
2026年6月8日にデータサイエンスエキスパート試験を受けて合格しました!
DSエキスパートの勉強方法は公式テキスト『データサイエンスエキスパート演習』を周回するだけで合格することは可能です。ただし本書は1章の重みがとてもあり、1ページの中でも行間が広いものも散見されます。そこで僕が勉強をしながら行間を埋めたり具体的な例題を探して解いたものもまとめて各章ごとの公式テキストの内容を過去記事にて消化してきました。
DSエキスパートの合格記事は下記をご参照ください!
他の合格者の方の声では、巻末の例題と模擬試験を何周もして合格した!という声も聞きます。そのため特に本書の第6章と第7章は大事な章なのだと感じます。しかし実際の試験が例題と模試と比べて難易度が高いか?と聞かれれば、もちろん難しい!と答えます。すなわち本書に登場する問題などは解ける状態にしておくことが望ましいということですね。
本記事では例題と模擬試験の内容を解いていき、特に難しい問題を自分なりに調べたものを行間を埋める形で考えていきたいと思います。また備忘録の役割も兼ねています。

例題と解説
統計基礎に関連する例題
t検定の分散の推定値は不偏分散のことを意味します。
この章は統計検定1級の統計数理と比べると難易度はかなり低めだと感じました。統計検定準1級と同等の感じです。
問題は全部で9問ありましたね!
数学基礎に関連する例題
こちらの章もテキストのインプットの章(第3章)と比べると難易度が低めの出題が目立ちます。本番については難易度がどうなるかわかりませんので、テキスト第3章を見直しておくことをおすすめします。
ちなみに問題は11問でしたね!
計算基礎に関する例題
この節の問題は8問でした。
基本的な内容をしっかりと理解することと、分野ではデータベースのSQLの文法はしっかりと把握しておくことが大事です。今回ははっきりと解らなかったのは1問でした。
'a'は文字列aという意味です。np.maximum(a,0)などきちんとした表記を覚えておかないと失点する例題があります。データベースでは複数行が返ってくるとエラーが起きることから不正解の選択肢を除外します。GROUP BYを用いると、例えば男女の場合は、返す行が2行以上になります。
モデリング・AIと評価に関連する例題
カルマンフィルタは線形動的システムの状態を逐次推定するアルゴリズムでノイズを含む測定値からシステムの真の状態を推定し、時間とともに推定を更新できる手法です。カーナビのGPS位置補正、自動運転、飛行機の軌道制御などで用います。マルコフ連鎖モンテカルロ法は、複雑な多次元上の確率分布をサンプリングする際に用いられる手法で、対象の確率分布を均衡分布にもつマルコフ連鎖を作ることによってサンプリングを行います。ベイズ統計学でのパラメータ推定、機械学習、物理学のシミュレーションなどで用います。
n個の主成分において第m主成分までの寄与率の和は最低でもm/nです。xの影響を除いたyとzの偏相関係数は、xを説明変数とし切片を含んだ単回帰分析で、yとzをそれぞれ目的変数としたときの残差同士の相関係数のことをいいます。TransformerはEncorder(データから特徴を抽出します)とDecorder(出力を生成します)を用いています。GPTはDecorderのみで、CNNやRNNやBERTはEncorderのみです。
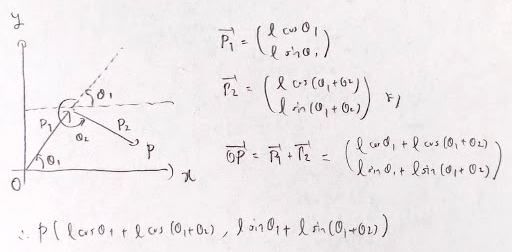
この節では問題が5問あって全部解けてましたね!
そうですね。しかしこれは例題だからそんなに難しくないのだという気持ちを持つことが大事です
複合問題
一般にrankA=rankA(T)=rankA(A(T))です。左に裾が長いとき、分布は左に歪んでいます。これは平均値が左にずれるためです。次のハノイの塔の問題は以下のやり方の方がシンプルです。


Pythonにおいて[0]*Nとは0という文字列をN個作れという意味です。回帰分析において線形結合で表される新たなzなどを加えても決定係数は変わりません。






PythonではURLのアドレス部とパラメータ記述部の区切りは?文字です。複数のパラメータの区切り文字は&です。
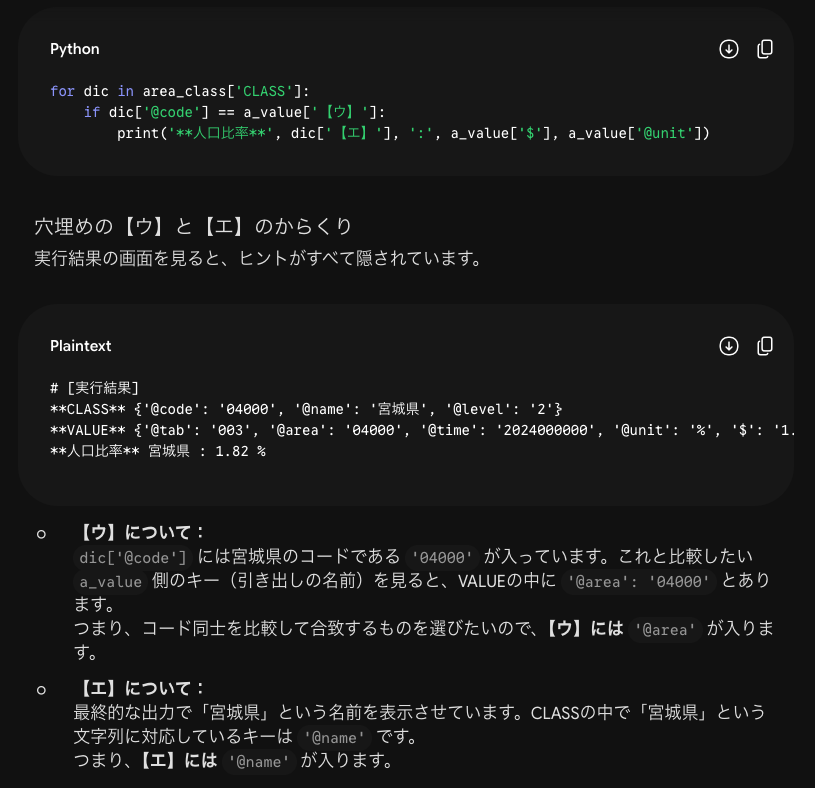
DSエキスパート試験ではこのような実装問題が出ます。今までにないタイプなので慣れるまで難しいですね。

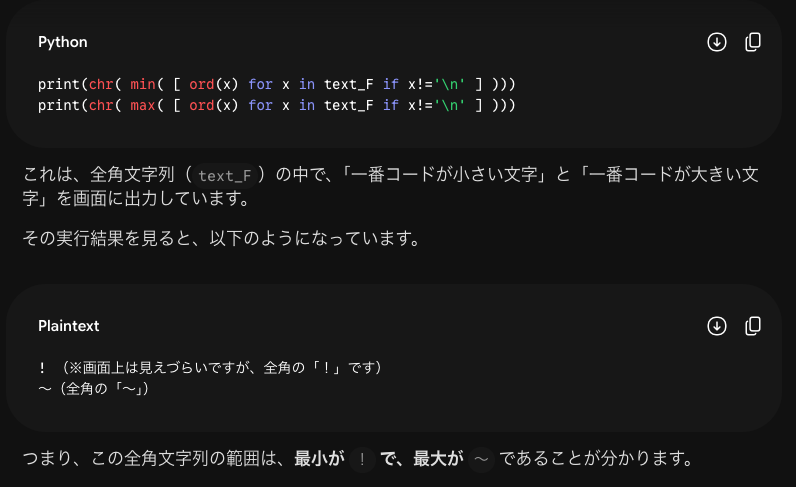


解説を読んでようやく理解できた問題です。試験本番で運が良ければ閃けるかも知れませんね。そのためには予想問題をしっかり把握して解いておくことが大事です
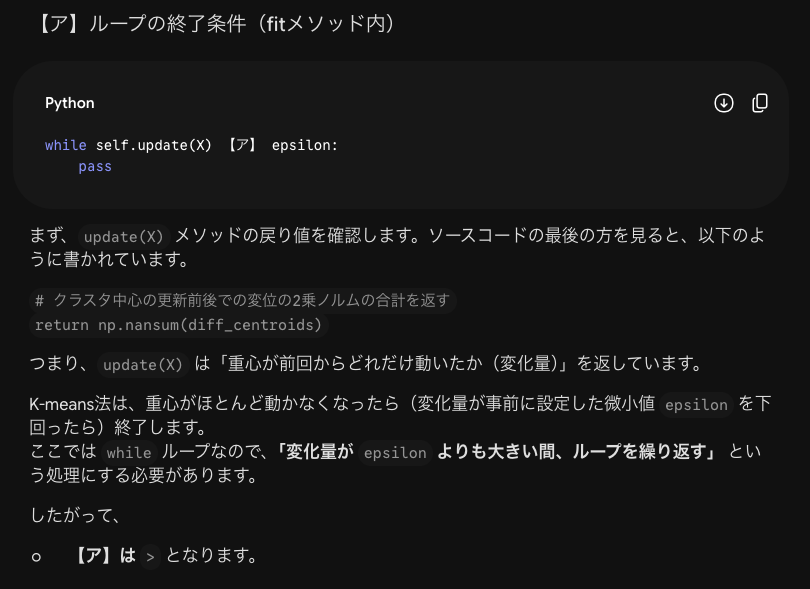
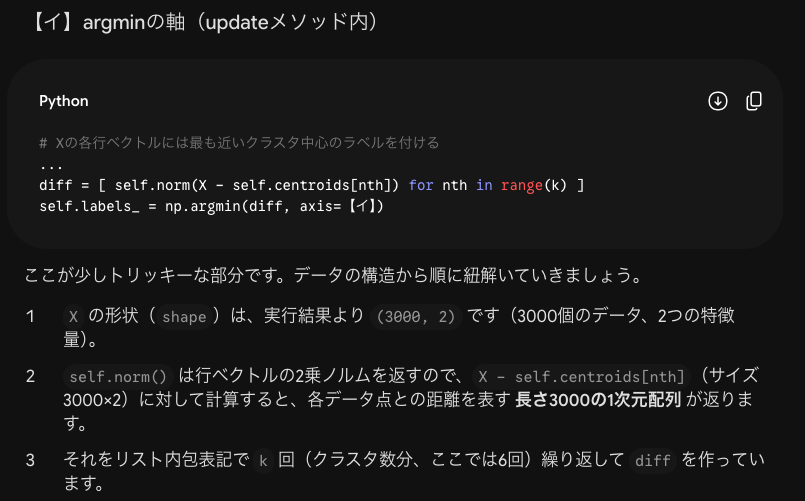
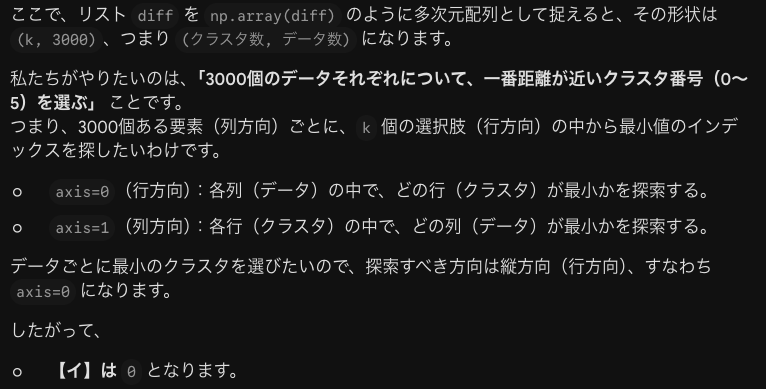
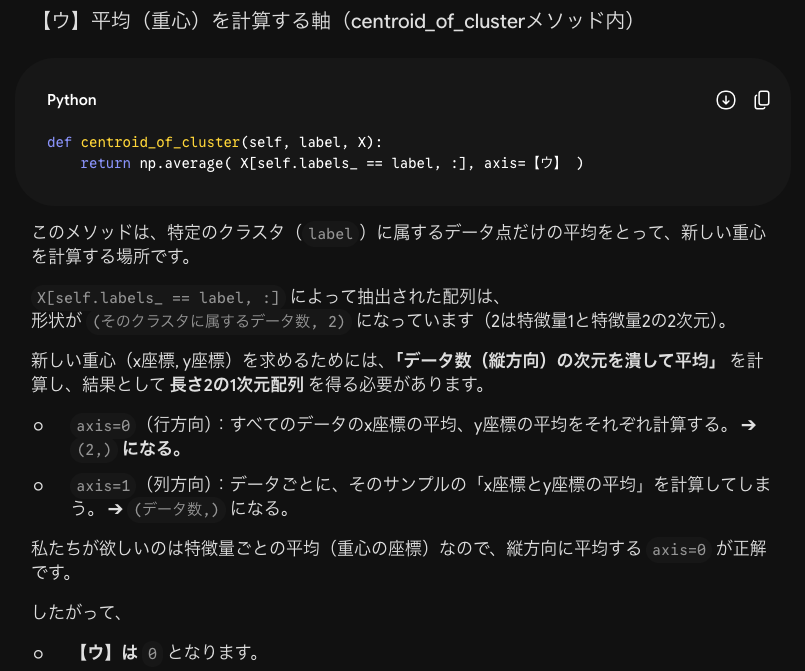
2つの軸のイメージが湧かないので具体的な数値で教えてください
了解です


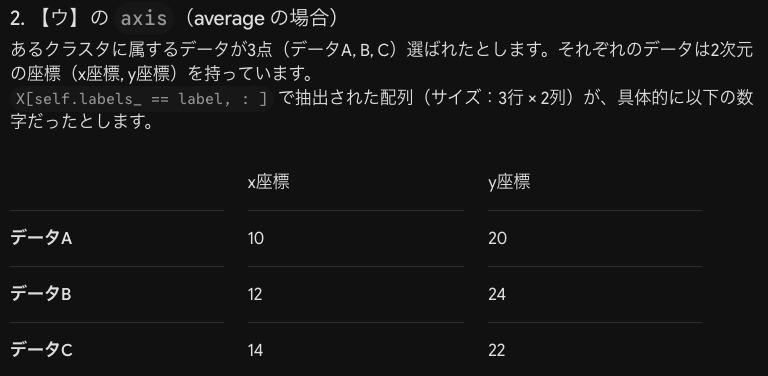


次は主成分分析のPython実装です。とにかく実装問題は慣れたいですね。
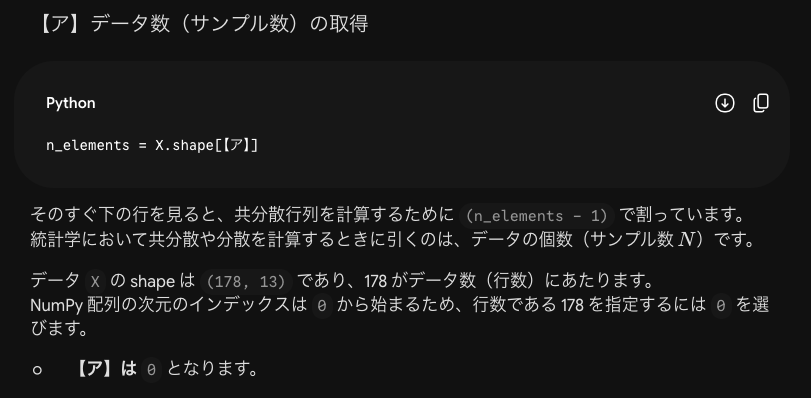
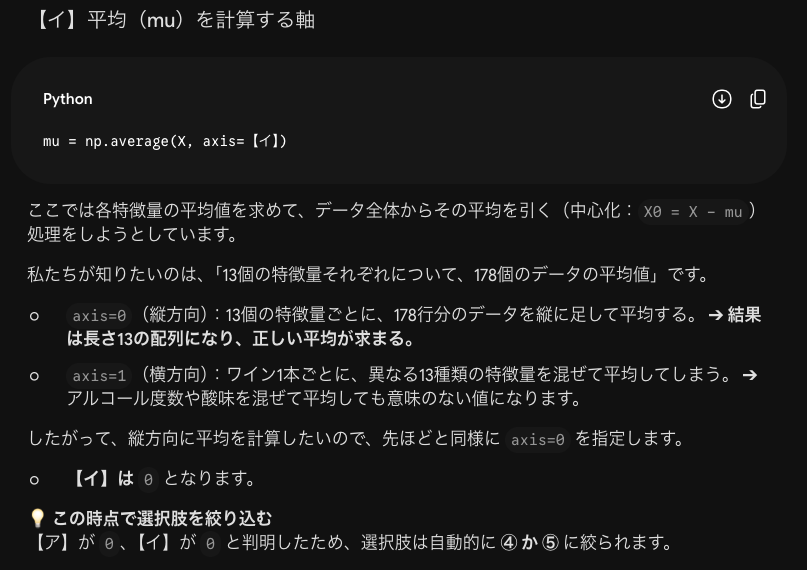
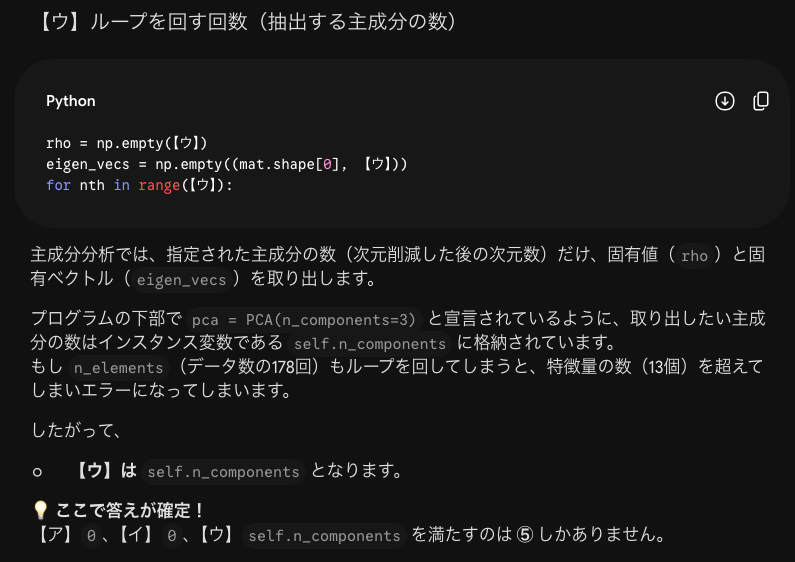
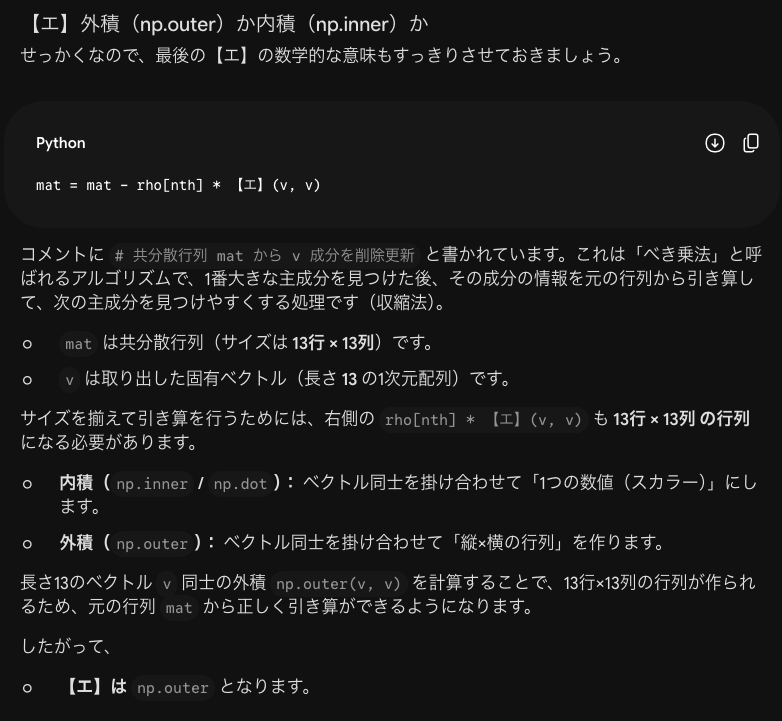
今回の複合問題では全部で21問あり13問できました。解けなかった問題はほぼPythonでの実装問題です
模擬試験問題
『データサイエンスエキスパート演習』の模擬試験を解いたら19/36でしてあと3問で合格点でした。これから復習を行います。
ABの計算オーダーはO(n^3)でABx(内積計算)のそれはO(n^2)です。

英語試験に男女で対応はないです。
国語と英語の男女別平均点は次のSQLで抽出します。


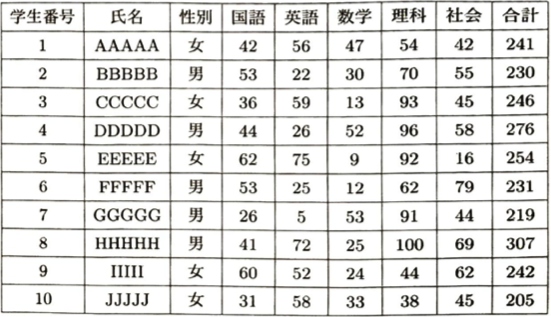
階級幅20点の度数分布表を考えると、次のようになります。
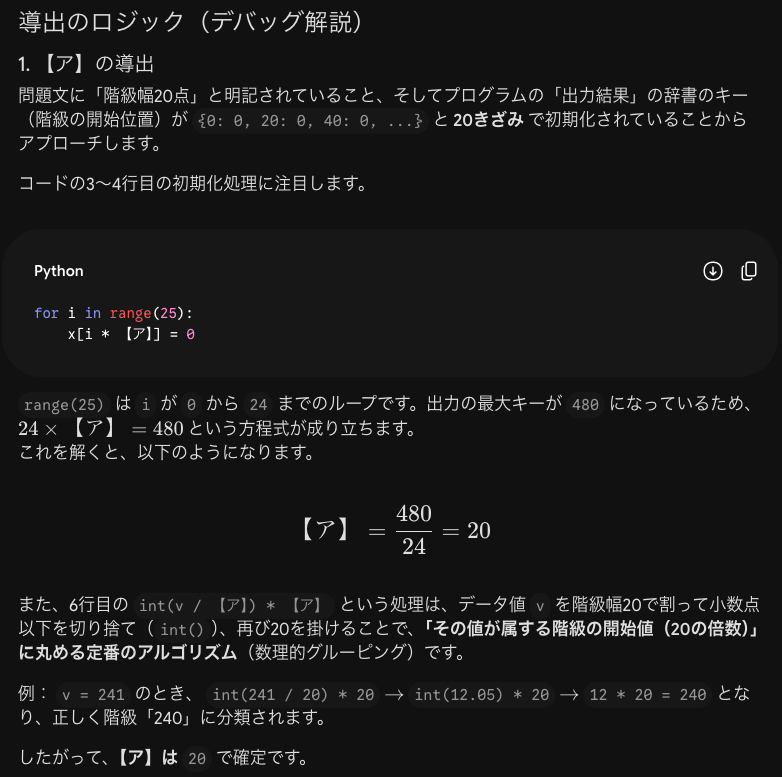
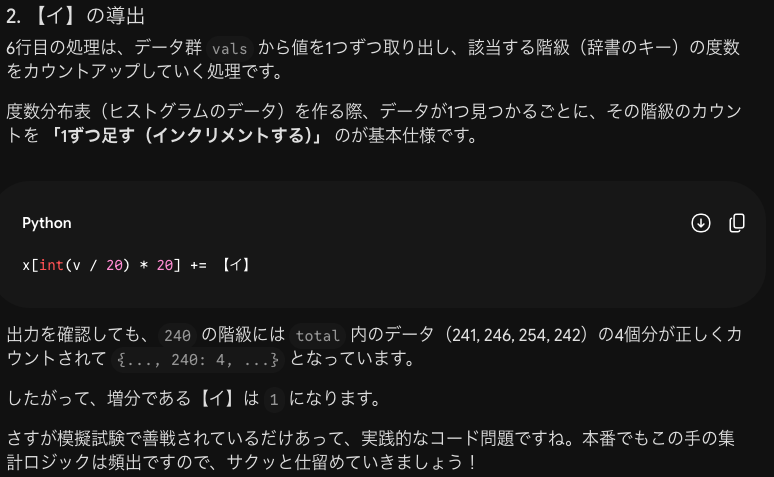

このコードと同じコードを返すコードは次のように考えます。

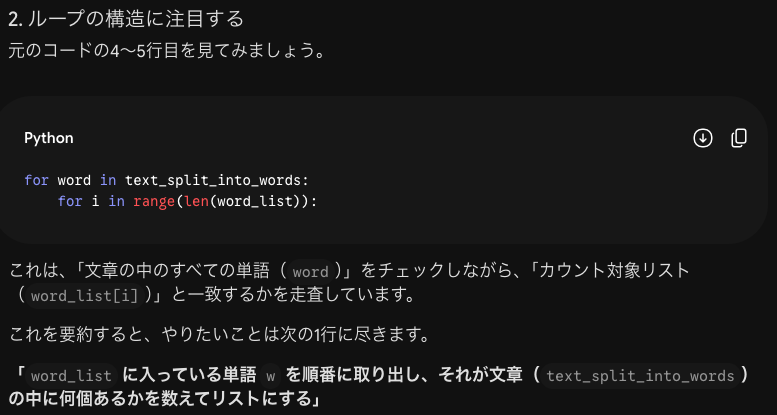

なぜ①や③がダメなのですか?
出力される長さが変わってしまうためです





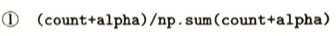
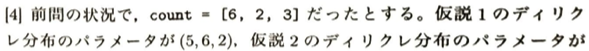


ここまでが前半です。今の問題がかなり難しいと思いますね。いよいよ後半です。







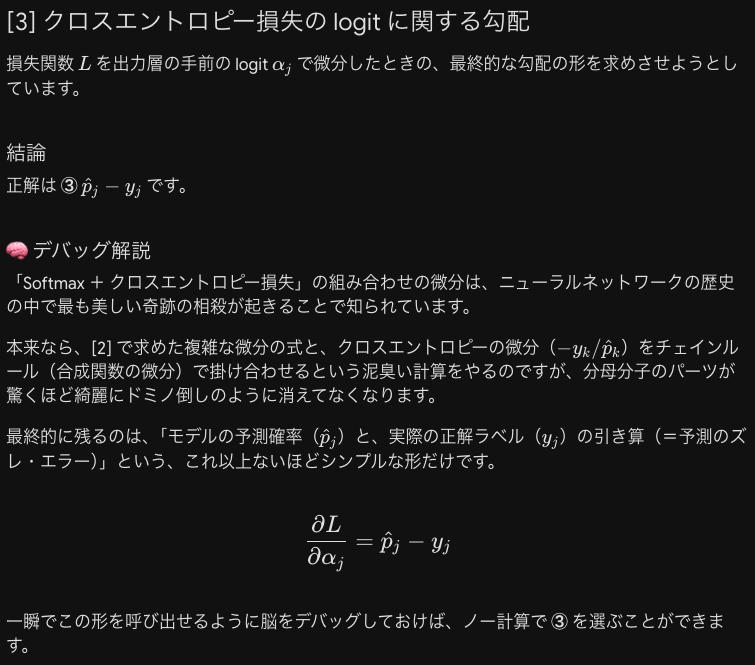
この問題は本質的にはHの逆行列を求める問題です。


これが模範解答ですがいまいち解らないので次のように考えます。



この問題が最難関だと思います。
t検定は平均の差を評価しますが、分類では分布の重なりが小さいことが重要であり、ばらつきが大きい場合には識別制度が低くなることがあります。サンプルサイズが少ないと過学習のリスクがあり、ジニ不純度が偶然の分割によって改善される可能性があります。ランダムフォレストは各決定木は異なるサブセットのデータを用います。過学習について比較的頑健性を持ちます。ブラックボックスではありません。






選択肢⑤はコライダーという引っ掛けです。これは覚えてしまうしかないです。それ以外はノードを消し去って考える考えでOKです。


なので答えは②です。


いかが別解です。







いよいよ最後の問題です。








失点部分って特徴がありますね!
そうなんです。SQLとPythonの問題です。ここをしっかりと固められれば合格点をこえることはできそうです!
本番直前の心得
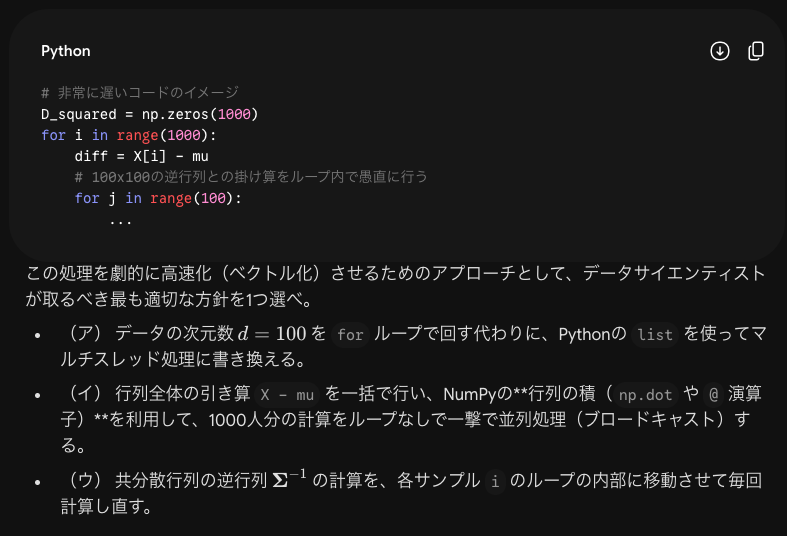
体験記によると「詰め込みはしたが当日の問題は地頭勝負の問題が多かった」という報告がありました。例えば次のような問題を予想します。




明日(2026年6月8日(月))はいよいよ15時からデータサイエンスエキスパート試験です。
当日の様子はこちらです。

{kind=link}