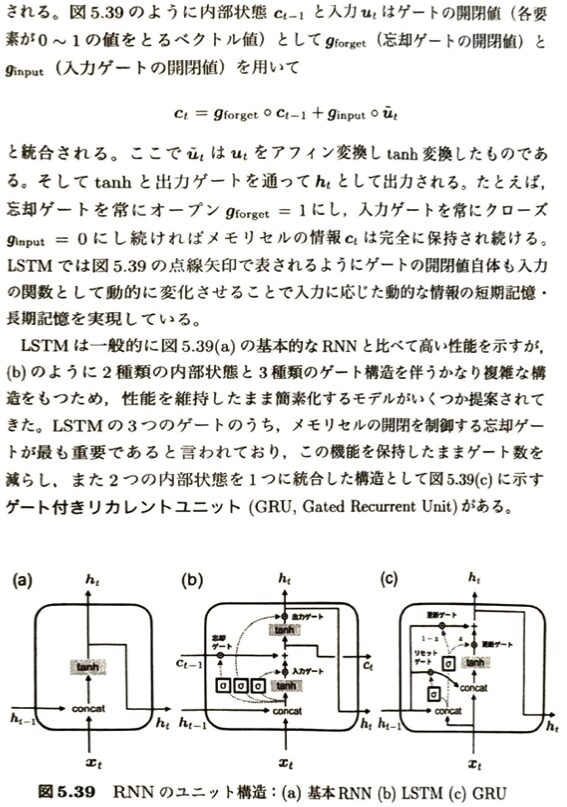
リカレントニューラルネットワークを学習します。


| 項目 | 概要・解説 |
| 対象データ | 時系列データ、テキストなどの系列データ( x_1, x_2, x_3, … ) |
| 最大の特徴 | 隠れ層(中間層)の出力が、再び次のタイムステップの入力として再利用されるリカレント(循環)構造。 |
| 内部状態 (h_t) | 過去の履歴を「内部状態(潜在変数)」として一時的に保持し、自己フィードバックさせることで、時間的な依存関係に応じた動的な振る舞いを可能にする。 |

| 項目 | 内容・メカニズム |
| 学習アルゴリズム | BPTT法(Back Propagation Through Time) ※時間方向にネットワークを展開し、通常の誤差逆伝播法を適用する手法。 |
| 直面する課題 | 勾配消失問題 長い系列(過去に遡る深い層)を扱う際、tanh やシグモイド関数の勾配(小さな値)が連続して掛け算されるため、勾配がほぼ0になってしまう。 |
| 実用上の限界 | 勾配消失により、入力を短期的に記憶することはできても、長期にわたる長い依存関係を学習することが困難である(現実的な限界)。 |

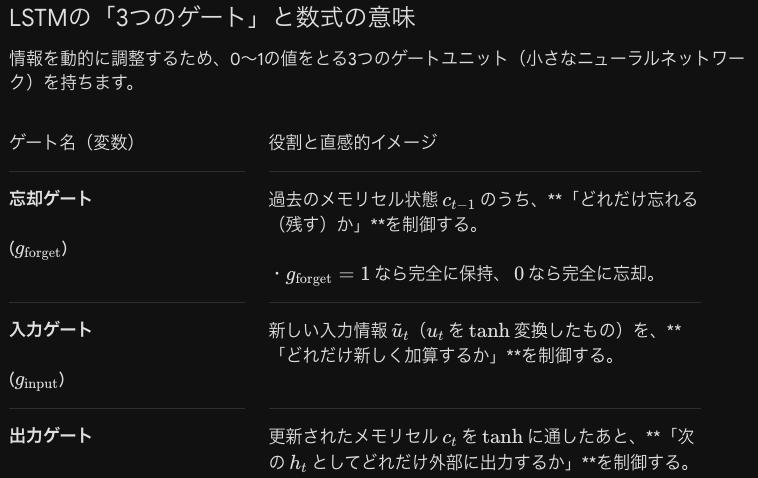
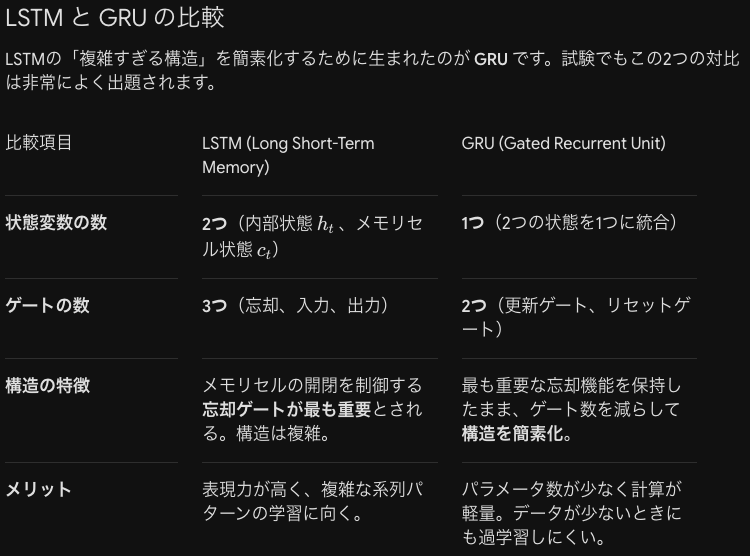
長短期記憶について考えます

| 項目 | 内容・メカニズム |
| 学習アルゴリズム | BPTT法(Back Propagation Through Time) ※時間方向にネットワークを展開し、通常の誤差逆伝播法を適用する手法。 |
| 直面する課題 | 勾配消失問題 長い系列(過去に遡る深い層)を扱う際、tanh やシグモイド関数の勾配(小さな値)が連続して掛け算されるため、勾配がほぼ0になってしまう。 |
| 実用上の限界 | 勾配消失により、入力を短期的に記憶することはできても、長期にわたる長い依存関係を学習することが困難である(現実的な限界)。 |


RNNの活用について考えます。
| 入出力の型 | 処理の特徴 | 具体的なタスク例 |
| Many to Many (同じ長さの系列) | 入力系列 x_t に対し、同じ長さの出力系列 y_t を得る。 各 y_t にソフトマックス関数を適用してクラス分類。 | ・音声認識(各タイムステップの音素分類) ・品詞タグづけ(各単語の品詞決定) |
| Many to One (系列から単一ラベル) | 入力は系列データだが、出力は系列全体に関する単一のラベル。 すべての情報が反映された最終状態 h_T(対応する出力 y_T)のみを利用して分類。 | ・感情分析(テキストから肯定的、中立的、否定的などを分類) |
| Many to Many (異なる長さの系列) | 入力長 T と異なる長さの可変長系列を出力する。 単一の基本構造では対応できないため、Seq2Seq などの拡張構造を用いる。 | ・機械翻訳(言語によって単語数が変わる) ・Speech to Text ・言語モデル(次の単語予測) |

| 時代・トピック | 概要 |
| 2010年代の隆盛 | 計算ハードウェア(GPU等)の発展や大規模データセットの整備により、大手IT企業(GAFAM等)の音声認識・自然言語処理サービス(Google翻訳、Siri、Alexaなど)の基盤技術として広く実用化された。 |
| 2017年以降のパラダイムシフト | 2017年に Transformer が登場したことで実用上の基盤技術が移行し、RNNモデルは徐々にTransformerへと置き換えられていった。 |

転移学習について考えます。

| 項目 | 概要・定義 |
| 転移学習とは | あるタスク(ソースタスク)で訓練された既存モデルの情報を、別の新しいタスク(ターゲットタスク)の学習に転用する手法。 |
| 位置づけ | 画像解析、音声認識、自然言語処理などの実問題への応用において、深層学習を非常に強力なものにしている大きな要因。 |
| ゼロから学習する場合の課題(理想と現実) | 事前学習済みモデルを利用した場合の解決策 |
| データの限界: 高い性能を出すには大規模なデータセットが必要だが、多様な個別の問題ごとに高品質なデータを大量に取得するのは困難。 | 少数の個別データでOK: すでに一般知識を大量のデータから学んでいるため、手元のデータが少量しかなくても高い精度でタスクを解くことができる。 |
| 計算資源の限界: 大規模モデルの訓練には、GPUクラスタなどの膨大な計算資源や分散計算環境が必要で、個人や個別ユーザーが実施するのは現実的に難しい。 | コストを大幅に削減: 公開されている高品質なモデル(例:ImageNetで学習されたCNNなど)を出発点にできるため、膨大な計算資源や時間を節約できる。 |
| 用語 | 意味・解説 |
| 事前学習済みモデル (Pretrained models) | すでに大規模なデータセット(例:ImageNetなど)で訓練を終え、特徴量の抽出能力などが備わっている公開モデルのこと。 |
| ファインチューニング (Fine-tuning) | 事前学習済みモデルをベースに、新しいタスクのデータを使ってモデルの一部分、または全体の重みを微調整(再学習)する転移学習の代表的な手法。 |

RNNについて具体的な例題を考えます




生成AIの基礎と展望
| 項目 | 識別型AI(従来のAI) | 生成AI(Generative AI) |
| 主な目的 | 入力をもとに「正しいラベルを当てる」こと。 | 新しい「データそのものを創造する」こと。 |
| データの解釈 | 与えられたデータの特徴を分類・予測する。 | 観測データの特徴を反映した新たなデータを自律的に生成する。 |
| 対象データの形式 | 数値、カテゴリ、限定的なテキストなど。 | 自然言語、画像、音声、音楽、プログラムなど多岐にわたる。 |

| アプローチ・分野 | 具体的な手法・概念 | 過去の限界と現代の突破口 |
| 統計学的な研究 | 未知の分布 P からの分布推定および抽出の手順。 | 昔:高次元性や文脈の長期依存性といった複雑な情報を適切に扱うことが困難で、高品質な出力には至らなかった。 現在:深層学習と大規模データの進展、および計算資源(GPU等)の飛躍的向上により、実用性が一気に加速した。 |
| 計算機科学的な研究 | 言語処理モデルにおける n-gram や マルコフ連鎖 による確率的生成。 |
| 技術・モデル名 | 登場年 | 主な特徴・メカニズム | 得意な分野・代表例 |
| GAN (敵対的生成ネットワーク) | 2014年 | 生成器(Generator)と識別器(Discriminator)という2つのニューラルネットワークを競い合わせることで、高精度なデータを生成する。 | 画像生成 (架空の画像生成、形式変換など) |
| Transformer (トランスフォーマー) | 2017年 | アテンション機構(注意機構)を採用。長い文章の中から重要な情報に注目できるため、文脈の整合性を保った生成が可能。 | 文章(言語)生成 (代表例:GPT、BERT) |
| 拡散モデル (Diffusion model) | 2020年前後 | 画像にノイズを加えていく過程を逆転(デノイズ)させることで、新たな画像を生成する。 | 画像生成 (GANと比較して安定した学習と高解像度な出力が可能) |

Transformerについて具体的な例題を考えます




スケーリング則について学びます。
| 項目 | 概要・解説 |
| スケーリング則とは | 大規模モデルの学習において、特定の要素を拡大することで、予測性能(テスト損失の減少)が滑らかに向上するという法則。 |
| 直感的イメージ | 「(モデルやデータを)大きければ大きいほど、賢くなる」という直感を理論的に支える根拠。 |
| グラフの特徴 | 縦軸(テスト損失)と横軸の両対数プロットにおいて、右下がりの直線(=冪乗的な減少)を描く。 |


「大きくすれば無限に賢くなる」わけではなく、実務上は以下のデメリットとのトレードオフになるため、単純な巨大化には限界があります。
| 課題・観点 | 巨大化に伴うデメリット |
| 効率性 | 学習コスト(電気代、サーバー代)が爆発的に高騰する。 |
| 環境負荷 | 膨大な電力を消費するため、CO2排出量などの環境面での批判や制約が生まれる。 |
| 推論速度 | モデルが大きくなると、ユーザーがプロンプトを入力してから回答が返ってくるまでの計算時間(推論速度)が遅くなり、実用性が損なわれる。 |

敵対的生成ネットワークについて考えます。
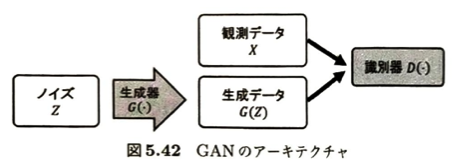
| ネットワーク名 | 入力 | 出力・目指すゴール | 直感的イメージ |
| 生成器 G(Z) (Generator) | ノイズ Z | 本物のデータ X と区別がつかないようなリアルなデータを生成する。 | 紙幣の偽造職人 (警察を騙せるレベルの偽札を作りたい) |
| 識別器 D(・) (Discriminator) | 入力された値(本物 X または偽物 G(Z)) | 入力データが本物( X ~P^ )である確率を出力し、本物と偽物を高精度に見破る。 | 警察・鑑定士 (偽札に騙されず、本物だけを見抜きたい) |

GANの得意な応用例と実用上の課題はこちらです。
| 項目 | 内容・解説 |
| 得意な応用分野 | ・架空の高品質な画像生成 ・顔画像の変換(年齢・性別の変更など) ・スタイル転送(写真から絵画風への変換など) |
| 実用上の重大な課題 | ① 学習の不安定性:2つのバランスが崩れると学習が破綻しやすい。 ② モード崩壊(Mode Collapse):生成器が特定の「ウケが良い(騙しやすい)」パターンばかりを生成し、出力の多様性が失われる現象。 |

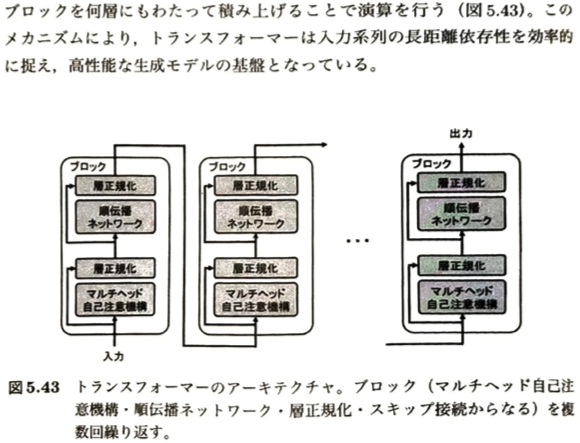
トランスフォーマーについて学びます。






拡散モデルを学びます。



基盤モデルを考えます。




プロンプトエンジニアリングを学びます。



| 手法名 | ざっくり言うと? | プロンプトの構成 | テキストの例(口コミ分類) |
| (i) ゼロショット (Zero-shot) | 例を出さずに、いきなり「これやって」と指示する。 | [指示] + [データ] | 「ポジ/ネガ/混合に分類して」+「料理は美味しかったが対応は失礼だった」 |
| (ii) フューショット (Few-shot) | いくつかの例(お手本)を見せてから、本番のタスクを振る。 | [例1, 例2...] + [データ] | 「雰囲気良い→ポジ」「料理冷たい→ネガ」という例を見せた後に本番を解かせる。 |
| (iii) Chain-of-Thought (CoT) | 「思考の過程(ステップ)も一緒に書いて」と指示し、複雑な推論をさせる。 | [思考プロセスの指示] + [データ] | 「その根拠となる思考過程も書いてください」と指示し、要素分解させてから最終回答(混合)へ導く。 |




マルチモーダルAIについて考えます。まずは視覚トランスフォーマーです。



次にCLIPです。


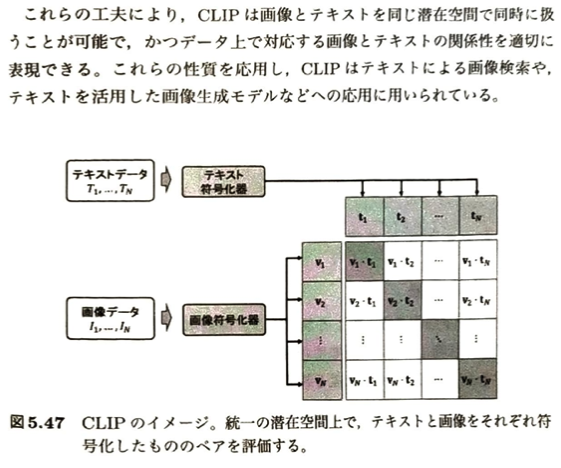


CLIPの具体的な例題を考えます



生成AIの革新と今後について考えます。
| 活用領域 | 具体的な活用例(テキストより) | 主なメリット・効果 |
| 創作支援 | 画像や文章の生成 | クリエイティブ活動の効率化、アイデア出しの高速化 |
| 教育支援 | 教材作成、対話による指導など | パーソナライズされた学習環境の提供、教員の負担軽減 |
| 医療 | 診療判断の支援、症状説明など | 医師の意思決定補助、患者への分かりやすい情報提供 |
| 法務・ビジネス | 契約書作成支援、議事録作成支援など | ルーティンワークの自動化、書類作成業務のスピードアップ |
| プログラミング | コード作成補助、デバッグ支援など | 開発効率の向上、エラー修正の迅速化 |
| 課題・リスク名 | テキストにおける定義・説明 | ざっくり言うと?(直感的イメージ) |
| 幻覚 (Hallucination) | 事実に反した出力を、それとは知らずに出力する現象。 | AIがそれっぽい嘘(もっともらしい誤情報)を堂々とついてしまうこと。 |
| 差別的出力 | 人種、性別、宗教などに関する差別的な出力を生成する問題。 | 学習データ内の偏り(バイアス)を反映し、不適切な表現を出してしまうこと。 |
| 権利の扱い | 学習データに含まれる創作物の権利(著作権など)の扱い。 | 他人の作品を勝手に学習に使ったり、似たものを出力して著作権を侵害するリスク。 |
| フェイクニュース | 生成AIによる偽情報生成に起因する危険性。 | リアルな嘘画像や嘘記事を悪意を持って大量生産し、社会を混乱させるリスク。 |

AIとロボット
AIとロボットの発展
ロボットが「身体」と「頭脳」を持って機能するための、ハードウェア・ソフトウェアの役割まとめです。
| 技術要素 | テキストにおける役割・具体例 | ざっくり言うと?(直感的イメージ) |
| 物理的身体(機械) | 産業用、サービス用、家庭用、ヒューマノイド、ペット、アシストスーツ、自動運転車など。 | 用途に合わせて作られたロボットの「肉体・メカ」そのもの。 |
| センサー | ロボットの感覚器を担う。 | 周囲の状況や自分の状態を目や耳のように「感じ取るパーツ」。 |
| アクチュエータ | モーターなど、駆動部に相当する。 | 電気や油圧などのエネルギーを、実際の動きに変える「筋肉」。 |
| 頭脳(基盤技術) | コンピュータの計算処理能力の向上、計算アルゴリズムの高度化、ネットワーク通信の高速化など。 | センサーの情報を処理し、どう動くかを瞬時に判断する「脳と神経」。 |
| IoT (Internet of Things) | 機械がデータを共有しながら作動する環境。 | 複数のロボットやシステムが通信で繋がり、協力して働くためのインフラ。 |
試験でも非常によく狙われる、シーケンス制御とフィードバック制御の決定的な違いのまとめです。
| 制御方式 | テキスト内の定義 | テキストの具体例 | ざっくり言うと?(直感的イメージ) | 特徴・暗記のポイント |
| シーケンス制御 | 決められた順に各工程を実施する制御方式。 | 洗濯機: 「洗う」 → 「脱水」 → 「乾燥」の順にこなす。 | あらかじめプログラムされた手順を、順番通りにひたすら実行する。 | ・途中で状況が変わっても、基本はお構いなしに進む(一本道)。 |
| フィードバック制御 | センサーで周囲の状態を推定し、目標状態に一致するように操作量を少しずつ修正しながら動きを作る。 | ロボットの手先移動: 目標物体の位置をセンサーで計測し、位置が変わっても手先が追従する。 | 現在の状態(現実)と目標(理想)を常に見比べ、ズレをその都度直しながら動く。 | ・センサーによる「微調整(修正)」がセット。目標に柔軟に追従できる。 |
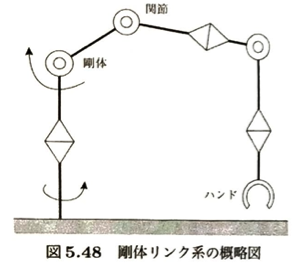

ロボットの「関節の角度」と「手先の位置」のどちらからどちらを計算するか、という双方向のトピックです。




| 概念 | テキスト内の数式・定義 | 入力 → 出力 | ざっくり言うと?(直感的イメージ) | 特徴・解の性質 |
| 順運動学 (Forward Kinematics: FK) | r=f(θ) | 関節角度 θ ↓ 手先位置 r | 「関節をこの角度に曲げたら、手先はどこにいく?」を計算する。 | ・幾何学的に一意に(1通りに)決まる。 ・計算自体は比較的簡単。 |
| 逆運動学 (Inverse Kinematics: IK) | θ=f^{-1}(r) | 手先位置 r ↓ 関節角度 θ | 「手先をこの位置に持っていきたいとき、関節はそれぞれ何度に曲げればいい?」を逆算する。 | ・非線形方程式になり、解くのが難しい。 ・解が存在しない、または複数(無数に)存在することがある。 |
位置の関係式 r = f(θ) を時間微分することで、「速度(動き)」の関係性へと発展させた領域です。


人間の身体運動計測について考えます。SLAMが解決する問題の本質と、ロボットに搭載されている主要なセンサーのまとめです。

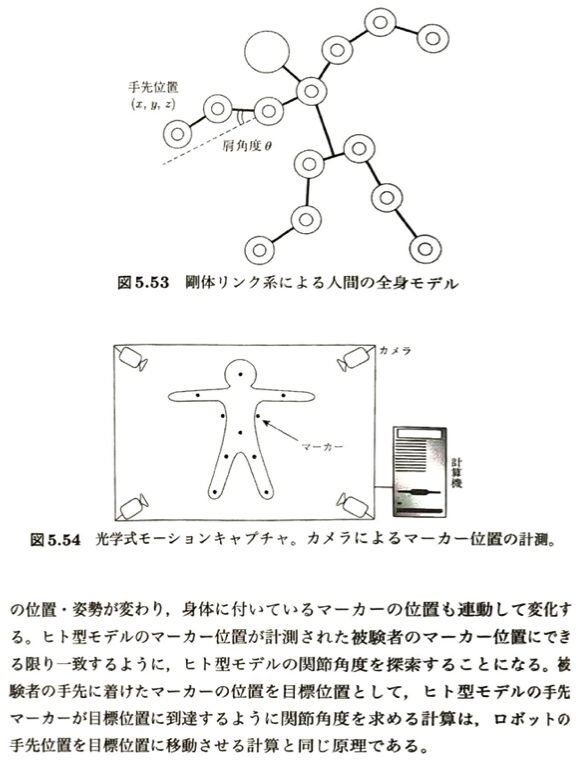
| 項目 | テキストにおける定義・説明 | ざっくり言うと?(直感的イメージ) | 暗記のポイント |
| 自己位置推定 (Localization) | ロボットが環境内で「自分がどこにいるか」を推定すること。 | 「私は今どこ?」 を知る。 | 地図がすでに正確なら簡単。 |
| 地図作成 (Mapping) | 周囲の環境の構造を記録して地図を作ること。 | 「周りはどうなってる?」 を記録する。 | 自分の位置が正確にわかっていれば簡単。 |
| SLAM | 自己位置推定と地図作成を同時(Simultaneous)に行う技術。 | 知らない場所に目隠しで放り出され、歩き回りながら手探りで間取り図を描くようなもの。 | 両方を同時にやるため、計算が複雑でズレ(誤差)が溜まりやすい。 |
| 主要センサー | ・LiDAR(レーザー) ・カメラ(Visual SLAM) | ロボットの「目」に相当するパーツ。 | カメラを使ったものは特に Visual SLAM(vSLAM) と呼ばれる。 |
テキストの「図5.52」や解説にある、蓄積する誤差をキャンセルするための2つの手法の比較です。
| 手法名 | テキスト内の特徴・仕組み | ざっくり言うと?(直感的イメージ) | メリット・デメリット |
| (i) フィルターベースの手法 (拡張カルマンフィルター、粒子フィルターなど) | 過去のロボットの位置の「現在の推定値」だけを保持し、新しいセンサー情報が入るたびに逐次更新していく。 | メモ帳には「今ココにいるはず」という最新の1点だけを上書きしながら進む。 | ・メリット:計算量やメモリが少なくて済む。 ・デメリット:一度大きく間違うと、後から修正するのが難しい。 |
| (ii) グラフベースの手法 (グラフ最適化) | 過去のロボットの位置(軌跡)や見つけた目印(ランドマーク)を「ノード(点)」とし、その間の関係性を「エッジ(線)」としたグラフ構造(図5.52)を作り、全体の矛盾が最小になるよう一括で最適化する。 | 通ってきた道や見つけた壁のつながりをクモの巣のようなネットワーク(グラフ)にしておき、後から全体を引っ張って綺麗に形を整える。 | ・メリット:ループクローズ(元の場所に戻ったとき)などで、過去のズレを一気に綺麗に修正できる。 ・デメリット:データ量が増えると計算が重くなる。 |

人間の行動を理解するAIについて考えます。ロボットが物体に触れて動かす際の基礎となる力学・幾何学的なアプローチのまとめです。


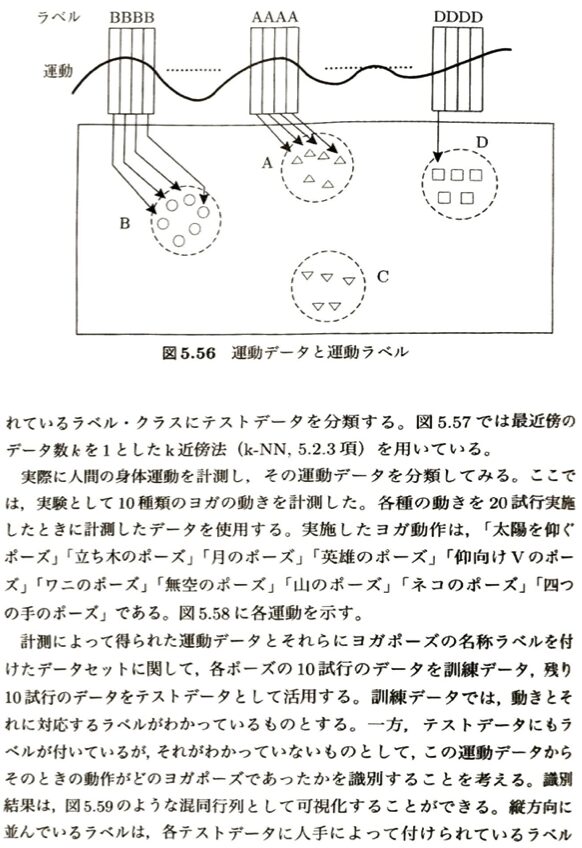


| 概念・用語 | テキスト内の定義・数式 | ざっくり言うと?(直感的イメージ) | 特徴・暗記のポイント |
| マニピュレーション | ロボットが環境(物体など)に能動的に接触し、その状態を変化させる行為。 | ロボットアームや手を使って、物を持ち上げたり動かしたりする操作全般。 | 知能ロボットの最終ゴールの1つ。 |
| 形状閉鎖 (Form closure) | 物体の動きが、接触する指の幾何学的な配置(形状)だけで完全に拘束されている状態。 | 指でガチッと囲んでいて、どんなに強い力で引っ張られても隙間から絶対に抜けない状態。 | ・力に関係なく、形だけで決まる。 ・カギがかかった箱のような状態。 |
| 力閉鎖 (Force closure) | 指が物体に及ぼす接触力の合成(摩擦を含む)によって、外力に対抗して物体を保持できる状態。 | 指の摩擦と押し付ける力を利用して、滑り落ちないようにうまくバランスを取って支えている状態。 | ・摩擦や押し付ける力の大きさが重要。 ・日常で物を持ち上げる時の大半はこれ。 |
| マニピュレータの動力学 | テキスト参照 | ロボットを動かすトルク(τ)と、各関節の動きや外力(f_(ext))との関係式。 | ロボットの関節をどう回せば、手先でどれくらいの力を出せるかを表す数式。 |
「どうやって物を掴むか」という計画を立てる際の新旧アプローチの決定的な違いです。
| アプローチ手法 | テキストにおけるアプローチ・仕組み | メリット | デメリット・課題 |
| (i) 解析的アプローチ | 物体やロボットの正確な3次元形状(CADデータ等)や物理特性(摩擦係数、重量)を事前に用意し、幾何学的・力学的な計算に基づいて最適な把持位置を計算する。 | 掴み方の力学的な安定性を、理論的に100%保証・評価できる。 | ・事前の正確なモデルが必要。 ・未知の物体や、形が複雑なものには対応できない。 |
| (ii) データ駆動型アプローチ (近年の主流) | カメラ画像や3次元点群(Point Cloud)をディープラーニング(CNNやViT等)に入力し、過去の膨大なデータから「掴めそうな位置(把持候補)」を直接予測させる。 | 物体の正確な形や重さがわからなくても、見た目の印象でなんとなく掴める(未知の物体に強い)。 | なぜその位置が良いと判断されたのか、力学的な根拠(説明性)を保証しにくい。 |
テキスト後半(図5.55・5.56)にある、AIに掴む場所をどう教えて、どう見つけさせるかという具体的な手法のまとめです。
| 概念・モデル | テキスト内の定義・数式 | ざっくり言うと?(直感的イメージ) | 処理の流れ・ポイント |
| 把持長方形 (Grasp Rectangle) | g = {x,y,θ,w,h} (中心座標、回転角、開き幅、指の長さ) | 2D画像上で、2本指のハンドが「どこを、どの向きで、どれくらい指を開いて掴めばいいか」を表す四角形枠。 | 3次元の難しい計算を、2次元画像の「バウンディングボックス検出」の問題に落とし込んでいる。 |
| Dex-Net | 仮想空間での大量のシミュレーション(物理計算)を通じて、「この画像(点群)の時はここを掴めば成功する」というデータセットおよび学習モデル。 | ロボットにバーチャル空間で何万回も掴む練習をさせ、「掴みやすさスコア」を予測する目を養ったシステム。 | 頑健な把持(Robust Grasping)を可能にした代表例。 |
| GraspNet | 物体の3次元点群を入力とし、3次元空間上でのハンドの6自由度(位置+姿勢)の把持ポーズを直接検出するエンドツーエンドのモデル。 | 3Dカメラのデータから、立体的に「この角度からこう手を突っ込めば掴める」を直接一発で当てるAI。 | 2次元の長方形(平面)から、3次元(空間)での直接検出へと進化したモデル(図5.56)。 |

AIの構築・運用
AIの学習と推論
| ステップ | プロセス名 | 概要・具体的な処理 | 補足・具体例(画像より) |
| 1 | タスクの設定 | 問題解決のために、AIに何をさせるかを決める。 | 画像認識(画像をインプットし、分類先のラベルをアウトプットするタスク)など。 |
| 2 | データの準備 | 学習に必要なデータセットを用意する。 | ImageNet:1,000万枚を超える画像、2万以上のカテゴリからなる教師あり学習用データ。 |
| 3 | 学習モデルの設計 | 可変なパラメータを持つネットワーク構造を決める。 | CNN(画像認識の代表例)、ResNet-50(2,000万超のパラメータを持つ大規模モデル)。 |
| 4 | 学習 | 訓練データをもとにアルゴリズムを動かし、最適なパラメータを決定する。 | 誤差逆伝播法(バックプロパゲーション)を用いて効率的にパラメータを更新。 |
| 5 | 推論 | 学習済みモデルに未知のデータを入力し、予測(分類)を行う。 | 推論時はパラメータの更新を行わない(学習時のパラメータをそのまま使う)。 |

AIの計算デバイスと開発基盤
| デバイス名 | 正式名称・分類 | 主な特徴・得意な処理 | テキスト内の具体例・用途 |
| GPU | Graphics Processing Unit | 並列計算処理が得意。もともとは画像描画用。深層学習の行列演算に非常に向いている。 | AIモデルやシステムの開発(学習)に広く利用。 |
| ASIC | Application-Specific Integrated Circuit | 特定の用途のために設計・製造された専用チップの総称。 | 深層学習の処理に特化した専用チップ全般。 |
| TPU | Tensor Processing Unit (※ASICの一種) | 行列・テンソル演算に特化。 | 深層学習のモデルの学習や推論を高速に行う。 |
| FPGA | Field Programmable Gate Array | 製造後に購入者が用途に応じて構成(書き換え)可能なチップ。 | モデルの推論の高速化や、エッジデバイスでの動作。 |
| 項目 | 概要・定義 | テキスト内の具体例・データ |
| スケーリング則 (べき乗則) | 以下3つの要素を増やすと、それに伴い**モデルの性能が向上する(損失が減少する)**という現象。 1. データセットのサイズ 2. モデルのパラメータ数 3. 計算資源(リソース)の量 | 大規模言語モデル(LLM)などは、この法則に基づき、膨大な計算資源を投入して開発されている。 |
| LLaMA の例 | オープンソースの代表的なLLM。膨大なリソースを投入した具体例。 | パラメータ数:650億 データ量:1兆4000万トークン 計算資源:GPU(NVIDIA A100)2048基 学習期間:約21日間 |
| ABCI (計算インフラ) | 産総研(産業技術総合研究所)が構築した、AI技術開発のための計算インフラ。冷却や電力設備を備えたデータセンターで運用。 | GPU(NVIDIA H200)を6128基、75ペタバイトの物理容量を持つストレージ等で構成。 |

AIシステムの開発・運用
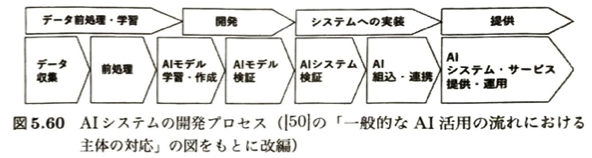
| 大工程 | 詳細ステップ | 概要・関連する重要キーワードやツール |
| データ前処理・学習 | 1. データ収集 2. 前処理 | AIモデルの元となるデータを集め、学習に適した形に加工する。 |
| 開発 | 3. AIモデル学習・作成 4. AIモデル検証 | PyTorch や TensorFlow などの深層学習フレームワークを使用。 ※これらは構造の記述、自動微分による勾配計算の自動化などの機能を持つ。 |
| システムへの実装 | 5. AIシステム検証 6. AI組込・連携 | 作成したAIモデルを実際のソフトウェア(AIシステム)に組み込み、連携テストを行う。 |
| 提供 | 7. AIシステム・サービス 提供・運用 | Hugging Face:事前学習済みモデルやデータセットが公開されているプラットフォーム。これを利用してWebサービスへの実装も簡単にできる。 |
| 仕組み(キーワード) | 目的・解決したい課題 | 主な機能・構成要素 |
| AutoML (Automated Machine Learning) | モデル開発における複雑な工程(前処理、特徴量設計、モデル選定、パラメータ調整など)を自動化し、迅速な開発を支援する。 | * ハイパーパラメータ最適化:膨大な組合せから最適な値を探索。 * ニューラルアーキテクチャ探索:ニューラルネットワークの最適な構造を探索。 |
| MLOps (Machine Learning Operations) | 実運用における課題(モデルの再現性、性能低下、管理・更新、説明性・解釈性など)に対処し、効率的に運用・維持管理する。 | * 継続的インテグレーション(CI):品質を保つ。 * 継続的デリバリー(CD):更新・デプロイを自動化。 * 継続的学习:性能低下を防ぐ。 * モデルの監視および管理 |

AIシステムの品質・信頼性
| 指針・ガイドライン名 | 策定・公開(年 / 組織) | 実現を目指す社会像 | 示されている主な原則・内容 |
| 人間中心の AI社会原則 | 2019年 内閣府 | AI-Readyな社会 (AI活用に対応した社会) | 人間中心、教育・リテラシー、プライバシー確保、セキュリティ確保、公正競争確保、公平性、説明責任及び透明性、イノベーション。 |
| AI事業者 ガイドライン | 2024年 総務省・経済産業省 | 人間の尊厳を守りながらAI活用による価値創出、社会課題解決を実現する社会。 | 上記の社会原則を土台にした、AIの開発・提供・利用における基本的な考え方や必要な取り組み(安全性・公平性・透明性の向上、アカウンタビリティなど)。 |
| アプローチ・対象 | 具体的な内容・配慮すべきポイント | 補足・重要キーワード |
| (1) 構成技術のバイアスへの配慮 | AIモデルを形作る各技術に潜む偏り(バイアス)を考慮する。 | 注28の対象範囲:学習データ、AIモデルの学習プロセス、プロンプト、推論時に参照する情報、連携する外部サービスなど。 |
| (2) 出力結果の公平性担保 | AIの出力によって人々が不当な差別や扱いを受けないようにする。 | ➔ 対策として、適切なタイミングで人間の判断を介在させる。 |


AIの社会実装
| 実装システム | 活用されているAI技術・プロセス | 具体的な機能・特徴 |
| スマートスピーカー (AIアシスタント機能) | * 人間の音声認識 * 言語処理(LLM等の基盤モデル) | 音声を認識し、連携する機器の操作、情報の検索、人間とのより自然な対話や指示の実行を行う。 |
| 自動運転システム (図5.61のプロセス) | 1. 認識:人工衛星・カメラ・センサ 2. 予測・判断:人工知能(AI) 3. 操作:アクセル・ブレーキ・ハンドル | 周辺環境の認識から、次にとるべき行動の予測・判断、実際の運転操作までの一連の活動をAIが代替する。 |

| 分野 | 活用されている技術 | 具体的な応用例・トピック |
| 幅広い産業 | 大規模言語モデル(LLM) マルチモーダル基盤モデル | 製造、流通、金融、ヘルスケア、インフラ、公共など。テキスト・画像・音楽・映像の生成(生成AI)により、教育や芸術など人間の創造性を必要とする分野にも導入。 |
| 科学研究 (バイオ・創薬) | 深層学習ベースのプログラム AlphaFold2(アルファフォールド2) | 2024年のノーベル化学賞の受賞功績。タンパク質の設計・構造予測を実現し、創薬などへの応用が期待されている。 |
| その他の科学分野 | 深層学習・AI技術全般 | 物質・材料開発、宇宙観測、気象、医療など。 |

最後にAIの最新のトピック(2026年6月現在)を例題として考えてみました






データサイエンスエキスパートの合格記事は下記です!


{kind=link}