
2026年6月8日にデータサイエンスエキスパート試験を受けて合格しました!
DSエキスパートの勉強方法は公式テキスト『データサイエンスエキスパート演習』を周回するだけで合格することは可能です。ただし本書は1章の重みがとてもあり、1ページの中でも行間が広いものも散見されます。そこで僕が勉強をしながら行間を埋めたり具体的な例題を探して解いたものもまとめて各章ごとの公式テキストの内容を消化していきたいと思います。


確率と確率分布
確率分布、確率変数
k次モーメントが存在すればk-1次モーメントも存在します。

平均は1次モーメントで分散は2次の中心化モーメントです。3次の中心化モーメントを標準偏差の3乗で割った値は歪度です。歪度が正の時は右側に裾が長く引いている分布で、尖度は4次中心化モーメントを標準偏差の4乗で割った値から3を引いた値であり、尖度が正の時は両側に裾が長く引いているときです。
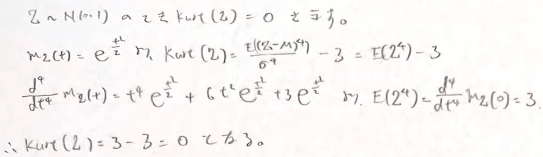
ここで標準正規分布の高次モーメントについて求め方をいくつか考えてみます。こちらはアクチュアリー数学では必須の結果となります。基本的にはゴリ押しをして求めると思うのですが、その他にもモーメント母関数による係数比較や、期待値の漸化式を考えて導出する方法もあります。

上の計算を漸化式という括りで考えたときの答案です。
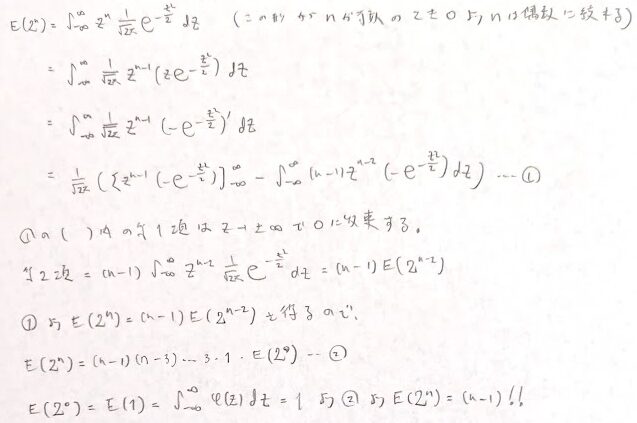
最後にモーメント母関数から直接求めるエレガント寄りの解き方を紹介します。
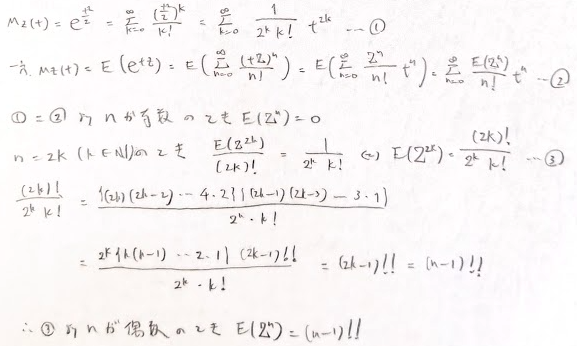
確率密度関数を横にα倍(α>0)としても歪度や尖度は変わらないことを証明します。
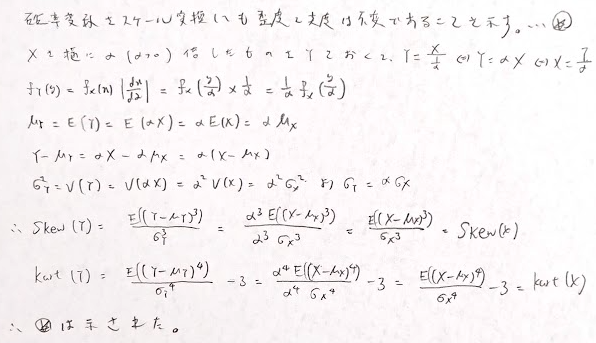
正規分布の積率母関数は次のように求めます。
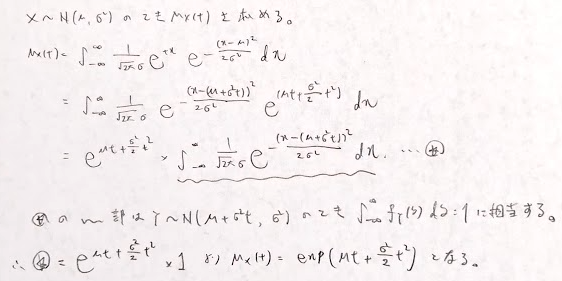
指数分布の積率母関数は次のようになります。
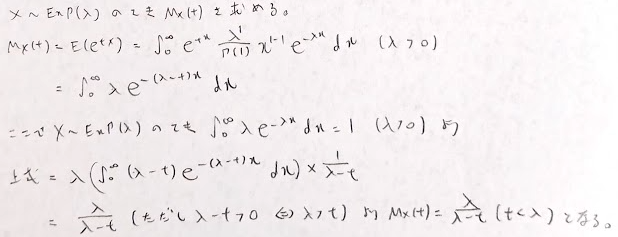
二項分布の積率母関数は次の通りです。
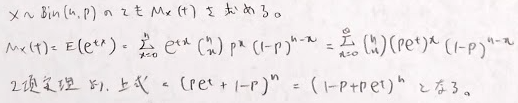
ポアソン分布の積率母関数は次のようになります。
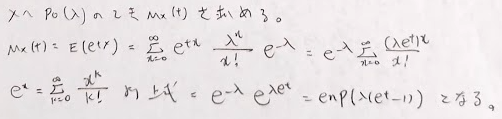
チェビシェフの不等式は分布の裾の確立を見積もるためのものです。その際には期待値と分散を用いることができます。
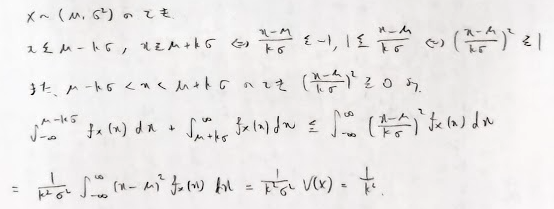
この結果の式を辺々1から引いて、例えばk=2を代入すると分布の平均から左右2標準偏差分の範囲に少なくとも0.75の確率が入ることもわかります。また、この式は久保川先生の著作である『データ解析のための数理統計入門』のチェビシェフの不等式と同値です。
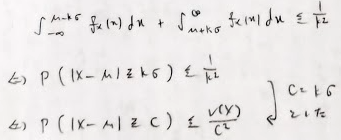

分布の再生性のときの記号を次のようにして表現します。
主要な確率分布
ベータ分布はベイズ統計において二項分布の共役事前分布です。ディリクレ分布は多項分布の共役事前分布です。ディリクレ分布はK個の選択肢がある状態で、ベータ分布は当たりか外れかの2択(二項関係)の状況です。つまり特定の一つの事象X_iに注目し、それ以外のすべての事象を、その他とまとめてしまっても、そのX_iの変動はベータ分布で記述できます。
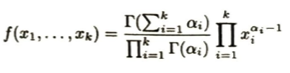
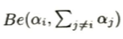
この証明は以下のように考えて(本質部分は積分範囲を0から1に変換すること)、注目するX_i以外を積分消去することで結果を得ることができます。
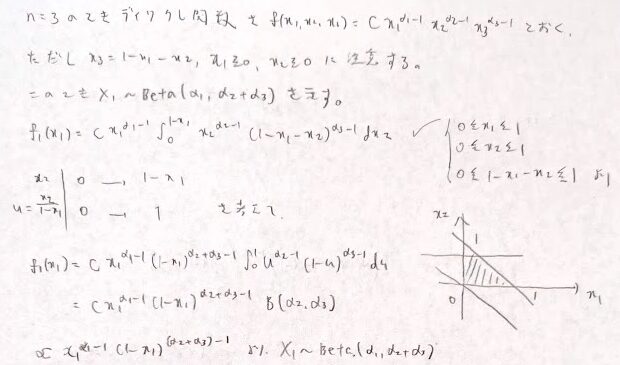
多変量の正規分布について、以下のように考えることにより条件付き分布を公式化できます。
強収束(概収)とはP(X_n→X)=1であり、このとき確率収束します。分布収束を法則収束ともいいます。このときP_nがPに法則収束するときPを漸近分布といいます。確率収束する法則収束します。つまり強収束するならば法則収束します。
大数の弱法則は標本平均と期待値の差の絶対値が任意のεより大きい確率はnを無限に近づけると0となる、つまり標本平均が期待値に確率収束することを言っています。これは推定量の一致性を示すときに用いられます。分散が存在するならばチェビシェフの不等式から示せますので以下に示します。
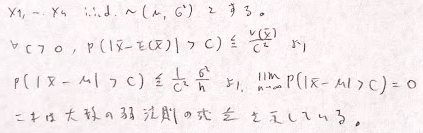
分散が存在しなくても期待値が存在すれば実は成立します。そして、さらに標本平均が期待値に概収束することを大数の強法則といいます。
推測統計
まずはオールワンズベクトルなどを用いて中心化をすることなどを復習しておきます。これは多変量解析における主成分分析の例であり試験範囲です。

標本分布
n個の標準正規分布に従う独立同分布の確率変数の和がΓ(n/2,/12)に従うことは、Z^2~Γ(1/2,1/2)を変数変換で示した後に再生性を用います。これを自由度nのカイ2乗分布といいます。
ヤコビアンの絶対値を用いた変数変換の公式で示そうとすると、今回は2変数間の関係が1対1でないので公式の使用ができません。以下のように分布関数を経由した証明になります。
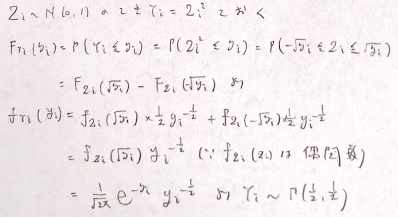
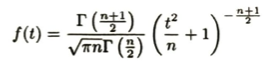
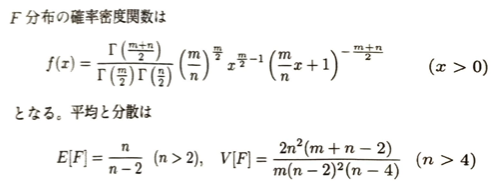
互いにn個の標本が独立同分布で正規分布に従う際に、標本平均と標本分散が独立で、標本分散は自由度n-1ののカイ2乗分布に従うことが以下より示ます。ここではヘルマート行列を経由せずにシュミットの正規直交化法を用いることで煩雑性を回避しています。(行列の転置は内部のベクトルも転置されることに注意します)
シュミットの正規直交化法は内積が定義された空間で線型独立なn本のベクトルが作れるときに成立する方法です。
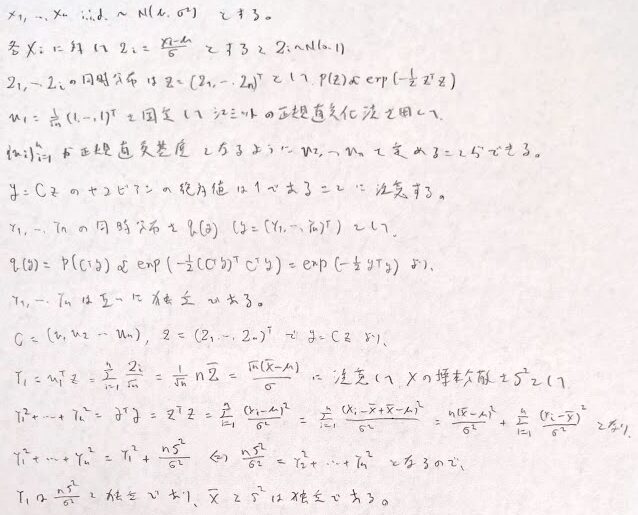
一般に相対誤差とは、真の値をA、測定値をaとしたときに|a-A|/Aと見積もります。母分散を不偏分散で推定する際にその精度の目安として相対誤差が用いられます。
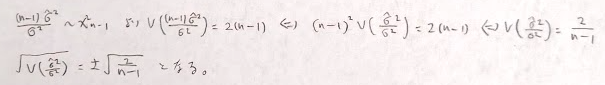
このことから母分散の推定量として不偏分散を用いることが検討できます。
順序統計量において、第i順序統計量X_(i)についてその累積分布関数を考えます。X_(i)≦xとなることは、n個の確率変数のうちi個以上がx以下となることと同値であり、n個の確率変数についてX_I ≦xとなることは確率F(x)がベルヌーイ試行であることから次のようになります。
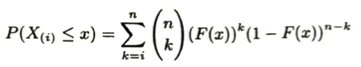
経験分布とは、n個の観測値を考えたときに各xに確率1/nを与える確率分布を考えることができます。経験分布の累積分布関数は次のようになります。高校数学では母集団分布と同じものです。
標本平均は各データからmを引いて2乗した和の最小値を与えるmです。中央値は、観測値を小さい順に並べてから、データからmを引いて絶対値を取った和を最小にするときのmです。このときの定義したものが高校生で習う中央値の求め方と一致しています。
点推定、区間推定
点推定において母数θを推定するために用いる統計量をθの推定量といい、その実現値をθの推定値といいます。
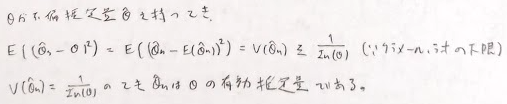
不偏推定量の中で分散をθに関して一様に最小にする推定量を一様最小分散不偏推定量と言われます。そのため有効推定量は一様最小分散不偏推定量です。しかし一様最小分散不偏推定量はクラメール・ラオの下限を達成できるとは限りません。
推定量の漸近有効性はn→∞のとき近似的に有効性を持つことをいいます。最尤推定量は正則条件のもとで漸近的に正規分布に従うため漸近有効性を持ちます。

信頼区間について例題を考えます


汎用的な検定
仮説検定において分割表の概念を導入できます。
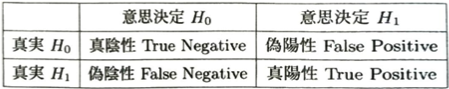
この考えによると対角成分の確率を上げて非対角成分の確率を下げたいです。母集団が正規分布に従うときは帰無仮説のもとで標準化を用いて考えていきます。p値が有意水準αより小さいときに帰無仮説を棄却すれば有意水準αの検定になります。標準誤差とは統計量の標準偏差の推定値です。

α=0のとき帰無仮説を棄却することができなくなり対立仮説は決して選ばれません。そのため帰無仮説が正しい時の第1種過誤の確率は0%ですが、対立仮説が正しい場合の第2種過誤の確率は100%です。反対にα=1とすると帰無仮説は必ず棄却され、いつでも対立仮説が選ばれます。このとき第2種過誤の確率は0%ですが、第1種過誤の確率は100%です。
有意水準αを定めて検出力1ーβを最大化する検定が良い検定です。ネイマン・ピアソンの補題は帰無仮説と対立仮説がそれぞれ特定の分布であるとき、尤度比に基づく仮説検定が検出力を最大にすることを主張します。

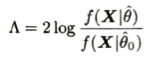
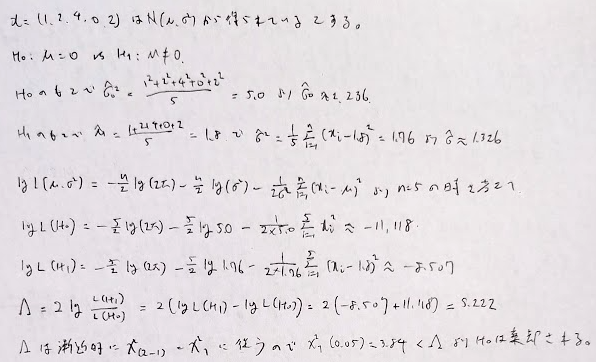
自由度計算について、対立仮説では期待値と分散の2つを考えますが帰無仮説では期待値が固定されているので分散の1つのみを考えるところから2−1=1と算出しています。
この例では正規母集団からの抽出でしたが正規分布を仮定しなくても尤度比検定統計量が近似的にカイ2乗分布に従う定理(ウィルクスの定理)は成立します。
次にノンパラメトリック法に移ります。まずはウィルコクソンの順位和検定です。公式を使わずに地道に検定したいと思います。

ウィルコクソンの順位和検定において両側検定が用いられるのは、この検定の目的が、2つのグループの分布が等しいか、それとも何らかの差があるか?を調べることにあるからです。
タイがある場合は、例えば1位が2個あれば1.5位が2個とする、例えば2位、3位、4位が同じ値だった場合は全員に(2+3+4)/3=3.0位を授けるなどと考えて同じように理論展開すればOKです。
それではタイがない場合で一般化してウィルコクソンの順位和検定の一般化を導いてみます。

次は2つの群に差があるか?を調べる並べ替え検定を行います。今回の例ではxとyが異なると主張するにはデータが不十分であるという結論になります。
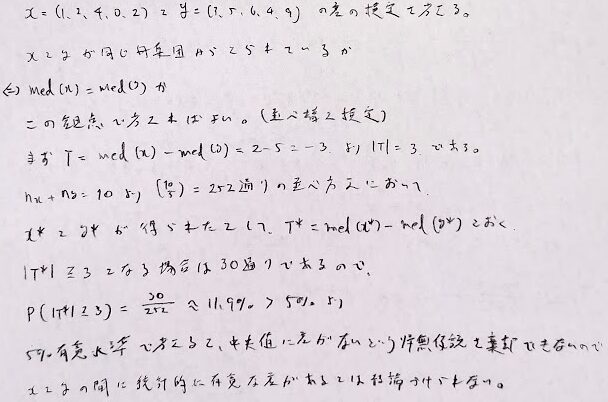
順位に意味がある場合は、数値を順位に置き換えてから並び替え検定を行います。これを順位検定と言います。先ほどの例は並び替え検定になります。また、Z_i=Y_i-X_iとおいて符号を考えて、正の符号となるiの個数(Sとおく)を考えると、それはBin(n,1/2)に従います。もし対立仮説が正の効果があるとのことであれば、棄却域をS>cとなる定数cをとれば良いです。nが大きいときはCLTを用いて考えます。これを符号検定といいます。先ほどの問題はnが大きいときは符号検定の考え方を適用できます。
実際にこの問題を符号検定(両側検定とします)で解いた結果は先ほどと同じ結論でした。しかしn=5と小さいときに正規近似を無理やり行なってしまうと有意になってしまうので注意です。
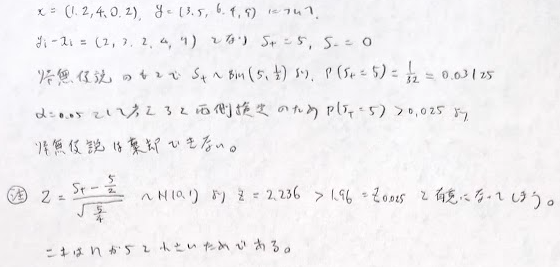
種々の検定
分散分析や適合度検定や独立性の検定もあります。
多重比較
多重比較ではボンフェロニの方法がありますが、これは保守的な方法で検出力が低いです。そのため改良したホルムの方法が使用されることがあります。そもそも多重比較は単純な二群の比較を繰り返してはならず全体の帰無仮説の検定の有意水準と矛盾しないような方法が採用されるべきです。

通常、多重比較を行う場合は分散分析を行い全体の有意性を確認します。その後にどこかに差があるとわかった時点で、では具体的にどこに差があるのか?を調べるのがボンフェロニ法です。ボンフェロニの不等式は1つ1つの2群の差がないt検定を行うときの有意水準の設定の妥当性を与えています。

ホルム法はk個の帰無仮設の検定統計量を計算し対応するp値を計算して小さい順に仮説を並べます。有意水準をα_1=α/k、α_2=α/(k-1)、α_3=α/(k-2)、…、α_k=αとして、p値が最も小さい帰無仮説をα_1によって検定します。その仮説が棄却されれば、2番目に小さいp値を持つ帰無仮説の検定に進み、有意水準α_2の検定を行います。順番に行い、もしある帰無仮説が棄却されなければ、それよりp値が大きい帰無仮説はすべて有意差なしとして、それ以降の帰無仮説を棄却しません。そのためボンフェロニの方法よりも棄却しやすくなり検出力が高くなります。その他には偽発見率という多重比較を用いることがあります。
| 特徴 | ボンフェローニ法 (FWER) | 偽発見率 (FDR) |
| 目的 | 全体で「1つも」間違いを許さない | 有意判定の中に占める「間違いの割合」を抑える |
| 厳格さ | 非常に厳しい(保守的) | 比較的緩やか(発見を優先) |
| 主な用途 | 少数の厳密な検定(臨床試験など) | 膨大な数の検定(ゲノム解析、マーケティング) |
ベイズ理論
頻度論的統計学とベイズ統計学の違いは統計モデルのパラメータの扱いです。頻度統計学のパラメータは定数と考えます。例え未知であっても確率変数でなく定数と考えます。ベイズ統計ではモデルのパラメータも観測値と同様に確率変数として考えます。パラメータの確率分布は頻度論的に分布の情報が得られる必要はなく、パラメータが未知であるような状況の見積りを表します。コインを投げる時の表が出る確率pについて、pについての分布がU[0,1]ならばpについての情報があまりなく、1/2に集中した分布ならばコインはほぼ歪みがないと見積もれます。
事前分布・事後分布

公式教材にはこの内容がはっきりと明記されていませんが、この内容を用いると以下の内容が導けます。
未知の確率密度関数q(x)からのサイズnの標本が得られたとき新たな観測値x_(n+1)を推定したいので、q(x)をパラメータθで決まる確率密度関数p(x|θ)で近似します。すなわちθを与えた(θの事前分布を考えている)ときx_(n+1)を得る確率に、下記のθの事後分布をかけたものをθで積分すれば良いのです。
未知の真の分布q(x)を直接知ることはできませんが観測データを通じてθのもっともらしい範囲を絞り込むことはできます。
事前分布と事後分布の概念が得られます。n個の標本が得られる前のθの事前分布がp(θ)とするとき以下の式を事後分布とします。
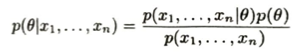
すなわちn個の標本の情報をパラメータθの見積に反映させて、これを使ってx_(n+1)の値を推定すれば良いのです。
θの積分における被積分関数は結局、尤度×θの事後分布の式になっています。ここでの尤度とは仮にパラメータがθだとしたら、未知のx_(n+1)が現れる確率はどれくらいか?というスコアを算出しています。
尤度とは、「観測された現実(データ)から、その背景にあるルール(パラメータ)を評価するための関数」なのですね!
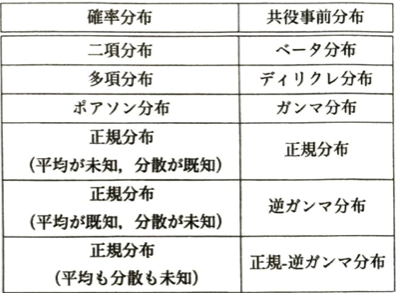












| データの確率分布(尤度) | 相棒となる共役事前分布 | 裏で起きている数理パズルの正体 |
| 二項分布(コイン投げ) | ベータ分布 | 表と裏の「出た回数」をそのままスロットに足し算 |
| 多項分布(多面サイコロ) | ディリクレ分布 | 各カテゴリの「出た回数」を個別に足し算 |
| ポアソン分布(アクセス数) | ガンマ分布 | k にはイベント総数、 μ には観測時間を足し算 |
| 正規分布(平均未知) | 正規分布 | 事前平均と標本平均を、精度(情報量)で綱引き(加重平均) |
| 正規分布(分散未知) | 逆ガンマ分布 | α にはデータ数、 β にはズレの二乗和を足し算 |
検定関数を導入してベイズリスクを考えます。今までは一つのモデルの中でパラメータθがどう動くかの事前分布を考えましたが、視点を一段階上げて「そもそも帰無仮説と対立仮説、どっちのモデルのが正しいのか?」というレベルから「もっともらしさ(確率)」を割り振ります。例えば裁判の前に被告が白(帰無仮説)である確率」と「黒(対立仮説)である確率」をとりあえず50:50と設定するイメージです。ここで帰無仮説が正しいとした場合、対立仮説が正しいとした場合、それぞれにおいてパラメータθが取る値の分布(ルール)を変えて設定します。

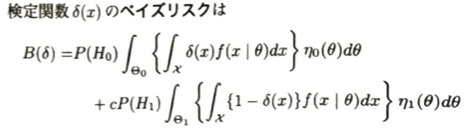
この式は検定を間違えたときに支払うコストの平均値(期待値)を表しています。

第二項で1-δ(x)としているのは、内側の積分において、1-δ(x)が0にならない範囲、つまり棄却されないxの範囲のみを積分したいからです。
次にベイズリスクの式を、データxが与えられた後の視点(事後的な視点))に切り替えて考えます。初めの式は、分母はxが得られる式ですが、それは帰無仮説を考えた時にxが得られる確率と、対立仮説を選んだ時にxが得られる確率の和です。分子はそれと同様の考えで出てきます。
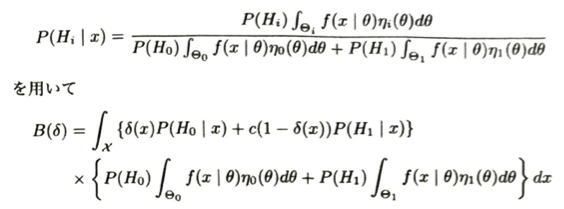
この下式は、ベイズリスクの積分をそれぞれ積分の順番つまりdxとdθを入れ替えることができる(フビニの定理などを満たせば)ことを用いて、入れ替えをした後で事後確率の式を代入すれば得られます。


例えばc=1のときは第一種過誤と第二種過誤の重みは同じということなので、事後確率がより高い仮説を採用する戦略がベイズ最適になります。

つまりc=1のときは単に「データを見た後に確率が高い方を信じる」という非常にわかりやすいルールになります。

単純仮説のときは事前分布はディラックのデルタ関数になります。

次に棄却ルールを事後確率の定義に沿って展開してm(x)で約分します。

この式を左辺に尤度比が来るように整理します。

これをP(H_0)のみで表現します。
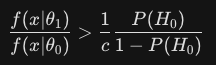
つまりデータから得られた証拠(尤度比)が事前に設定した壁(右辺)を越えたら帰無仮説を棄却して対立仮説を信じるというネイマン・ピアソンの基本定理のベイズ版のような式になります。
右辺の値が大きくなれば棄却のハードルが上がりますね。
この右辺はcの減少関数であり、P(H_0)の増加関数です。つまり有意水準を小さく取ると(すなわち滅多なことで帰無仮説を棄却しないということなので、右辺の値を大きくすることに相当します)、帰無仮説に強い信頼を置く、第二種過誤の第一種過誤に対する相対的な損失cが小さいことに対応します。ここまでは帰無仮説と対立仮説という二者択一の話でしたが、モデル選択に拡張することができます。
とても抽象度が高いので具体的な例題を考えます





計算統計
復元抽出において各要素を等しい確率で取り出すときの確率分布を経験分布といいます。このようにブートストラップ標本を得る操作を再標本抽出といいます。

は百分率点法はブートストラップ法によって得られた統計量を大きさの順に並べて下から2.5%の推定値と上から2.5%推定値を端点とする区間を考えて95%信頼区間を考える方法です。これはノンパラメトリックブートストラップ法になります。標準誤差の推定の場合はB=200で十分ですがブートストラップ信頼区間の場合はより高い精度を必要とするので1000以上のより大きな値が必要になります。ただしnが小さい場合はパラメトリック法の方がブートストラップ法を効率よく行えます。
パラメトリックブートストラップ法とは、例えばxが正規分布からの標本であると考えられる場合、まずxの平均値と分散の推定量を計算します。その後に推定したパラメータを持つ正規分布からブートストラップ標本をB個得て、そこからそれぞれに対する統計量を計算して得られた統計量の分布が得られるので、そうした統計量の精度を評価したり信頼区間を構成したりすることです。
しかし線形回帰モデルなどの場合は、応答変数yと説明変数xの組のデータを再抽出したブートストラップ標本に線形回帰を繰り返し適用する場合、重複を許す復元抽出により、すべてのxの要素が同じになる可能性があります。その場合に線形回帰モデルを適用することはできません。残差ブートストラップ法とは以下のように行い先ほどの懸念を解消する方法です。

その他にはより精度の高い信頼区間の構成法としてBCa法、指数分布族の場合により少ない負荷でBCa法を近似するABC法が開発されています。仮説検定もブートストラップ法によって行えます。またランダムフォレストはブートストラップ法を用いて決定木の不安定性を改善する効果があります。
サンプリングとは、ある確率分布が与えられたとき、それに従う確率変数の実現値を計算することです。データに基づく経験分布(高校数学でいう母集団分布のこと)は先ほどの内容で対応できます。疑似乱数は初期値(シート)を入力として受け取り、その値に基づいて数列を作成します。疑似乱数生成器には線形合同法(単純なアルゴリズムですが乱数周期が短く精度を必要とする計算には不向きです)やメルセンヌ・ツイスタ(非常に永井周期を持つので広範な分野で使用されます)などがあります。基本的にこれらによって一様乱数U[0,1)を生成できます。逆関数法などを用いて様々な確率分布に従う乱数を生成できます。棄却法はやり直す回数がかさむため比較的低速ですが、汎用性・信頼性が高く設計しやすいことが魅力です。
M>0に対してすべてのxでp(x)≦Mq(x)を仮定します。そしてq(x)に生成する乱数xとU[0,1)に従う一様乱数u作成して、u≦p(x)/(Mq(x))となるxを採用し、そうでない場合は棄却して繰り返します。するとxはp(x)に従う乱数となります。
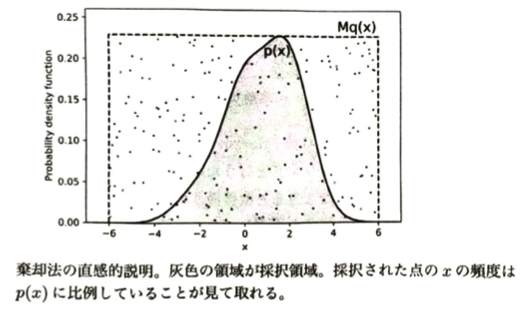
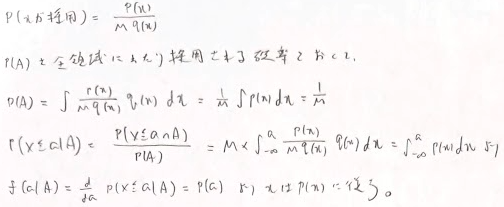
これにより定数Mが大きいと棄却される割合が増えて効率が悪くなります。MCMC(マルコフ連鎖モンテカルロ法)は複雑な確率分布からサンプリングを行う強力な手法です。これはマルコフ連鎖を利用します。MCMCの利点は目標分布の正規化定数を必要としないことです。ただしTを大きくとる必要があります。

最初のS個を捨てることをバーンインといいます。目的は平衡分布への収束を待つためです。MCMC法はメトロポリス・ヘイスティング法(推移確率を、提案分布Qと採択確率Aの積に分解します。Aは目標分布p(x)と提案分布Qに基づいて決定されます)とギブスサンプリング(確率変数を逐次的に条件付き分布に従ってサンプリングする方法で、高次元分布のサンプリングでよく用いられます)があります。
メトロポリス・ヘイスティング法はx_tを用いて自由に提案されたQ(x_(n+1)|x_t)に基づいて新しい候補点x_(n+1)を作成し、現在のx_nと比較して遷移させるかを決定します。採択確率Aに対して以下のように推移確率を設定します。
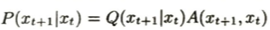
このときの採択確率は以下のようにすれば良いです。これは詳細釣合い条件から考えられます。
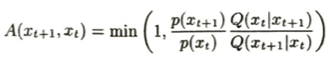
詳細釣合い条件とは以下のものです。

連続の場合も証明しておきます。
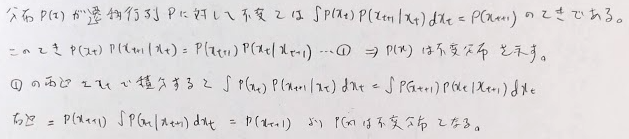
この確率によって採用されなかった場合はx_(n+1)=x_nとなり推移されません。提案分布Qの選び方はサンプリング効率に影響します。

メトロポリス・ヘイスティング法の例題を考えます




ギブスサンプリングは、多次元分布において効果を発揮します。(d)はd成分という意味です。

ギブスサンプリングの具体的な例題を考えます





ベイズ推定において事後確率分布が推論の基礎になります。事後確率分布は分母の計算に積分を必要とします。これは正規化定数や基準化定数といわれます。高次元の積分にはモンテカルロ積分が使用されます。
期待値計算では円や球の外側の標本は使用されません。球の次元が大きくなると乱数のほとんどは使用されなくなります。実際に正方形と単位円を考えて点を落としていく方法よりもπを求める際に積分計算結果を考えることにより、1という確率密度関数(そのため疑似乱数は標準一様分布(積分区間が0から1のときに確率密度が1になるから)を考えます)を被積分関数という重みで積分する(期待値計算)を考えることにより、疑似乱数によって被積分関数の値を計算して平均したものが近似値となる考えがあります。これをモンテカルロ積分といいます。
モンテカルロ積分の効率を評価する際に一般的に用いられる指標は推定量の分散です。モンテカルロ積分の基本的な考え方は独立同分布に従う確率変数列X_kに対して大数の強法則が成立することに基づいています。
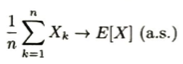
この収束の速度を議論する際に2次モーメントが存在することを仮定した上で中心極限定理(CLT)における分散が小さいほど近似の精度が高くなります。
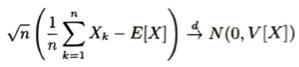
モンテカルロ積分についての例題を考えます


分散減少法とは期待値を保ったまま分散を減少させることです。代表的な方法として制御変量法、層別サンプリング法、重点サンプリング法、負相関変量法があります。
制御変量法はモンテカルロ積分において、期待値が0であり元の推定量と相関のある確率変数を加えることで分散を減少させる方法です。先程のπの記事の問題ではストレートに考えるならばU_kというU(0,1)という一様分布から取った確率変数列を用いて、非積分関数のxをU_kに置き換えたものの平均値を考えればそれが期待値に強収束します。分散を減らすために、例えばU_k-1/2を考えると期待値が0であるので、パラメータθをかけたものを加えて改めて推定量を考えます。このパラメータを分散が最小となるように最適化します。
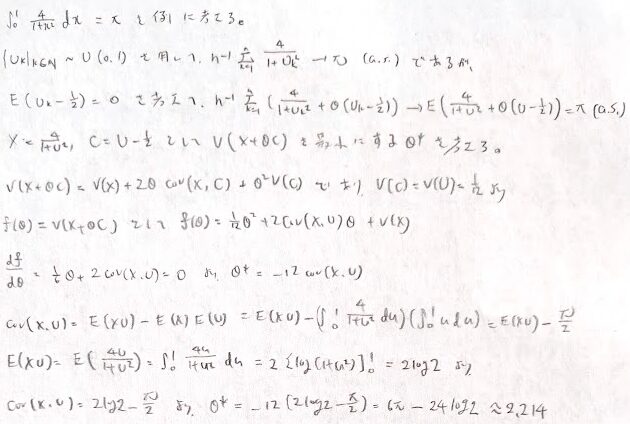
このようにして分散を最小化するパラメータθを最適化することができます。このときCLTに基づいて小さい分散の下でより効率的なモンテカルロ積分を求めることができます。CLTを持ち出す理由は得られた数値のもっともらしさを確率的に評価するためです。これは区間推定の考えです。

また教科書には書かれていませんが一般的に制御変量法において次のような関係式が得られます。これを証明しておきます。

層別サンプリング法について、今と同じようなπという結果を得るような積分を考えます。一様分布の台(0,1)を等確率の2つの区間(0,1/2),(1/2,1)に分割して、それぞれにおいていっせーのせに従う確率変数列V_k , W_kを考えます。このときに期待値について次のように分解できます。
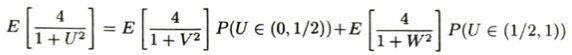
層別サンプリング法では、このように分割された各区間ごとに独立にサンプルを抽出し、サンプルサイズnをn_1 , n_2に分配することで、推定量の分散を減少させることを目的とします。
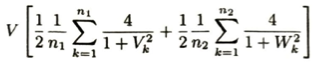
この分散を最小化するようなサンプルサイズn_1とn_2をラグランジュの未定乗数法により導出することで、より効率的なモンテカルロ積分が実現されます。
ベイズ統計の事後分布の文脈で重点サンプリングを考えます。
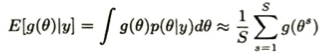
しかしサンプリングが容易でない場合もあります。事後分布における分母の計算が困難なためです。そこで分母の計算を回避して、p(θ|y)からサンプリングが得られることが望ましいです。事後分布の非正規化確率密度をq(θ|y)とおきます。

統計検定準1級でも登場しましたがとても技巧的ですね!
.jpg)
先ほどの式の意味について少し追加しておきます。つまり重点サンプリング法の名前の由来についてです。

重点サンプリング法とは積分近似のことで、それに伴うサンプリングのことを重点サンプリング再サンプリング法といいます。これは復元抽出です。
例えばΓ(2,2)に従う乱数を重点サンプリング法で生成することを考えます。x~U[0,6]として大きなサンプル数Nを取ります。重点重みをガンマ分布の形から逆算してx^(2-1)e^(-2x)としてM個ののUMVUEを抽出します。このとき再抽出されたM個の標本の平均は1で分散は0.5となっています。
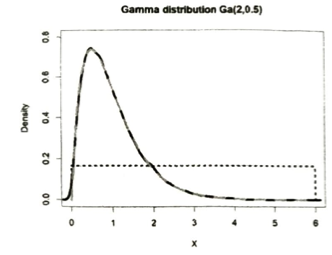
今回は上図のように一様分布という平らな板からガンマ分布という山の形を吉出しているイメージです。復元抽出によって選ばれたサンプルxを積み重ねていくと山になります。これが上の図のイメージの本質部分です。
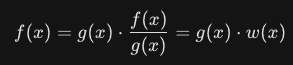


N個の標本からM個の標本を選ぶ大まかな流れを教えてください。
教科書には書いていませんが次のような過程をたどります。

具体的にどうやってM個を選び直すのですか?
次のように考えます。




本記事の最後に欠測値の扱いを考えます。不完全データでは複雑な非線形モデルによる解析が必要ですが、完全データなら解析がより簡単になる場合があります。
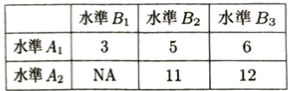
繰り返しのない二元配置分散分析モデルを適用して行と列の要因効果を推定します。まずNAに観測データの平均値を入れてパラメータの推定値が得ます。
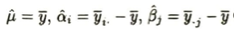
そして欠測値を次のように更新します。
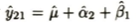
この左辺が変わらなくなるまで計算を繰り返します。次に明確な欠測値とはなっていませんが欠測値として扱うと便利な場合を考えます。n次元ベクトルyがK種類の混合分布から独立に選ばれた標本とします。
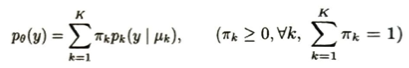
θはパラメータであり、中身はK個のπとK個のμです。最尤法によって推定できますが複雑で計算が難しいです。
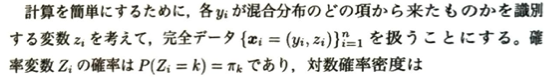
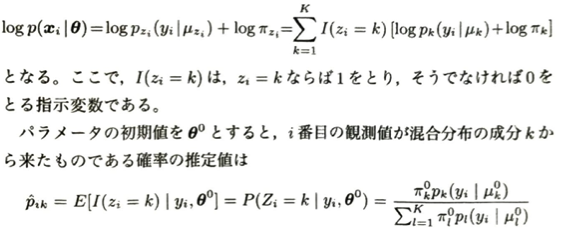

この内容は本記事のまとめとして難易度が高いEMアルゴリズムです。Eは期待値、Mは最大化を意味します。これは不完全データに対して欠測値を奉還した完全データを考えることにより、計算を簡略化してパラメータ推定を行うことです。この際に目的となる尤度関数は必ず増加します。しかしEMアルゴリズムは収束が遅いデメリットがあります。
最後にEMアルゴリズムの具体的な例題を考えます





データサイエンスエキスパートの合格記事は下記になります!


{kind=link}